So I am trying to train a simple recurrent network to detect a "burst" in an input signal. The following figure shows the input signal (blue) and the desired (classification) output of the RNN, shown in red.
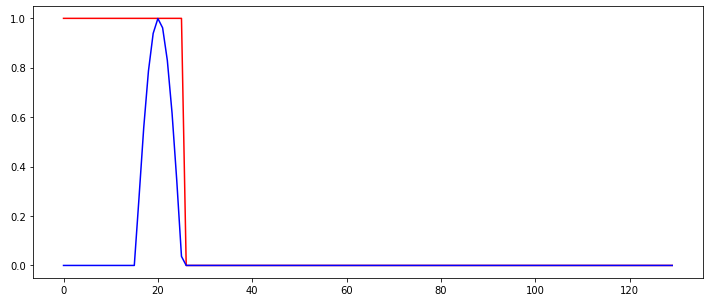
So the output of the network should switch from 1 to 0 whenever the burst is detected and stay like with that output. The only thing that changes between the input sequences used to train the RNN is at which time step the burst occurs.
Following the Tutorial on https://github.com/MorvanZhou/PyTorch-Tutorial/blob/master/tutorial-contents/403_RNN_regressor.py, I cannot get a RNN to learn. The learned RNN always operates in a "memoryless" way, i.e., does not use memory to make its predictions, as shown in the following example behavior:
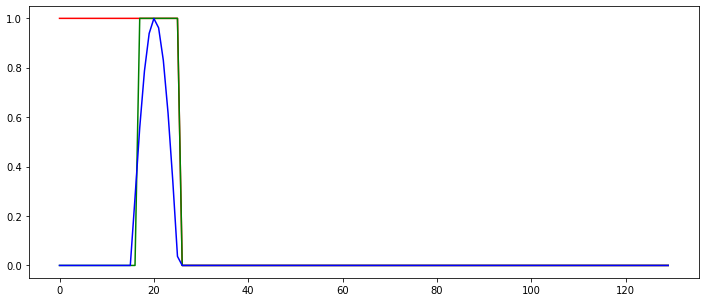
The green line shows the predicted output of the network. What do I do wrong in this example so that the network cannot be learned correctly? Isn't the network task quite simple?
I'm using:
- torch.nn.CrossEntropyLoss as loss function
- The Adam Optimizer for learning
- A RNN with 16 internal/hidden nodes and 2 output nodes. They use the default activation function of the torch.RNN class.
The experiment has been repeated a couple of times with different random seeds, but there is little difference in the outcomes. I've used the following code:
import torch
import numpy, math
import matplotlib.pyplot as plt
nofSequences = 5
maxLength = 130
# Generate training data
x_np = numpy.zeros((nofSequences,maxLength,1))
y_np = numpy.zeros((nofSequences,maxLength))
numpy.random.seed(1)
for i in range(0,nofSequences):
startPos = numpy.random.random()*50
for j in range(0,maxLength):
if j>=startPos and j<startPos+10:
x_np[i,j,0] = math.sin((j-startPos)*math.pi/10)
else:
x_np[i,j,0] = 0.0
if j<startPos+10:
y_np[i,j] = 1
else:
y_np[i,j] = 0
# Define the neural network
INPUT_SIZE = 1
class RNN(torch.nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = torch.nn.RNN(
input_size=INPUT_SIZE,
hidden_size=16, # rnn hidden unit
num_layers=1, # number of rnn layer
batch_first=True,
)
self.out = torch.nn.Linear(16, 2)
def forward(self, x, h_state):
r_out, h_state = self.rnn(x, h_state)
outs = [] # save all predictions
for time_step in range(r_out.size(1)): # calculate output for each time step
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state
# Learn the network
rnn = RNN()
optimizer = torch.optim.Adam(rnn.parameters(), lr=0.01)
h_state = None # for initial hidden state
x = torch.Tensor(x_np) # shape (batch, time_step, input_size)
y = torch.Tensor(y_np).long()
torch.manual_seed(2)
numpy.random.seed(2)
for step in range(100):
