How could I search the contents of PDF files in a directory/subdirectory? I am looking for some command line tools. It seems that grep can't search PDF files.
How to search contents of multiple pdf files?
Grep will not work as PDF is a binary format and the text is often compressed or encoded in a variety of ways. –
Discussion
Here is a GUI solution: Adobe Reader, see wikispaces.psu.edu/display/training/… –
Bartle
Related: unix.stackexchange.com/questions/6704/grep-pdf-files –
Brendin
Adobe reader works fine, but it does not index; so if you have a lot of files, it will be slow. Any indexing solution? –
Bulbous
Your distribution should provide a utility called pdftotext:
find /path -name '*.pdf' -exec sh -c 'pdftotext "{}" - | grep --with-filename --label="{}" --color "your pattern"' \;
The "-" is necessary to have pdftotext output to stdout, not to files.
The --with-filename and --label= options will put the file name in the output of grep.
The optional --color flag is nice and tells grep to output using colors on the terminal.
(In Ubuntu, pdftotext is provided by the package xpdf-utils or poppler-utils.)
This method, using pdftotext and grep, has an advantage over pdfgrep if you want to use features of GNU grep that pdfgrep doesn't support. Note: pdfgrep-1.3.x supports -C option for printing line of context.
@Kurt Pfeifle The edit "(Edit by -kp-)" you made does no not work since
grep filters the printed file names. –
Numerate @Urus no, while the
pdfgrep solution is good for really quick and simple searches, often I want to get some context, as a single line won't be helpful enough -- so as I added to this answer: For instance, you can add the -C5 option before "your pattern" to include 5 lines of context to the output -- pdfgrep does not support this –
Wrigley oh that's cool, glad to know there are advantages to this even though it is much less obvious to most people wtf it is doing –
Urus
@Urus Just for the record: I am using Ubuntu 12.10 and
pdfgrep is useless, it reports a tremendous amount of rubbish on files it cannot handle. Your solution on the other hand helped. So please don't delete it, even after 3 years it is still helpful! –
Referee I was able to use it also in cygwin, altough to make it a function with parameter I had to make the "your_pattern" become '$1' –
Makalu
There is pdfgrep, which does exactly what its name suggests.
pdfgrep -R 'a pattern to search recursively from path' /some/path
I've used it for simple searches and it worked fine.
(There are packages in Debian, Ubuntu and Fedora.)
Since version 1.3.0 pdfgrep supports recursive search. This version is available in Ubuntu since Ubuntu 12.10 (Quantal).
From Natty (Ubuntu 11.04) upwards (See packages.ubuntu.com/…) –
Bartle
@pavon
pdfgrep does now have that recursion option, including -R to also follow symlinks –
Mathis I have a problem with this tool on Debian 10. It does not find some strings which can be found with evince. Turns out to be quite unreliable. –
Snocat
@Snocat Seven years later, problem remains. Results seem to depend on how pdf was created. So pdftotext -raw (though deprecated) seems to help. –
Sirius
As of release 2.0
pdfgrep has a --cache option to drastically speed up multiple searches on the same files. –
Wilen Your distribution should provide a utility called pdftotext:
find /path -name '*.pdf' -exec sh -c 'pdftotext "{}" - | grep --with-filename --label="{}" --color "your pattern"' \;
The "-" is necessary to have pdftotext output to stdout, not to files.
The --with-filename and --label= options will put the file name in the output of grep.
The optional --color flag is nice and tells grep to output using colors on the terminal.
(In Ubuntu, pdftotext is provided by the package xpdf-utils or poppler-utils.)
This method, using pdftotext and grep, has an advantage over pdfgrep if you want to use features of GNU grep that pdfgrep doesn't support. Note: pdfgrep-1.3.x supports -C option for printing line of context.
