If you know that the site you're trying to get is a "good guy", you can try creating your "opener" like this:
import httplib2
if __name__ == "__main__":
h = httplib2.Http(".cache", disable_ssl_certificate_validation=True)
resp, content = h.request("https://site/whose/certificate/is/bad/", "GET")
(the interesting part is disable_ssl_certificate_validation=True )
From the docs:
http://bitworking.org/projects/httplib2/doc/html/libhttplib2.html#httplib2.Http
EDIT 01:
Since your question was actually why does this happen, you can check this or this.
EDIT 02:
Seeing how this answer has been visited by more people than I expected, I'd like to explain a bit when disabling certificate validation could be useful.
First, a bit of light background on how these certificates work. There's quite a lot of information in the links provided above, but here it goes, anyway.
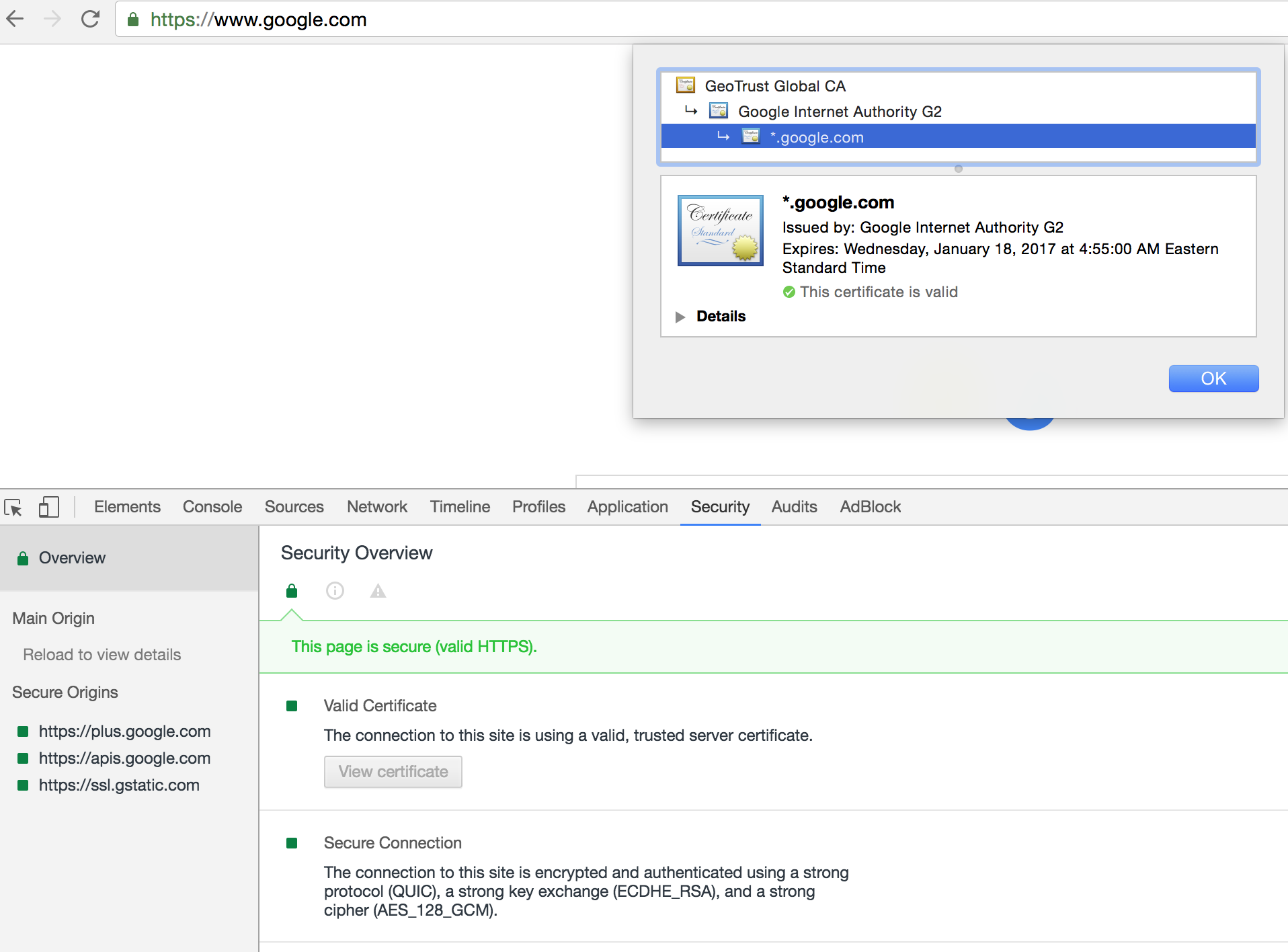
The SSL certificates need to be verified by a well known (at least, well known to your browser) Certificate Authority. You usually buy the whole certificate from one of those authorities (Symantec, GoDaddy...)
