I'm getting the problem of non-converged training loss. (batchsize: 16, average loss:10). I have tried with the following methods + Vary the learning rate lr (initial lr = 0.002 cause very high loss, around e+10). Then with lr = e-6, the loss seem to small but do not converge. + Add initialization for bias + Add regularization for bias and weight
This is the network structure and the training loss log
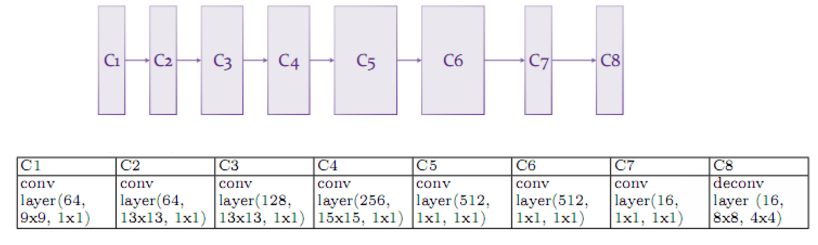{kind=link}
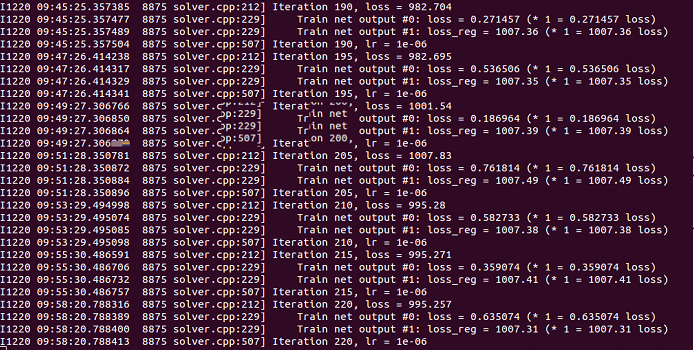{kind=link}
Hope to hear from you Best regards
debug_info: truein your'solver.prototxt'and use these guidelines to see what is interfering with the training. – Caressa