I wrote you a full benchmark, using a trivial Flask application backed by gUnicorn/meinheld + nginx (for performance and HTTPS), and seeing how long it takes to complete 10,000 requests. Tests are run in AWS on a pair of unloaded c4.large instances, and the server instance was not CPU-limited.
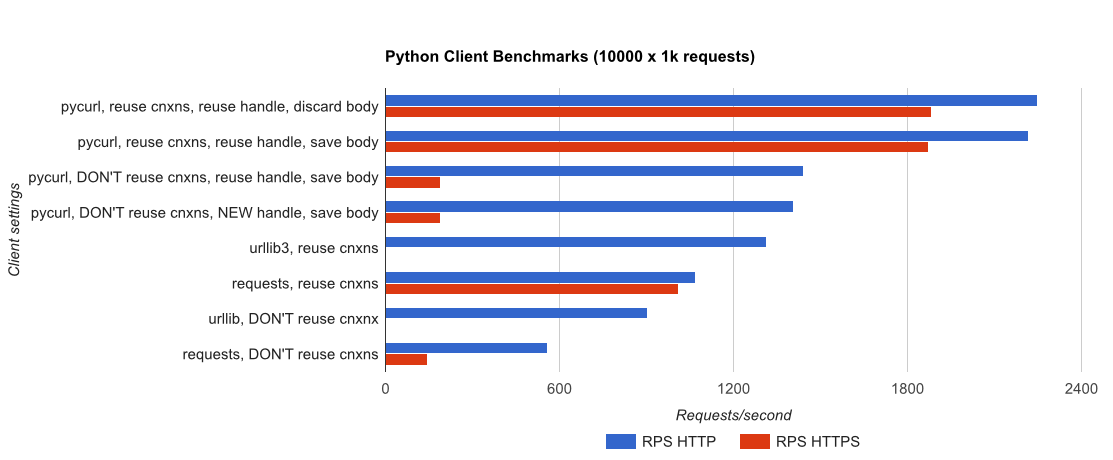
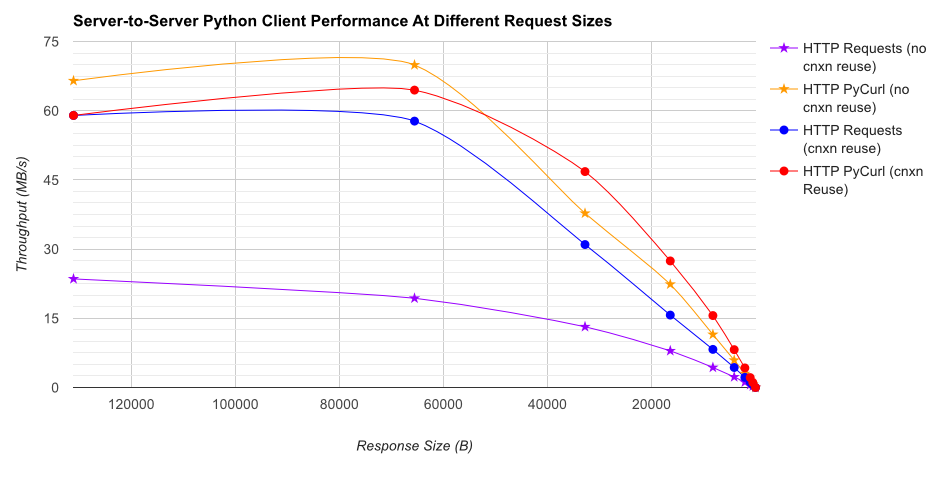
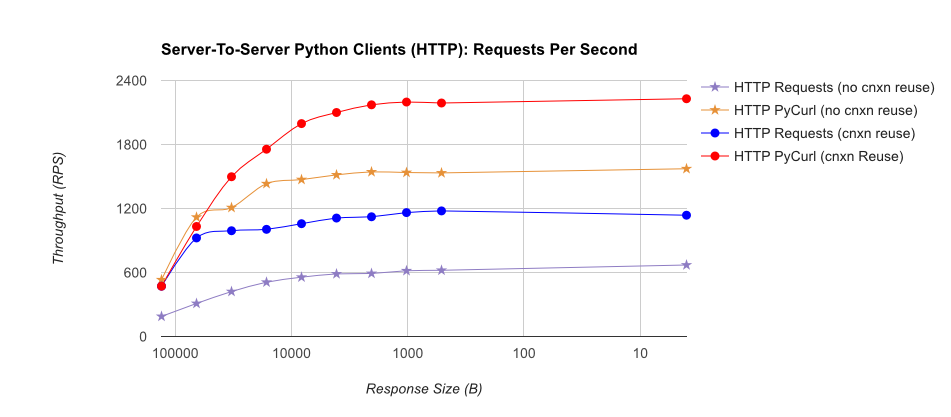
TL;DR summary: if you're doing a lot of networking, use PyCurl, otherwise use requests. PyCurl finishes small requests 2x-3x as fast as requests until you hit the bandwidth limit with large requests (around 520 MBit or 65 MB/s here), and uses from 3x to 10x less CPU power. These figures compare cases where connection pooling behavior is the same; by default, PyCurl uses connection pooling and DNS caches, where requests does not, so a naive implementation will be 10x as slow.
