ARIMA from statsmodels is giving me inaccurate answers for my output. I was wondering whether someone could help me understand what's wrong with my code.
This is a sample:
import pandas as pd
import numpy as np
import datetime as dt
from statsmodels.tsa.arima_model import ARIMA
# Setting up a data frame that looks twenty days into the past,
# and has linear data, from approximately 1 through 20
counts = np.arange(1, 21) + 0.2 * (np.random.random(size=(20,)) - 0.5)
start = dt.datetime.strptime("1 Nov 01", "%d %b %y")
daterange = pd.date_range(start, periods=20)
table = {"count": counts, "date": daterange}
data = pd.DataFrame(table)
data.set_index("date", inplace=True)
print data
count
date
2001-11-01 0.998543
2001-11-02 1.914526
2001-11-03 3.057407
2001-11-04 4.044301
2001-11-05 4.952441
2001-11-06 6.002932
2001-11-07 6.930134
2001-11-08 8.011137
2001-11-09 9.040393
2001-11-10 10.097007
2001-11-11 11.063742
2001-11-12 12.051951
2001-11-13 13.062637
2001-11-14 14.086016
2001-11-15 15.096826
2001-11-16 15.944886
2001-11-17 17.027107
2001-11-18 17.930240
2001-11-19 18.984202
2001-11-20 19.971603
The rest of the code sets up the ARIMA model.
# Setting up ARIMA model
order = (2, 1, 2)
