I can make a neural network, I just need a clarification on bias implementation. Which way is better: Implement the Bias matrices B1, B2, .. Bn for each layer in their own, seperate matrix from the weight matrix, or, include the biases in the weight matrix by adding a 1 to the previous layer output (input for this layer). In images, I am asking whether this implementation:
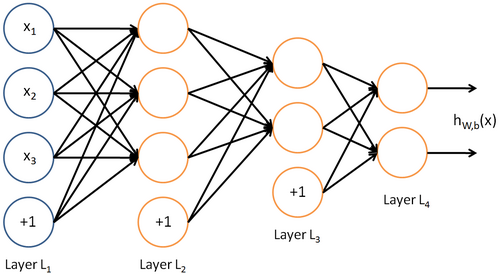
Or this implementation:
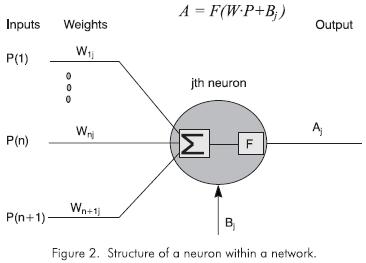
Is the best. Thank you
1s but in his 2016 course he has them separate. I assuming that it is more performent to keep them separate as matrix-multiplication is worse than quadratic time. I'm not sure if that changes when you have GPUs. You could try look into the source code for popular libraries and see how they're doing it. – AmpereM * M x Nshould readN * N x Min the comment above. – Jael