![Combined-chart-RPS]()
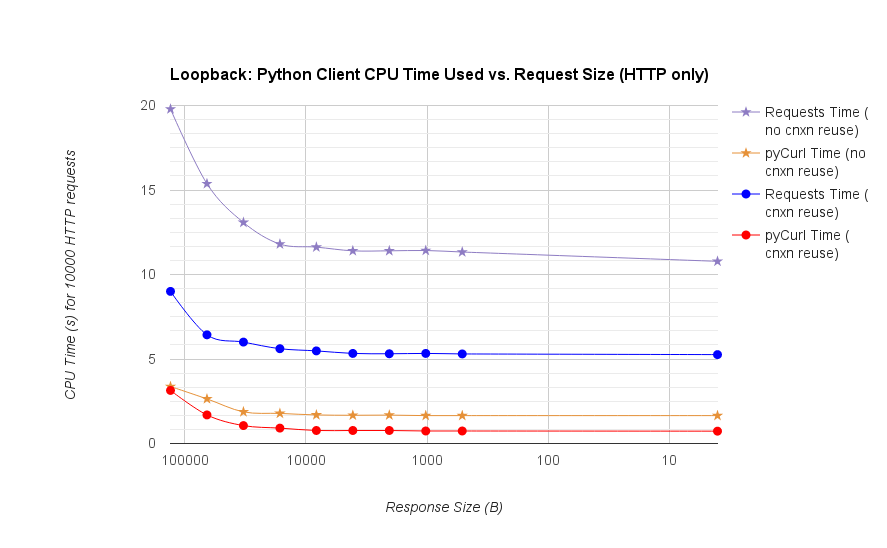
![CPU Time by request size detailed]()
![Just HTTP throughput]()
![Just HTTP RPS]()
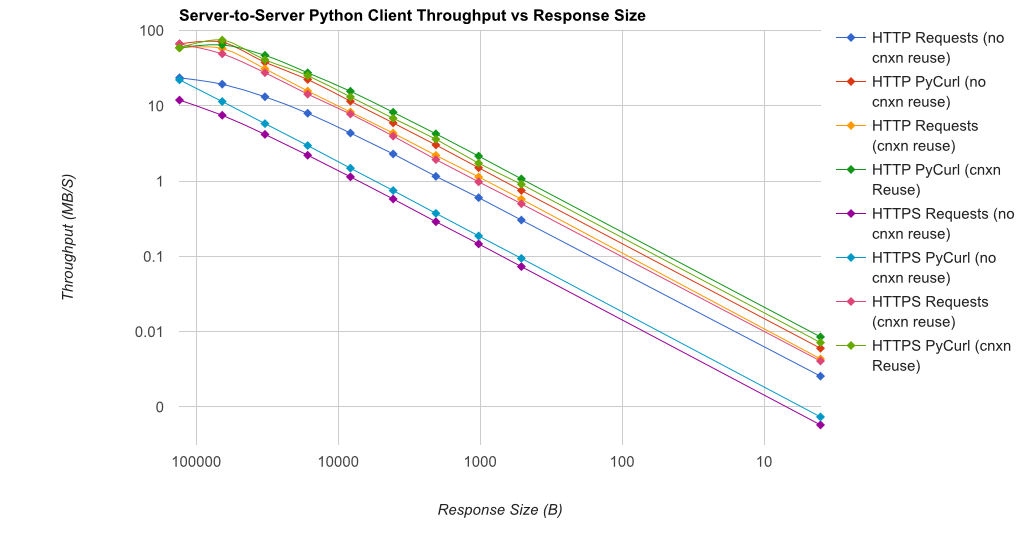
Note that double log plots are used for the below graph only, due to the orders of magnitude involved
![HTTP & HTTPS throughput]()
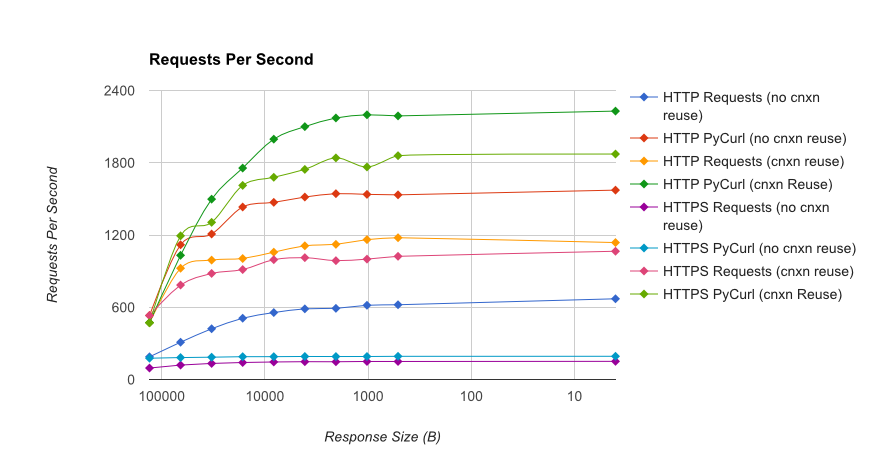
![HTTP & HTTPS RPS]()
- pycurl takes about 73 CPU-microseconds to issue a request when reusing a connection
- requests takes about 526 CPU-microseconds to issue a request when reusing a connection
- pycurl takes about 165 CPU-microseconds to open a new connection and issue a request (no connection reuse), or ~92 microseconds to open
- requests takes about 1078 CPU-microseconds to open a new connection and issue a request (no connection reuse), or ~552 microseconds to open
Full results are in the link, along with the benchmark methodology and system configuration.
Caveats: although I've taken pains to ensure the results are collected in a scientific way, it's only testing one system type and one operating system, and a limited subset of performance and especially HTTPS options.
pongis not realistic), and including a mix of content-encoding modes (with and without compression), and then produce timings based on that, then you'd have benchmark data with actual meaning. – Coenurus