model = ARIMA(data, order, freq='D')
model = model.fit()
print model.predict(1, 20)
2001-11-02 1.006694
2001-11-03 1.056678
2001-11-04 1.116292
2001-11-05 1.049992
2001-11-06 0.869610
2001-11-07 1.016006
2001-11-08 1.110689
2001-11-09 0.945190
2001-11-10 0.882679
2001-11-11 1.139272
2001-11-12 1.094019
2001-11-13 0.918182
2001-11-14 1.027932
2001-11-15 1.041074
2001-11-16 0.898727
2001-11-17 1.078199
2001-11-18 1.027331
2001-11-19 0.978840
2001-11-20 0.943520
2001-11-21 1.040227
Freq: D, dtype: float64
As you could see, the data is just constant around 1 instead of increasing. What am I doing wrong here?
(On a side note, I can't pass in string dates like "2001-11-21" into the predict function for some reason. It would be helpful to know why.)
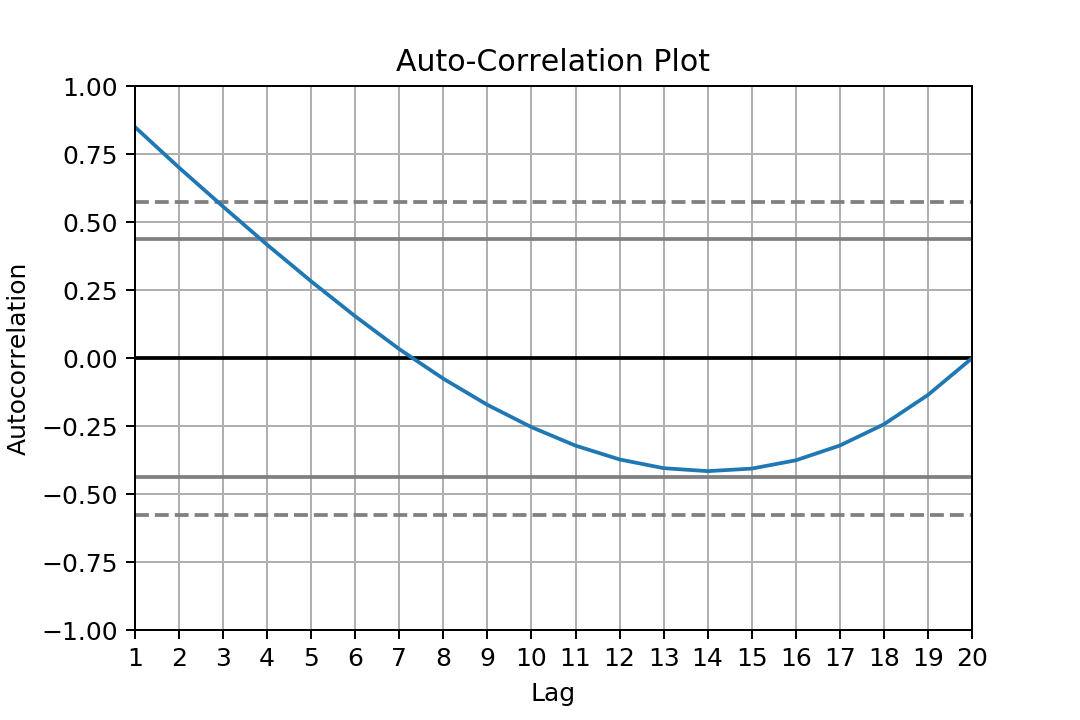
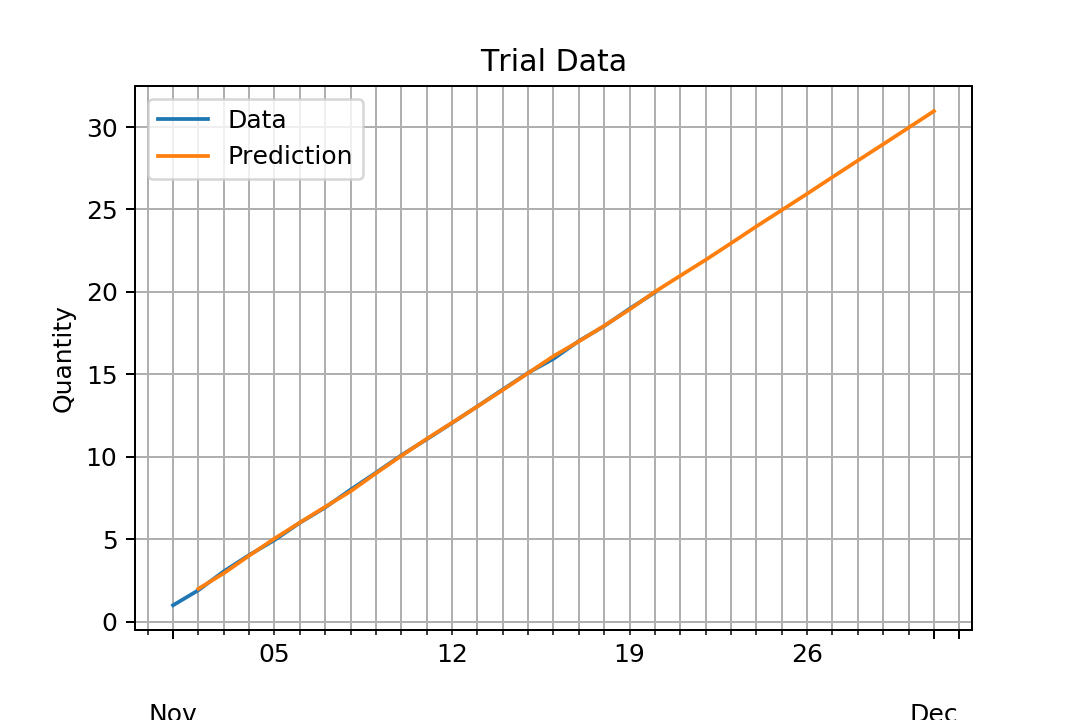
typ='level'to predict. See #30108591 and the predict docstring. It's also possible to add a trend directly to the model (currently to fit). – GaylegayleenARIMA.predictthough. It must be a concept in statistics. – Tracttyp='levels', nottype='level'. Maybe it was'level'in the past but documentation showstyp : str {‘linear’, ‘levels’}– Sosthina