prediction, h_state = rnn(x, h_state) # rnn output
# !! next step is important !!
h_state = h_state.data # repack the hidden state, break the connection from last iteration
loss = torch.nn.CrossEntropyLoss()(prediction.reshape((-1,2)),torch.autograd.Variable(y.reshape((-1,)))) # calculate loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
errTrain = (prediction.max(2)[1].data != y).float().mean()
print("Error Training:",errTrain.item())
For those who want to reproduce the experiment, the plot is drawn using the following code (using Jupyter Notebook):
steps = range(0,maxLength)
plotChoice = 3
plt.figure(1, figsize=(12, 5))
plt.ion() # continuously plot
plt.plot(steps, y_np[plotChoice,:].flatten(), 'r-')
plt.plot(steps, numpy.argmax(prediction.detach().numpy()[plotChoice,:,:],axis=1), 'g-')
plt.plot(steps, x_np[plotChoice,:,0].flatten(), 'b-')
plt.ioff()
plt.show()
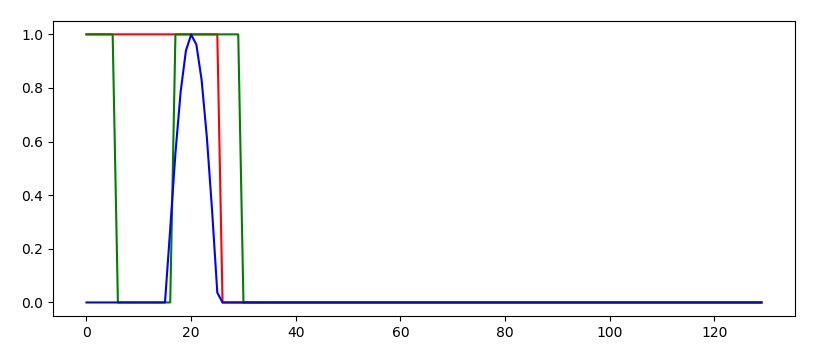
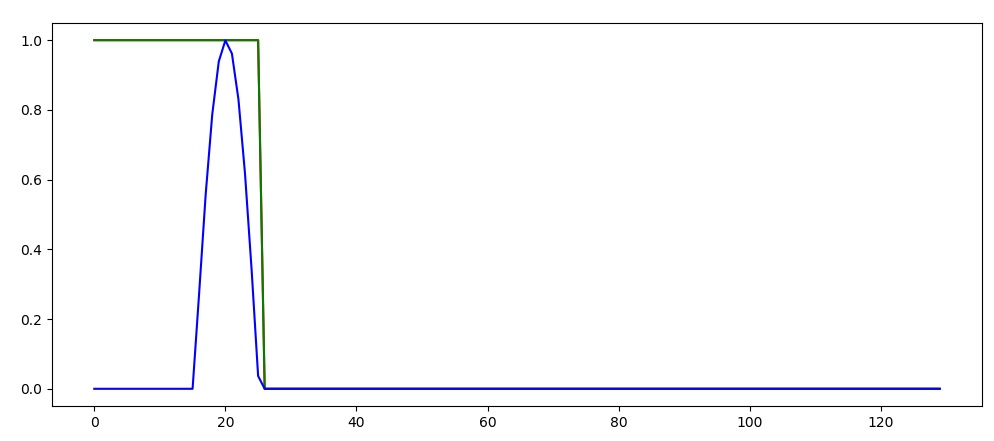
h_state = h_state.datadoes not "break the connection from last iteration". When you call rnn(x) thernn.rnnlayer will be given all thextimesteps and will utilize the memory of the rnn as intended. In python, variable names are simply ways to point to memory and when you doh_state = h_state.datayou simply change where theh_statevariable points for your__main__context and that won't affect the training behaviour of your model. – Demitriah_state = copy.deepcopy(h_state.data)– Herwig