I am trying to use forkserver and I encountered NameError: name 'xxx' is not defined in worker processes.
I am using Python 3.6.4, but the documentation should be the same, from https://docs.python.org/3/library/multiprocessing.html#contexts-and-start-methods it says that:
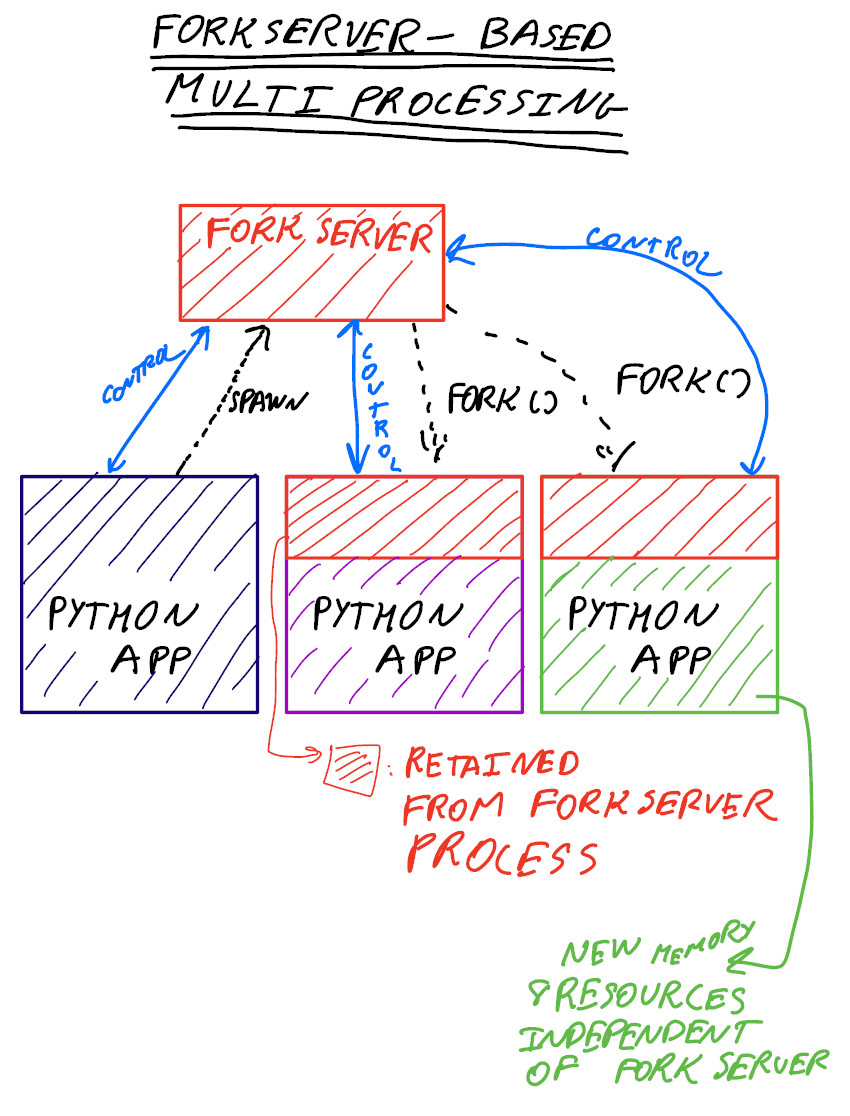
The fork server process is single threaded so it is safe for it to use os.fork(). No unnecessary resources are inherited.
Also, it says:
Better to inherit than pickle/unpickle
When using the spawn or forkserver start methods many types from multiprocessing need to be picklable so that child processes can use them. However, one should generally avoid sending shared objects to other processes using pipes or queues. Instead you should arrange the program so that a process which needs access to a shared resource created elsewhere can inherit it from an ancestor process.
So apparently a key object that my worker process needs to work on did not get inherited by the server process and then passing to workers, why did that happen? I wonder what exactly gets inherited by forkserver process from parent process?
Here is what my code looks like:
import multiprocessing
import (a bunch of other modules)
def worker_func(nameList):
global largeObject
for item in nameList:
# get some info from largeObject using item as index
# do some calculation
return [item, info]
if __name__ == '__main__':
result = []
largeObject # This is my large object, it's read-only and no modification will be made to it.
nameList # Here is a list variable that I will need to get info for each item in it from the largeObject
ctx_in_main = multiprocessing.get_context('forkserver')
print('Start parallel, using forking/spawning/?:', ctx_in_main.get_context())
cores = ctx_in_main.cpu_count()
with ctx_in_main.Pool(processes=4) as pool:
for x in pool.imap_unordered(worker_func, nameList):
result.append(x)
Thank you!
Best,
nameListto say 4 chunks and use zip([largeObject]*4, nameLis_splittedt) inimap_unorderedand unwrap it later inworker_func(), this way it did getlargeObjectinto workers, but it becomes super slow. I am guessing it's due tolargeObject's size. – EcumenicismlargeObjecthere is aNetworkXobject which came from a series of previous calculations in__main__that involves reading large pandas df and other memory consuming operations. – Ecumenicism