@Kurt Pfeifle The edit "(Edit by -kp-)" you made does no not work since
grep filters the printed file names. –
Numerate @Urus no, while the
pdfgrep solution is good for really quick and simple searches, often I want to get some context, as a single line won't be helpful enough -- so as I added to this answer: For instance, you can add the -C5 option before "your pattern" to include 5 lines of context to the output -- pdfgrep does not support this –
Wrigley oh that's cool, glad to know there are advantages to this even though it is much less obvious to most people wtf it is doing –
Urus
@Urus Just for the record: I am using Ubuntu 12.10 and
pdfgrep is useless, it reports a tremendous amount of rubbish on files it cannot handle. Your solution on the other hand helped. So please don't delete it, even after 3 years it is still helpful! –
Referee I was able to use it also in cygwin, altough to make it a function with parameter I had to make the "your_pattern" become '$1' –
Makalu
Recoll is a fantastic full-text GUI search application for Unix/Linux that supports dozens of different formats, including PDF. It can even pass the exact page number and search term of a query to the document viewer and thus allows you to jump to the result right from its GUI.
Recoll also comes with a viable command-line interface and a web-browser interface.
@Anaemia It would help (me and possibly others too) if you could add an example pertaining to the original question (command line tool for search of multiple pdf's): I would also like to see how to perform a wildcard search and how to search the current directory including all subdirectories. How would that look with
recoll / xapian in the command line (non-GUI)? Thanks! –
Beadle @LeszekŻarna Perhaps you could post the example you tested? –
Beadle
The
recoll user manual might contain some pointers, but offers a rather technical and "off-topic" read... –
Beadle @nutty: recoll -t -q dir:
pwd ext:pdf 'neuro*' -- stackoverflow ate the backticks around pwd. –
Valediction My actual version of pdfgrep (1.3.0) allows the following:
pdfgrep -HiR 'pattern' /path
When doing pdfgrep --help:
- H: Print the file name for each match.
- i: Ignore case distinctions.
- R: Search directories recursively.
It works well on my Ubuntu.
There is another utility called ripgrep-all, which is based on ripgrep.
It can handle more than just PDF documents, like Office documents and movies, and the author claims it is faster than pdfgrep.
Command syntax for recursively searching the current directory, and the second one limits to PDF files only:
rga 'pattern' .
rga --type pdf 'pattern' .
I made this destructive small script. Have fun with it.
function pdfsearch()
{
find . -iname '*.pdf' | while read filename
do
#echo -e "\033[34;1m// === PDF Document:\033[33;1m $filename\033[0m"
pdftotext -q -enc ASCII7 "$filename" "$filename."; grep -s -H --color=always -i $1 "$filename."
# remove it! rm -f "$filename."
done
}
+1. But instead of the
$filename. you should pipe it into grep. –
Numerate I like @sjr's answer however I prefer xargs vs -exec. I find xargs more versatile. For example with -P we can take advantage of multiple CPUs when it makes sense to do so.
find . -name '*.pdf' | xargs -P 5 -I % pdftotext % - | grep --with-filename --label="{}" --color "pattern"
interesting point about
xargs' parallel-processing capability. Note that your --label option-argument will be literally {}, because the grep command is now no longer executed in the context of find's exec. –
Proprietary I had the same problem and thus I wrote a script which searches all pdf files in the specified folder for a string and prints the PDF files wich matched the query string.
Maybe this will be helpful to you.
You can download it here
maybe useful to put the script in the comment? –
Jaxartes
i tried your script and it turns out much slower than the
pdfgrep solution or sjr's one-liner, and it left me with an ongoing process using 100% of a CPU thread even after I Ctrl-C to terminate it. –
Sarena If You want to see file names with pdftotext use following command:
find . -name '*.pdf' -exec echo {} \; -exec pdftotext {} - \; | grep "pattern\|pdf"
First convert all your pdf files to text files:
for file in *.pdf;do pdftotext "$file"; done
Then use grep as normal. This is especially good as it is fast when you have multiple queries and a lot of PDF files.
This, when done in combination with
ag github.com/ggreer/the_silver_searcher . Capable to parse at psychedeliks Gb by microseconds. Flat files for life –
Kaylenekayley There is an open source common resource grep tool crgrep which searches within PDF files but also other resources like content nested in archives, database tables, image meta-data, POM file dependencies and web resources - and combinations of these including recursive search.
The full description under the Files tab pretty much covers what the tool supports.
I developed crgrep as an opensource tool.
