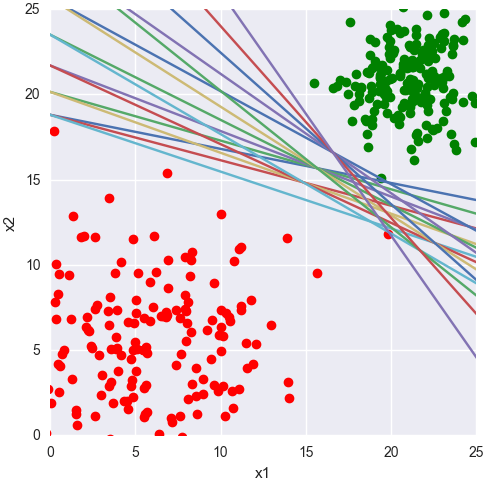
It's probably easier to explain if you look deeper into the math. Basically what a single layer of a neural net is performing some function on your input vector transforming it into a different vector space.
You don't want to jump right into thinking of this in 3-dimensions. Start smaller, it's easy to make diagrams in 1-2 dimensions, and nearly impossible to draw anything worthwhile in 3 dimensions (unless you're a brilliant artist), and being able to sketch this stuff out is invaluable.
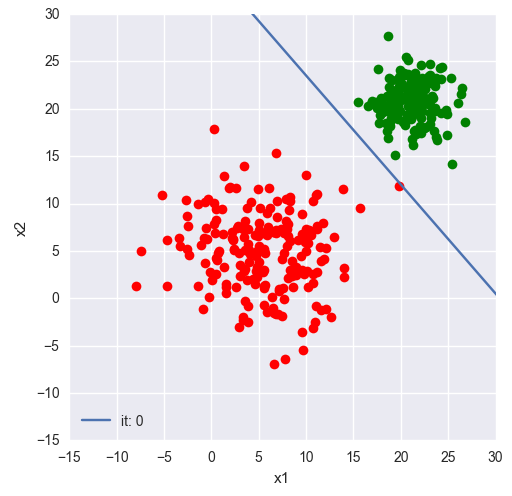
Let's take the simplest case, where you're taking in an input vector of length 2, you have a weight vector of dimension 2x1, which implies an output vector of length one (effectively a scalar)
In this case it's pretty easy to imagine that you've got something of the form:
input = [x, y]
weight = [a, b]
output = ax + by
If we assume that weight = [1, 3], we can see, and hopefully intuit that the response of our perceptron will be something like this:
![enter image description here]()
With the behavior being largely unchanged for different values of the weight vector.
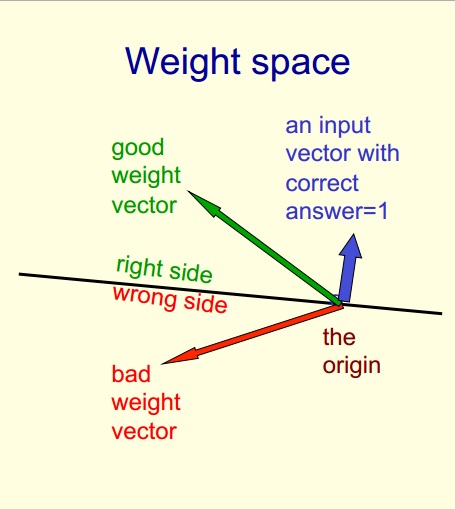
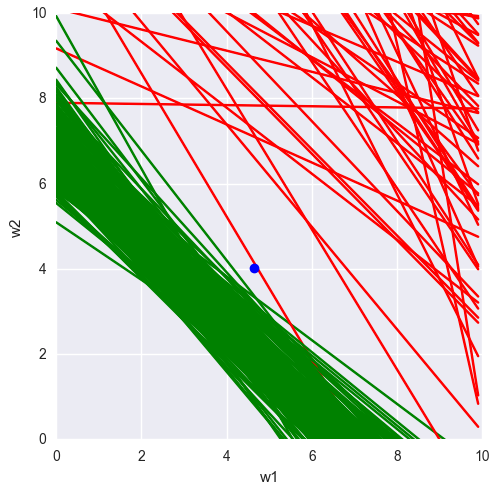
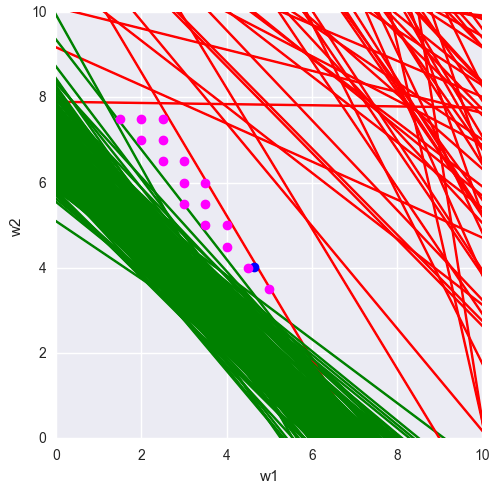
It's easy to imagine then, that if you're constraining your output to a binary space, there is a plane, maybe 0.5 units above the one shown above that constitutes your "decision boundary".
As you move into higher dimensions this becomes harder and harder to visualize, but if you imagine that that plane shown isn't merely a 2-d plane, but an n-d plane or a hyperplane, you can imagine that this same process happens.
Since actually creating the hyperplane requires either the input or output to be fixed, you can think of giving your perceptron a single training value as creating a "fixed" [x,y] value. This can be used to create a hyperplane. Sadly, this cannot be effectively be visualized as 4-d drawings are not really feasible in browser.
Hope that clears things up, let me know if you have more questions.