I will be inserting names of files in a dynamically way, approximately till 1 billion of names. Besides, I do also want to store the path where the files are located in order to do the following queries:
- Searching wheter the name of a file is stored in order to get its path.
- Searching the name of all the files which matches with a substring, a kinda of a like-query (e.g. If a search *o*, it will return me joel, hola, ola, oso, osea, algo, if a search aa*, it will return me aaab and if I search *so, It will return oso).
- Delete the name of a file.
So, I am trying to make a kind of trie data structure in the following way:
I got 26 nodes (the english alphabet a-z, I am not going to put all the nodes in the image because space) such that if I insert the word "hola" then I create an edge from node with the letter 'h' to node with the letter 'o' and whose edge has a data 1 since this number represent the level of the depth. Furthermore, in the node where 'a' is stored, I will have a map structure in order to store the path of the file, this is because I will surely have a lot of paths stored in the node which contains the letter 'a'.
Having said that, I inserted the following words: joel, hola, ola, oso, osea, algo, aaab.
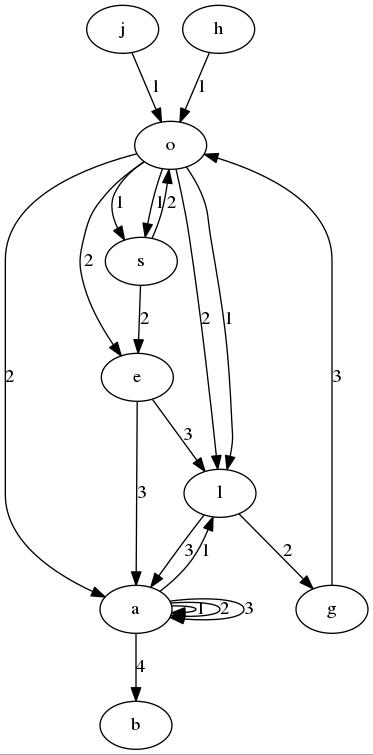
I have done so because I do not want to have many nodes with the sama lettres (e.g. a, b, etc) but the problem is that I got a lot of edges and the sctructure needs
bytes of memory (I am programming in C++) where w is a string of size .
As you can see, if I search for the name of file "jola" (which is not inserted) no path will returned and this tell us that such file is not stored.
How can I improve this? Is it any way to reduce the number of edges? or there exists a better structure and way to do this? I am very open to hear of any suggestion.