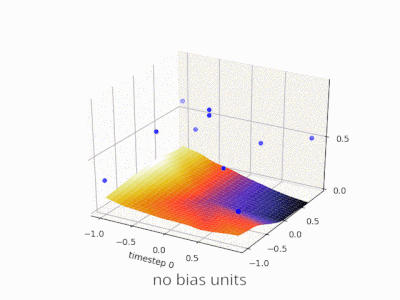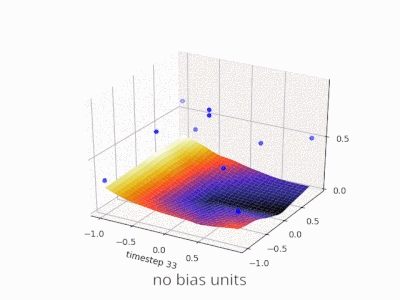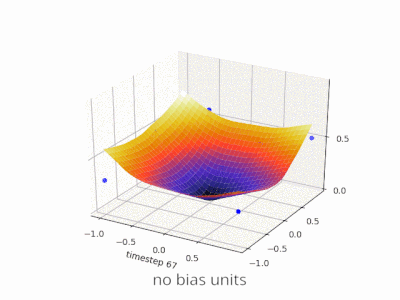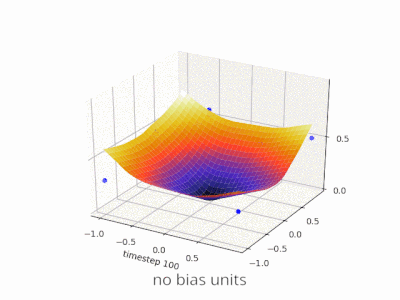
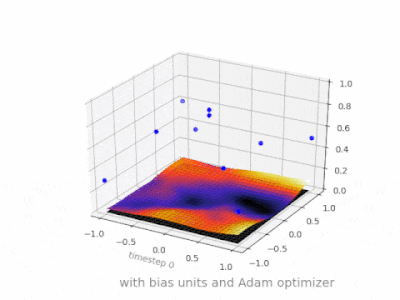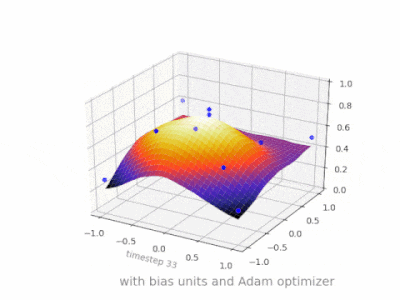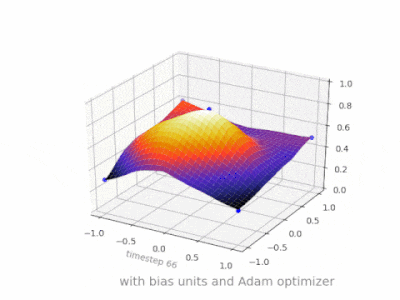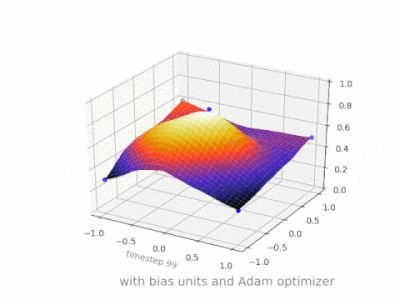
A layer in a neural network without a bias is nothing more than the multiplication of an input vector with a matrix. (The output vector might be passed through a sigmoid function for normalisation and for use in multi-layered ANN afterwards, but that’s not important.)
This means that you’re using a linear function and thus an input of all zeros will always be mapped to an output of all zeros. This might be a reasonable solution for some systems but in general it is too restrictive.
