I want it to produce the number next to a word so that I can ask the user to select the word by using the corresponding number.
This is my code
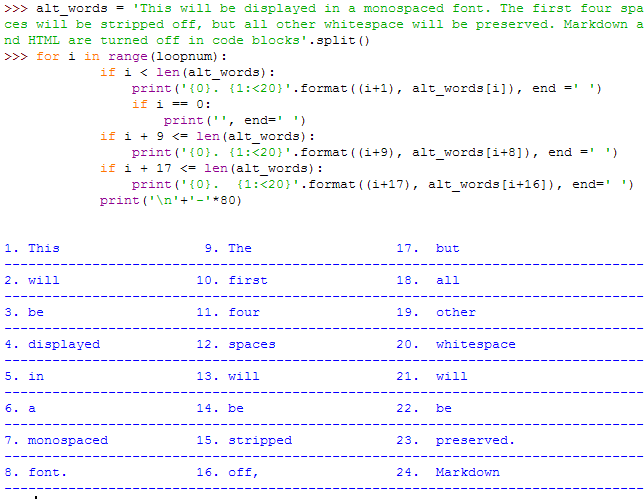
alt_words = hlst
loopnum = 8
for i in range(loopnum):
if i < len(alt_words):
print('{0}. {1:<20}'.format((i+1), alt_words[i]), end =' ')
if i == 0:
print('', end=' ')
if i + 9 <= len(alt_words):
print('{0}. {1:<20}'.format((i+9), alt_words[i+8]), end =' ')
if i + 17 <= len(alt_words):
print('{0}. {1:<20}'.format((i+17), alt_words[i+16]), end=' ')
print('\n'+'-'*80)
It produces this

The first number of each line gets printed on the left, but the word on the right, while the rest of the numbers and words get printed RTL. It seems that once python has started printing on a line LTR it can switch to RTL, but not back from RTL to LTR. Note how even the periods are printed to the right of the number for the second set of numbers on each line.
It works perfectly well and looks nice with english words:
I am guessing a work around might involve putting the number after the word, but I figure there must be a better way.