Broadly speaking, the idea is: Those Certificate Authorities (CA) give you a certificate that also contains the CA information in it. Your browsers have a list of well known CAs, so when your browser receives a certificate, it will do something like: "HmmmMMMmmm.... [the browser makes a supiciuous face here] ... I received a certificate, and it says it's verified by Symantec. Do I know that "Symantec" guy? [the browser then goes to its list of well known CAs and checks for Symantec] Oh, yeah! I do. Ok, the certificate is good!
You can see that information yourself if you click on the little lock by the URL in your browser:
![Chrome certificate information]()
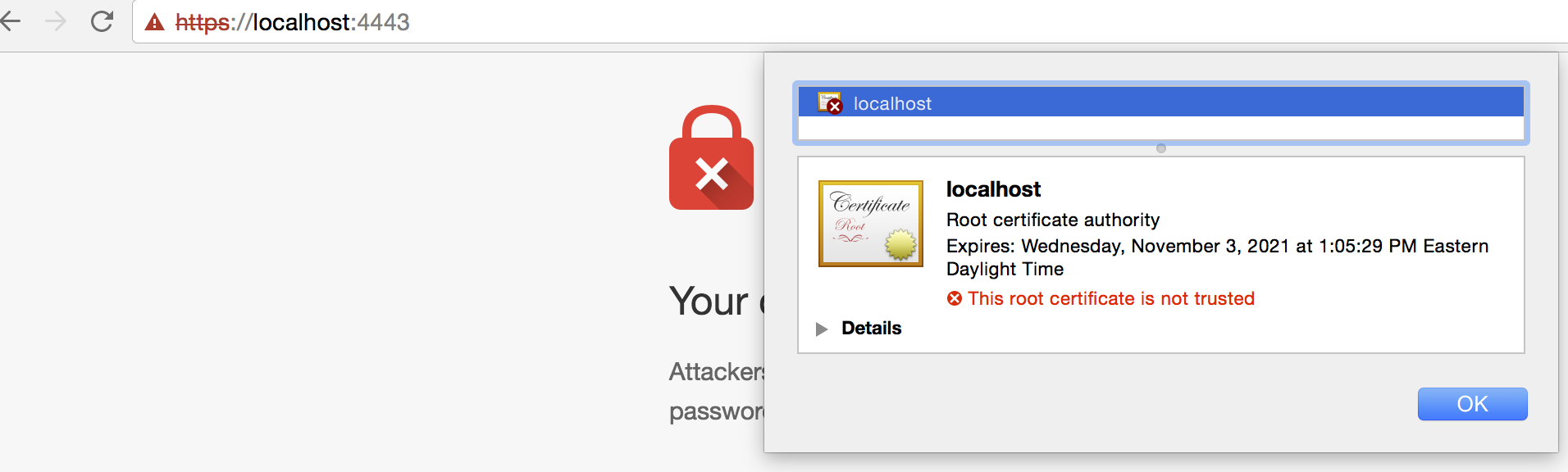
However, there are cases in which you just want to test the HTTPS, and you create your own Certificate Authority using a couple of command line tools and you use that "custom" CA to sign a "custom" certificate that you just generated as well, right? In that case, your browser (which, by the way, in the question is httplib2.Http) is not going to have your "custom" CA among the list of trusted CAs, so it's going to say that the certificate is invalid. The information is still going to travel encrypted, but what the browser is telling you is that it doesn't fully trust that is traveling encrypted to the place you are supposing it's going.
For instance, let's say you created a set of custom keys and CAs and all the mambo-jumbo following this tutorial for your localhost FQDN and that your CA certificate file is located in the current directory. You could very well have a server running on https://localhost:4443 using your custom certificates and whatnot. Now, your CA certificate file is located in the current directory, in the file ./ca.crt (in the same directory your Python script is going to be running in). You could use httplib2 like this:
h = httplib2.Http(ca_certs='./ca.crt')
response, body = h.request('https://localhost:4443')
print(response)
print(body)
... and you wouldn't see the warning anymore. Why? Because you told httplib2 to go look for the CA's certificate to ./ca.crt)
However, since Chrome (to cite a browser) doesn't know about this CA's certificate, it will consider it invalid:
![enter image description here]()
Also, certificates expire. There's a chance you are working in a company which uses an internal site with SSL encryption. It works ok for a year, and then your browser starts complaining. You go to the person that is in charge of the security, and ask "Yo!! I get this warning here! What's happening?" And the answer could very well be "Oh boy!! I forgot to renew the certificate! It's ok, just accept it from now, until I fix that." (true story, although there were swearwords in the answer I received :-D )