TL;DR: Using a LabelEncoder to encode ordinal any kind of features is a bad idea!
This is in fact clearly stated in the docs, where it is mentioned that as its name suggests this encoding method is aimed at encoding the label:
This transformer should be used to encode target values, i.e. y, and not the input X.
As you rightly point out in the question, mapping the inherent ordinality of an ordinal feature to a wrong scale will have a very negative impact on the performance of the model (that is, proportional to the relevance of the feature). And the same applies to a categorical feature, just that the original feature has no ordinality.
An intuitive way to think about it, is in the way a decision tree sets its boundaries. During training, a decision tree will learn the optimal features to set at each node, as well as an optimal threshold whereby unseen samples will follow a branch or another depending on these values.
If we encode an ordinal feature using a simple LabelEncoder, that could lead to a feature having say 1 represent warm, 2 which maybe would translate to hot, and a 0 representing boiling. In such case, the result will end up being a tree with an unnecessarily high amount of splits, and hence a much higher complexity for what should be simpler to model.
Instead, the right approach would be to use an OrdinalEncoder, and define the appropriate mapping schemes for the ordinal features. Or in the case of having a categorical feature, we should be looking at OneHotEncoder or the various encoders available in Category Encoders.
Though actually seeing why this is a bad idea will be more intuitive than just words.
Let's use a simple example to illustrate the above, consisting on two ordinal features containing a range with the amount of hours spend by a student preparing for an exam and the average grade of all previous assignments, and a target variable indicating whether the exam was past or not. I've defined the dataframe's columns as pd.Categorical:
df = pd.DataFrame(
{'Hours of dedication': pd.Categorical(
values = ['25-30', '20-25', '5-10', '5-10', '40-45',
'0-5', '15-20', '20-25', '30-35', '5-10',
'10-15', '45-50', '20-25'],
categories=['0-5', '5-10', '10-15', '15-20',
'20-25', '25-30','30-35','40-45', '45-50']),
'Assignments avg grade': pd.Categorical(
values = ['B', 'C', 'F', 'C', 'B',
'D', 'C', 'A', 'B', 'B',
'B', 'A', 'D'],
categories=['F', 'D', 'C', 'B','A']),
'Result': pd.Categorical(
values = ['Pass', 'Pass', 'Fail', 'Fail', 'Pass',
'Fail', 'Fail','Pass','Pass', 'Fail',
'Fail', 'Pass', 'Pass'],
categories=['Fail', 'Pass'])
}
)
The advantage of defining a categorical column as a pandas' categorical, is that we get to establish an order among its categories, as mentioned earlier. This allows for much faster sorting based on the established order rather than lexical sorting. And it can also be used as a simple way to get codes for the different categories according to their order.
