in my previous question on finding a reference audio sample in a bigger audio sample, it was proposed, that I should use convolution.
Using DSPUtil, I was able to do this. I played a little with it and tried different combinations of audio samples, to see what the result was. To visualize the data, I just dumped the raw audio as numbers to Excel and created a chart using this numbers. A peak is visible, but I don't really know how this helps me. I have these problems:
- I don't know, how to infer the starting position of the match in the original audio sample from the location of the peak.
- I don't know, how I should apply this with a continuous stream of audio, so I can react, as soon as the reference audio sample occurs.
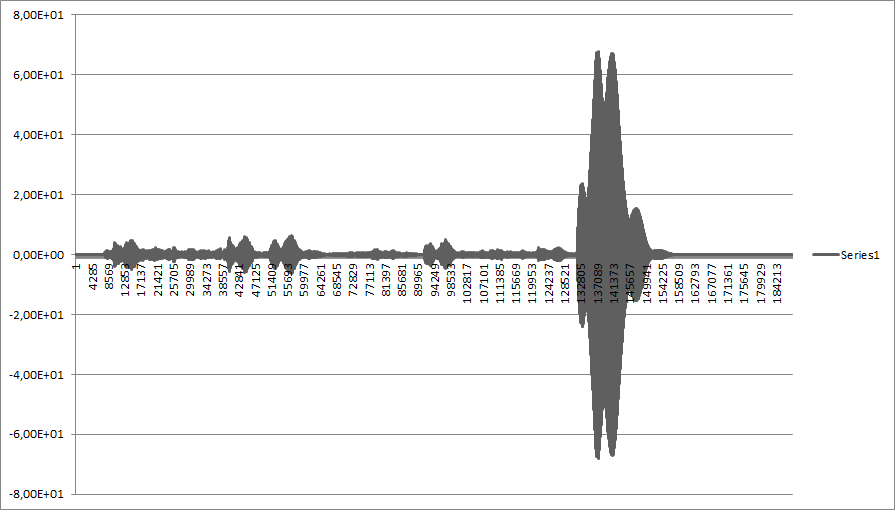
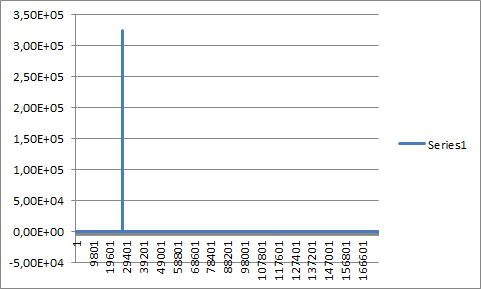
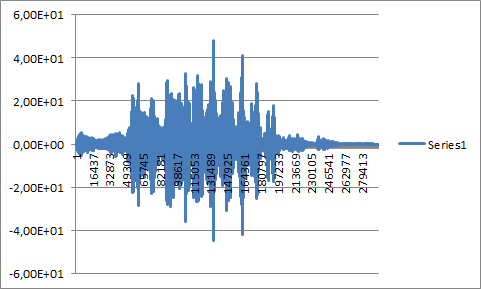
- I don't understand, why picture 2 and picture 4 (see below) differ so much, although, both represent an audio sample convolved with itself...
Any help is highly appreciated.
The following pictures are the result of the analysis using Excel:
- A longer audio sample with the reference audio (a beep) near the end:
![]()
- The beep convolved with itself:
![]()
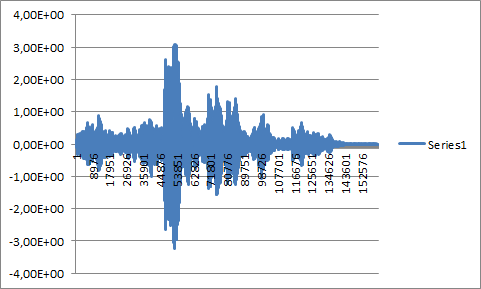
- A longer audio sample without the beep convolved with the beep:
![]()
- The longer audio sample of point 3 convolved with itself:
![]()
UPDATE and solution:
Thanks to the extensive help of Han, I was able to achieve my goal.
After I rolled my own slow implementation without FFT, I found alglib which provides a fast implementation.
There is one basic assumption to my problem: One of the audio samples is contained completely within the other.
So, the following code returns the offset in samples in the larger of the two audio samples and the normalized cross-correlation value at that offset. 1 means complete correlation, 0 means no correlation at all and -1 means complete negative correlation:
private void CalcCrossCorrelation(IEnumerable<double> data1,
IEnumerable<double> data2,
out int offset,
out double maximumNormalizedCrossCorrelation)
{
var data1Array = data1.ToArray();
var data2Array = data2.ToArray();
double[] result;
alglib.corrr1d(data1Array, data1Array.Length,
data2Array, data2Array.Length, out result);
var max = double.MinValue;
var index = 0;
var i = 0;
// Find the maximum cross correlation value and its index
foreach (var d in result)
{
if (d > max)
{
index = i;
max = d;
}
++i;
}
// if the index is bigger than the length of the first array, it has to be
// interpreted as a negative index
if (index >= data1Array.Length)
{
index *= -1;
}
var matchingData1 = data1;
var matchingData2 = data2;
var biggerSequenceCount = Math.Max(data1Array.Length, data2Array.Length);
var smallerSequenceCount = Math.Min(data1Array.Length, data2Array.Length);
offset = index;
if (index > 0)
matchingData1 = data1.Skip(offset).Take(smallerSequenceCount).ToList();
else if (index < 0)
{
offset = biggerSequenceCount + smallerSequenceCount + index;
matchingData2 = data2.Skip(offset).Take(smallerSequenceCount).ToList();
matchingData1 = data1.Take(smallerSequenceCount).ToList();
}
var mx = matchingData1.Average();
var my = matchingData2.Average();
var denom1 = Math.Sqrt(matchingData1.Sum(x => (x - mx) * (x - mx)));
var denom2 = Math.Sqrt(matchingData2.Sum(y => (y - my) * (y - my)));
maximumNormalizedCrossCorrelation = max / (denom1 * denom2);
}
BOUNTY:
No new answers required! I started the bounty to award it to Han for his continued effort with this question!