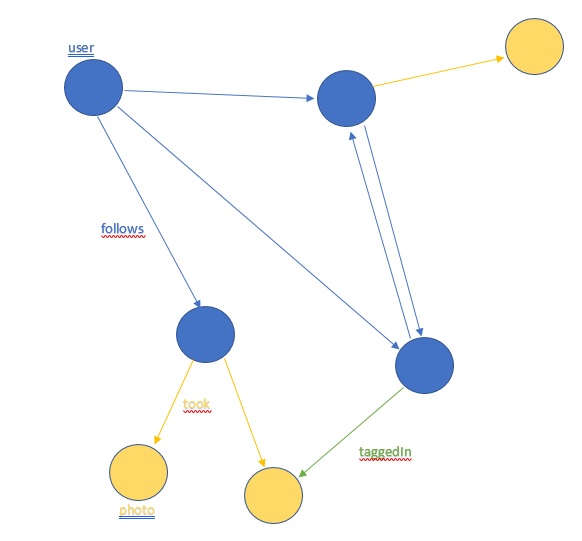
Imagine a social network app. Users follow other users and users take photos. Photos have tags of other users.
I'm trying to get an effective Cosmos db implementation of a graph for that app. I provide an SQL Server version as well as a benchmark.
Here is the graph:
Here is a table version of it:

Here is the Gremlin query:
g.V('c39f435b-350e-4d08-a7b6-dfcadbe4e9c5')
.out('follows').as('name')
.out('took').order(local).by('postedAt', decr).as('id', 'postedAt')
.select('id', 'name', 'postedAt').by(id).by('name').by('postedAt')
.limit(10)
Here is the equivalent SQL query (linq actually):
Follows
.Where(f => f.FollowerId == "c39f435b-350e-4d08-a7b6-dfcadbe4e9c5")
.Select(f => f.Followees)
.SelectMany(f => f.Photos)
.OrderByDescending(f => f.PostedAt)
.Select(f => new { f.User.Name, f.Id, f.PostedAt})
.Take(10)
That user follows 136 users who collectively took 257 photos.
Both SQL Server and Cosmos db are in West Europe Azure location. I'm in France. I did a bit of testing on Linpad.
- The Gremlin Query runs in over 1.20s and consumes about 330 RU. FYI, 400RU/s costs 20$/month.
- The SQL query runs in 70ms. The db is 10 DTU (1 instance of S0). So it costs 12.65eur / month
How can I get the feed faster and cheaper with cosmos db?
Note: In order to get the RU charged, I'm using Microsoft.Azure.Graph. But I can also use Gremlin.Net and get similar results.