Craig - do you have a connection to that project? If so, you should state it in your answer. I say this because you've just posted a virtually identical answer to two other old questions ... –
Infantile
Updated post to clarify that I'm the author of crgrep –
Stivers
You need some tools like pdf2text to first convert your pdf to a text file and then search inside the text. (You will probably miss some information or symbols).
If you are using a programming language there are probably pdf libraries written for this purpose. e.g. http://search.cpan.org/dist/CAM-PDF/ for Perl
try using 'acroread' in a simple script like the one above
Thanks for all the good ideas here!
I tried the xargs method, but as pointed out here, xargs will make it impossible (or very hard) to include printing the actual file name...
So I tried the whole thing with GNU parallel.
parallel "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'" ::: *.pdf
- This prints not only the pattern, but with
--context=5also 5 lines above and below as well for context. - With
-qpdftotext won't print any error messages or warnings (quiet). - I use brackets
[]as labels instead of braces{}. If you wanted braces--label='{'{}'}'will make that happen. Note that{}is replaced by the actual filename by GNU parallel, e.g.'Example portable document file name with spaces.pdf'({}is already using single quotes'). - By using
--label={}only the filename will be printed, which may be the favored way of displaying the filename. - I also noticed that the output was without color when I tried it, except when forcing it by adding
--color=alwayswith grep. - It may be useful to add
--ignore-caseto the grep command for a case-insensitive keyword search.
If all PDF files should be processed recursively, including all sub-directories in the current directory (.), this can be accomplished through find:
find . -type f -iname '*.pdf' -print0 | parallel -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --context=5 'pattern'"
- With find,
-iname '*.pdf'acts case-insensitive. With-name '*.pdf'only lower-case .pdf files will be included (the normal case). Since I sometimes also encountered Windows PDF-files with an upper-case .PDF file extension, I tend to prefer-iname... - The above command also works with the
-printfind option (instead of-print0), so it will be line-based (one file name per line), then-0(NUL delimiter) must be omitted from the parallel command. - Again, including
--ignore-casein the grep command will make the search case-insensitive.
As a general recommendation when playing with the whole command line, parallel --dry-run will print which commands would be executed.
$ find . -type f -iname '*.pdf' -print0 | parallel --dry-run -0 "pdftotext -q {} - | grep --with-filename --label='['{}']' --color=always --ignore-case --context=5 'pattern'"
pdftotext -q ./test PDF file 1.pdf - | grep --with-filename --label='['./test PDF file 1.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir1/test PDF file 2.pdf - | grep --with-filename --label='['./subdir1/test PDF file 2.pdf']' --color=always --ignore-case --context=5 'pattern'
pdftotext -q ./subdir2/test PDF file 3.pdf - | grep --with-filename --label='['./subdir2/test PDF file 3.pdf']' --color=always --ignore-case --context=5 'pattern'
Use pdfgrep:
pdfgrep -HinR 'FWCOSP' DatenModel/
In this command I'm searching for the word FWCOSP inside the folder DatenModel/.
As you can see in the output you can have the file name wit the line numbers:
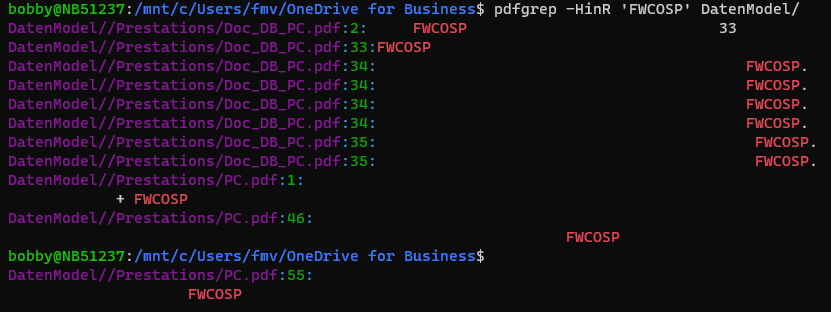
The options I'm using are:
-i : Ignores, case for matching
-H : print the file name for each match
-n : prefix each match with the number of the page where it is found
-R : same as -r, but it also follows all symlinks.
© 2022 - 2024 — McMap. All rights reserved.