I have a csv file, it has 2 columns: class and text_data. I first extract biGram and TriGrams, then tried to use SVM on my data for classification. But it shows "TypeError: sequence item 0: expected a bytes-like object, str found". I have used Gensim=4.0.0. Your help highly appreciated. Code:
# all packages imported
df_covid = pd.read_csv('allCurated853_4.csv', encoding="utf8")
df_covid['label'] = df_covid['class'].map({
'covidshutdown': 0,
'manufactoring':1,
'corporate':2,
'environmental':3,
'infrastructure':4,
'other':5
})
X = df_covid['text_data']
y = df_covid['label']
corpus=X
lst_corpus = []
for string in corpus:
lst_words = string.split()
lst_grams = [" ".join(lst_words[i:i+1])
for i in range(0, len(lst_words), 1)]
lst_corpus.append(lst_grams)
bigrams_detector = gensim.models.phrases.Phrases(lst_corpus,
delimiter=" ".encode(), min_count=5, threshold=10)
bigrams_detector = gensim.models.phrases.Phraser(bigrams_detector)
trigrams_detector = gensim.models.phrases.Phrases(bigrams_detector[lst_corpus],
delimiter=" ".encode(), min_count=5, threshold=10)
trigrams_detector = gensim.models.phrases.Phraser(trigrams_detector)
cv = gensim.models.word2vec.Word2Vec(lst_corpus, size=300, window=8,
min_count=1, sg=1, iter=30)
X_trainCv, X_testCv, y_trainCv, y_testCv = train_test_split(cv, y,
test_size=0.20, random_state=42)
clf = svm.SVC(kernel='linear').fit(X_trainCv,y_trainCv)
y_pred = clf.predict(X_testCv)
print(classification_report(X_testCv, y_pred))
Complete Error message:
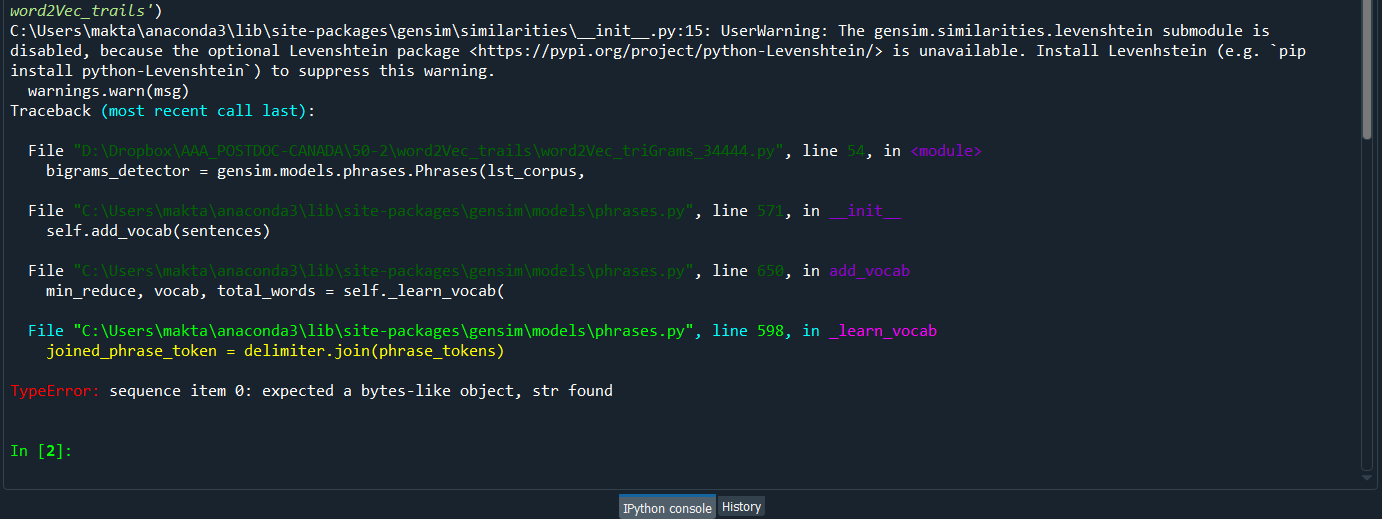
This is a dataset click here to download
if, I do not use biGrams and triGrams and change word2Vec model to this
cv= gensim.models.Word2Vec(lst_corpus, vector_size=100, window=5, min_count=5, workers=4)
New error message appears:
Traceback (most recent call last):
File "D:\Dropbox\AAA\50-2\word2Vec_trails\word2Vec_triGrams_34445.py", line 65, in <module>
X_trainCv, X_testCv, y_trainCv, y_testCv = train_test_split(cv, y, test_size=0.20, random_state=42)
File "C:\Users\makta\anaconda3\lib\site-packages\sklearn\model_selection\_split.py", line 2172, in train_test_split
arrays = indexable(*arrays)
File "C:\Users\makta\anaconda3\lib\site-packages\sklearn\utils\validation.py", line 299, in indexable
check_consistent_length(*result)
File "C:\Users\makta\anaconda3\lib\site-packages\sklearn\utils\validation.py", line 259, in check_consistent_length
lengths = [_num_samples(X) for X in arrays if X is not None]
File "C:\Users\makta\anaconda3\lib\site-packages\sklearn\utils\validation.py", line 259, in <listcomp>
lengths = [_num_samples(X) for X in arrays if X is not None]
File "C:\Users\makta\anaconda3\lib\site-packages\sklearn\utils\validation.py", line 202, in _num_samples
raise TypeError("Singleton array %r cannot be considered"