So the dataframe we'll be using looks as follows:
print(df.head())
Hours_of_dedication Assignments_avg_grade Result
0 20-25 B Pass
1 20-25 C Pass
2 5-10 F Fail
3 5-10 C Fail
4 40-45 B Pass
5 0-5 D Fail
6 15-20 C Fail
7 20-25 A Pass
8 30-35 B Pass
9 5-10 B Fail
The corresponding category codes can be obtained with:
X = df.apply(lambda x: x.cat.codes)
X.head()
Hours_of_dedication Assignments_avg_grade Result
0 4 3 1
1 4 2 1
2 1 0 0
3 1 2 0
4 7 3 1
5 0 1 0
6 3 2 0
7 4 4 1
8 6 3 1
9 1 3 0
Now let's fit a DecisionTreeClassifier, and see what is how the tree has defined the splits:
from sklearn import tree
dt = tree.DecisionTreeClassifier()
y = X.pop('Result')
dt.fit(X, y)
We can visualise the tree structure using plot_tree:
t = tree.plot_tree(dt,
feature_names = X.columns,
class_names=["Fail", "Pass"],
filled = True,
label='all',
rounded=True)
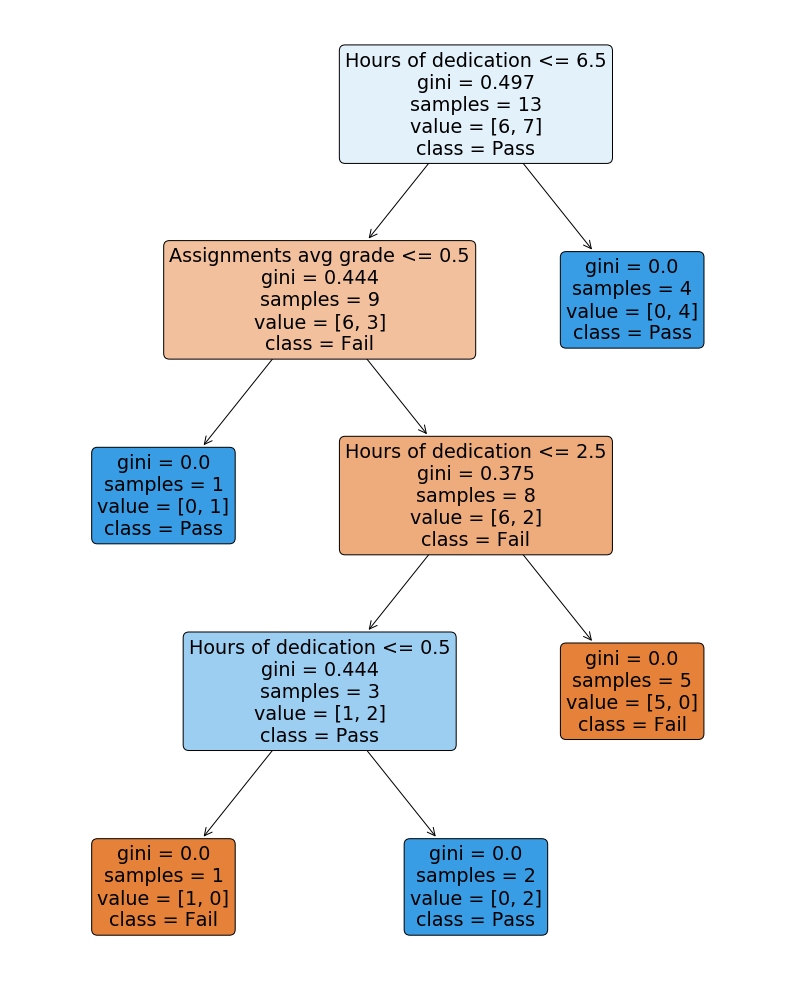
![enter image description here]()
Is that all?? Well… yes! I've actually set the features in such a way that there is this simple and obvious relation between the Hours of dedication feature, and whether the exam is passed or not, making it clear that the problem should be very easy to model.
Now let's try to do the same by directly encoding all features with an encoding scheme we could have obtained for instance through a LabelEncoder, so disregarding the actual ordinality of the features, and just assigning a value at random:
df_wrong = df.copy()
df_wrong['Hours_of_dedication'].cat.set_categories(
['0-5','40-45', '25-30', '10-15', '5-10', '45-50','15-20',
'20-25','30-35'], inplace=True)
df_wrong['Assignments_avg_grade'].cat.set_categories(
['A', 'C', 'F', 'D', 'B'], inplace=True)
rcParams['figure.figsize'] = 14,18
X_wrong = df_wrong.drop(['Result'],1).apply(lambda x: x.cat.codes)
y = df_wrong.Result
dt_wrong = tree.DecisionTreeClassifier()
dt_wrong.fit(X_wrong, y)
t = tree.plot_tree(dt_wrong,
feature_names = X_wrong.columns,
class_names=["Fail", "Pass"],
filled = True,
label='all',
rounded=True)
![enter image description here]()
As expected the tree structure is way more complex than necessary for the simple problem we're trying to model. In order for the tree to correctly predict all training samples it has expanded until a depth of 4, when a single node should suffice.
This will imply that the classifier is likely to overfit, since we’re drastically increasing the complexity. And by pruning the tree and tuning the necessary parameters to prevent overfitting we are not solving the problem either, since we’ve added too much noise by wrongly encoding the features.
So to summarize, preserving the ordinality of the features once encoding them is crucial, otherwise as made clear with this example we'll lose all their predictable power and just add noise to our model.