Fixing problems installing Pyspark (Windows)
Incorrect JAVA_HOME path
> pyspark
The system cannot find the path specified.
Open System Environment variables:
rundll32 sysdm.cpl,EditEnvironmentVariables
Set JAVA_HOME: System Variables > New:
Variable Name: JAVA_HOME
Variable Value: C:\Program Files\Java\jdk1.8.0_261
Also, check that SPARK_HOME and HADOOP_HOME are correctly set, e.g.:
SPARK_HOME=C:\Spark\spark-3.2.0-bin-hadoop3.2
HADOOP_HOME=C:\Spark\spark-3.2.0-bin-hadoop3.2
Important: Double-check the following
- The path exists
- The path does not contain the
bin folder
Incorrect Java version
> pyspark
WARN SparkContext: Another SparkContext is being constructed
UserWarning: Failed to initialize Spark session.
java.lang.NoClassDefFoundError: Could not initialize class org.apache.spark.storage.StorageUtils$
Ensure that JAVA_HOME is set to Java 8 (jdk1.8.0)
winutils not installed
> pyspark
WARN Shell: Did not find winutils.exe
java.io.FileNotFoundException: Could not locate Hadoop executable
Download winutils.exe and copy it to your spark home bin folder
curl -OutFile C:\Spark\spark-3.2.0-bin-hadoop3.2\bin\winutils.exe -Uri https://github.com/steveloughran/winutils/raw/master/hadoop-3.0.0/bin/winutils.exe
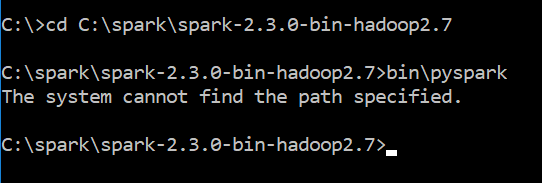

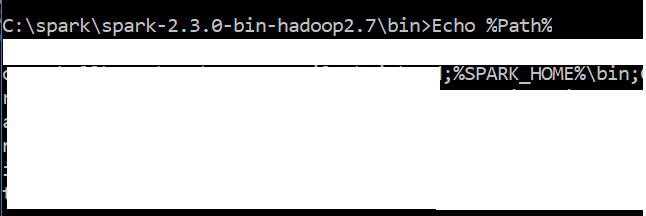 I have python 3.6 & Java "1.8.0_151" in my windows 10 system
Can you suggest me how to resolve this issue?
I have python 3.6 & Java "1.8.0_151" in my windows 10 system
Can you suggest me how to resolve this issue?