TypeError: Singleton array array(<gensim.models.word2vec.Word2Vec object at 0x000001A41DF59820>,
dtype=object) cannot be considered a valid collection.
I made this attempt (below code) to use word2vec vectors like count vectorizer or TFIDF. It generates output,but not corrent one. I think I should make list of lists of vectors. Help appreciated. this is Code:
from sklearn import svm
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
df_covid = pd.read_csv('allCurated853_4.csv', encoding="utf8")
df['label'] = df['class'].map({'covidshutdowncsv': 0, 'manufactoringcsv':1, 'corporatecsv':2, 'environmentalcsv':3,'infrastructurecsv':4, 'other':5})
X = df['message']
y = df['label']
X=X.to_string ()
ls = []
rows = X.splitlines(True)
print('size of rows:', len(rows)) # size of rows: 852
for i in rows:
ls.append(i.split(' '))
print('total words:', len(ls)) # total words: 852
model = Word2Vec(ls, min_count=1, size = 4)
words = list(model.wv.vocab)
print('words in vocabolary :',len(words)) # words in vocabolary:3110
print(words)
words=words[0:852] # problem
vectors = []
for word in words:
vectors.append(model[word].tolist())
data = np.array(vectors)
print('vectors of words:', len(data)) # vectors of words: 852
X_trainCv, X_testCv, y_trainCv, y_testCv = train_test_split(data, y, test_size=0.20, random_state=42)
clf_covid = svm.SVC(kernel='linear').fit(X_trainCv,y_trainCv)
clf_covid.score(X_testCv,y_testCv)
# score: 0.50299
bigram_detectorthentrigram_detectorcode doesn't actually feed into later steps. Is it really important? Are you sure you want to be trying advancedPhrasescombinations before having something more simple working? (2) Is your code modeled after something elsewhere? The choice to setdelimiter=" ".encode()may be a little off, and the error seems to highlight a problem with the setdelimiter. Why do you need a non-default delimiter, anyway? – Assyriancvvariable is an instance of theWord2Vecmodel, with all sorts of internal state, including among other things a collection of word-vectors that can be looked up by word keys. You are passing thatcvinstance intoscikit-learn'strain_test_split()function. It's not expecting aWord2Vecobject, but some ordered collection of input rows, one per item that's to be classified. – AssyrianWord2Vecmodel to help? – AssyrianWord2Vecmodel, with its vectors for a vocabulary of 3,110 words, into vectors for 852 multi-word texts instead? (Separately: a corpus with a mere 3k unique words is unlikely to train a very good word2vec model – as the algorithm requires large, varid training sets to work well. And,min_count=1is almost always a bad idea with word2vec - it needs multiple contrasting examples of a word to place it well, so much so that discarding rare words, as the defaultmin_count=5does, usually gives better results than keeping them.) – Assyrian