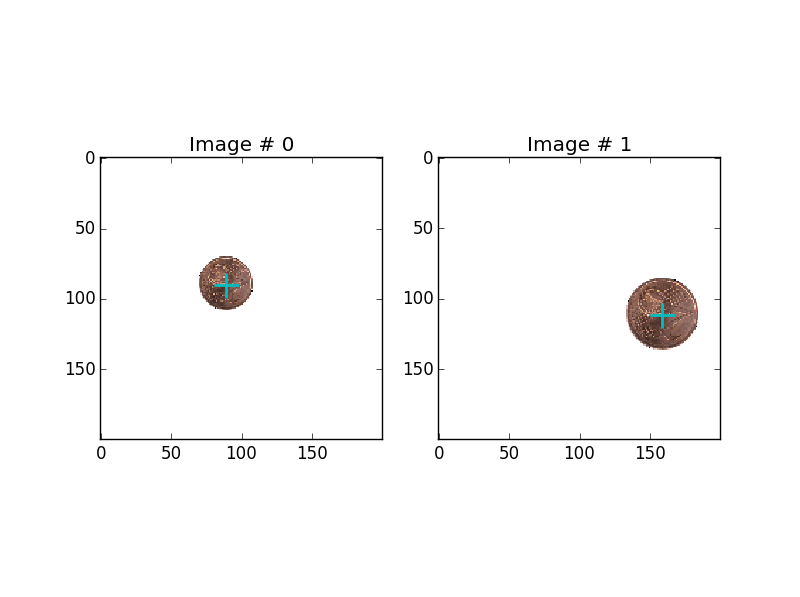
I generate images of a single coin pasted over a white background of size 200x200. The coin is randomly chosen among 8 euro coin images (one for each coin) and has :
- random rotation ;
- random size (bewteen fixed bounds) ;
- random position (so that the coin is not cropped).
Here are two examples (center markers added): Two dataset examples
{kind=link}
I am using Python + Lasagne. I feed the color image into the neural network that has an output layer of 2 linear neurons fully connected, one for x and one for y. The targets associated to the generated coin images are the coordinates (x,y) of the coin center.
I have tried (from Using convolutional neural nets to detect facial keypoints tutorial):
- Dense layer architecture with various number of layers and number of units (500 max) ;
- Convolution architecture (with 2 dense layers before output) ;
- Sum or mean of squared difference (MSE) as loss function ;
- Target coordinates in the original range [0,199] or normalized [0,1] ;
- Dropout layers between layers, with dropout probability of 0.2.
I always used simple SGD, tuning the learning rate trying to have a nice decreasing error curve.
I found that as I train the network, the error decreases until a point where the output is always the center of the image. It looks like the output is independent of the input. It seems that the network output is the average of the targets I give. This behavior looks like a simple minimization of the error since the positions of the coins are uniformly distributed on the image. This is not the wanted behavior.
I have the feeling that the network is not learning but is just trying to optimize the output coordinates to minimize the mean error against the targets. Am I right? How can I prevent this? I tried to remove the bias of the output neurons because I thought maybe I'm just modifying the bias and all others parameters are being set to zero but this didn't work.
Is it possible for a neural network alone to perform well at this task? I have read that one can also train a net for present/not present binary classification and then scan the image to find possible locations of objects. But I just wondered if it was possible just using the forward computation of a neural net.