At dawn my code was working perfectly, but today when I woke up it is no longer working, and I didn't change any line of code, I also checked if Firefox updated, and no, it didn't, and I have no idea what maybe, I've been reading the urllib documentation but I couldn't find any information
from asyncio.windows_events import NULL
from ctypes.wintypes import PINT
from logging import root
from socket import timeout
from string import whitespace
from tkinter import N
from turtle import color
from urllib.request import Request
from hyperlink import URL
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support.expected_conditions import presence_of_element_located
#from webdriver_manager.firefox import GeckoDriverManager
import time
from datetime import datetime
import telebot
#driver = webdriver.Firefox(service=Service(GeckoDriverManager().install()))
colors = NULL
api = "******"
url = "https://blaze.com/pt/games/double"
bot = telebot.TeleBot(api)
chat_id = "*****"
firefox_driver_path = "/Users/Antônio/Desktop/roletarobo/geckodriver.exe"
firefox_options = Options()
firefox_options.add_argument("--headless")
webdriver = webdriver.Firefox(
executable_path = firefox_driver_path,
options = firefox_options)
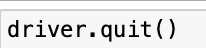
with webdriver as driver:
driver.get(url)
wait = WebDriverWait(driver, 25)
wait.until(presence_of_element_located((By.CSS_SELECTOR, "div#roulette.page.complete")))
time.sleep(2)
results = driver.find_elements(By.CSS_SELECTOR, "div#roulette-recent div.entry")
for quote in results:
quote.text.split('\n')
data = [my_elem.text for my_elem in driver.find_elements(By.CSS_SELECTOR, "div#roulette-recent div.entry")][:8]
#método convertElements, converte elementos da lista em elementos declarados
def convertElements( oldlist, convert_dict ):
newlist = []
for e in oldlist:
if e in convert_dict:
newlist.append(convert_dict[e])
else:
newlist.append(e)
return newlist
#fim do método
colors = convertElements(data, {'':"white",'1':"red",'2':"red",'3':"red",'4':"red",'5':"red",'6':"red",'7':"red",'8':"black",'9':"black",'10':"black",'11':"black",'12':"black",'13':"black",'14':"black"})
print(colors)
It was working perfectly, since Sunday I've been coding and it's always been working
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\support\wait.py", line 78, in until
value = method(self._driver)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\support\expected_conditions.py", line 64, in _predicate
return driver.find_element(*locator)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 1248, in find_element
return self.execute(Command.FIND_ELEMENT, {
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\remote\webdriver.py", line 423, in execute
response = self.command_executor.execute(driver_command, params)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\remote\remote_connection.py", line 333, in execute
return self._request(command_info[0], url, body=data)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\selenium\webdriver\remote\remote_connection.py", line 355, in _request
resp = self._conn.request(method, url, body=body, headers=headers)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\request.py", line 78, in request
return self.request_encode_body(
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\request.py", line 170, in request_encode_body
return self.urlopen(method, url, **extra_kw)
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py", line 813, in urlopen
return self.urlopen(
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\connectionpool.py", line 785, in urlopen retries = retries.increment(
File "C:\Users\Antônio\AppData\Local\Programs\Python\Python310\lib\site-packages\urllib3\util\retry.py", line 592, in increment raise MaxRetryError(_pool, url, error or ResponseError(cause))urllib3.exceptions.MaxRetryError: HTTPConnectionPool(host='localhost', port=59587): Max retries exceeded with url: /session/b38be2fe-6d92-464f-a096-c43183aef6a8/element (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x00000173145EF520>: Failed to establish a new connection: [WinError 10061] No connections could be made because the target machine actively refused them'))
{kind=link}