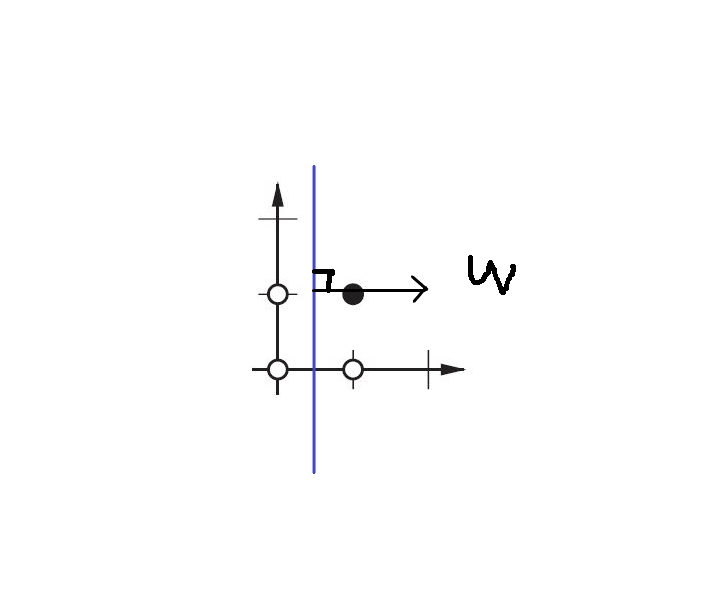
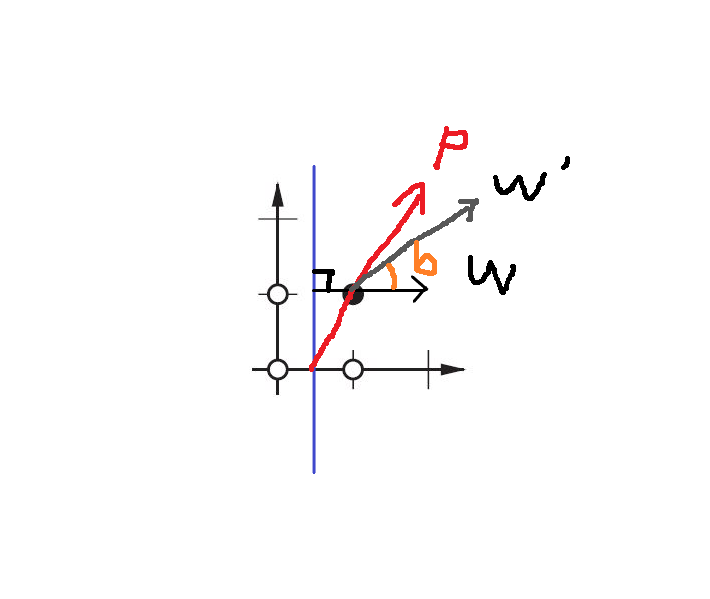
Using a bias, you’re effectively adding another dimension to your input space, which always takes the value one, so you’re avoiding an input vector of all zeros. You don’t lose any generality by this because your trained weight matrix needs not be surjective, so it still can map to all values previously possible.
2D ANN:
For a ANN mapping two dimensions to one dimension, as in reproducing the AND or the OR (or XOR) functions, you can think of a neuronal network as doing the following:
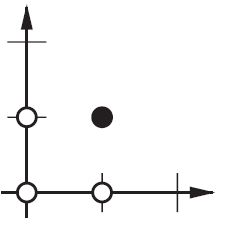
On the 2D plane mark all positions of input vectors. So, for boolean values, you’d want to mark (-1,-1), (1,1), (-1,1), (1,-1). What your ANN now does is drawing a straight line on the 2d plane, separating the positive output from the negative output values.
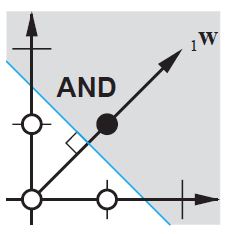
Without bias, this straight line has to go through zero, whereas with bias, you’re free to put it anywhere.
So, you’ll see that without bias you’re facing a problem with the AND function, since you can’t put both (1,-1) and (-1,1) to the negative side. (They are not allowed to be on the line.) The problem is equal for the OR function. With a bias, however, it’s easy to draw the line.
Note that the XOR function in that situation can’t be solved even with bias.





{kind=link}
{kind=link}