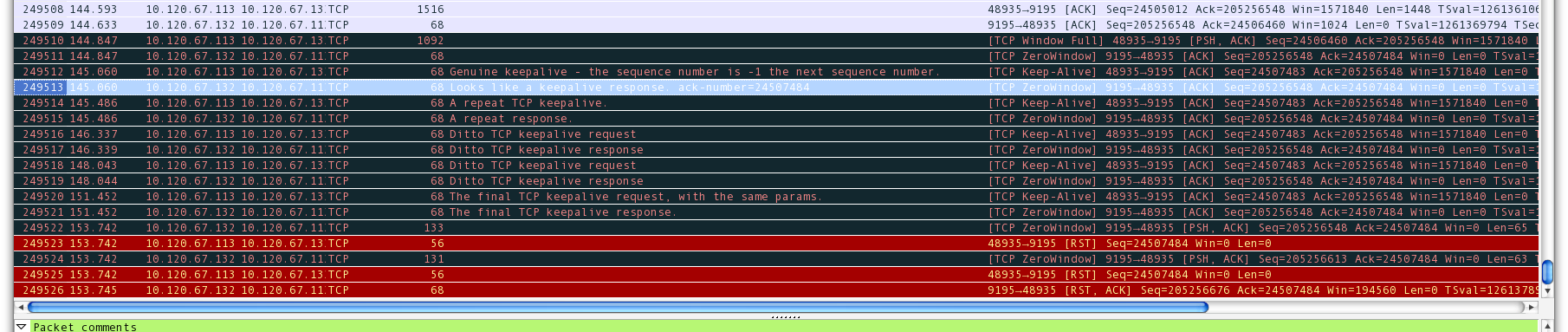
We're seeing this pattern happen a lot between two RHEL 6 boxes that are transferring data via a TCP connection. The client issues a TCP Window Full, 0.2s later the client sends TCP Keep-Alives, to which the server responds with what look like correctly shaped responses. The client is unsatisfied by this however and continues sending TCP Keep-Alives until it finally closes the connection with an RST nearly 9s later.
This is despite the RHEL boxes having the default TCP Keep-Alive configuration:
net.ipv4.tcp_keepalive_time = 7200
net.ipv4.tcp_keepalive_probes = 9
net.ipv4.tcp_keepalive_intvl = 75
...which declares that this should only occur until 2hrs of silence. Am I reading my PCAP wrong (relevant packets available on request)?
Below is Wireshark screenshot of the pattern, with my own packet notes in the middle.