8 bits representing the number 7 look like this:
00000111
Three bits are set.
What are the algorithms to determine the number of set bits in a 32-bit integer?
8 bits representing the number 7 look like this:
00000111
Three bits are set.
What are the algorithms to determine the number of set bits in a 32-bit integer?
This is known as the 'Hamming Weight', 'popcount' or 'sideways addition'.
Some CPUs have a single built-in instruction to do it and others have parallel instructions which act on bit vectors. Instructions like x86's popcnt (on CPUs where it's supported) will almost certainly be fastest for a single integer. Some other architectures may have a slow instruction implemented with a microcoded loop that tests a bit per cycle (citation needed - hardware popcount is normally fast if it exists at all.).
The 'best' algorithm really depends on which CPU you are on and what your usage pattern is.
Your compiler may know how to do something that's good for the specific CPU you're compiling for, e.g. C++20 std::popcount(), or C++ std::bitset<32>::count(), as a portable way to access builtin / intrinsic functions (see another answer on this question). But your compiler's choice of fallback for target CPUs that don't have hardware popcnt might not be optimal for your use-case. Or your language (e.g. C) might not expose any portable function that could use a CPU-specific popcount when there is one.
A pre-populated table lookup method can be very fast if your CPU has a large cache and you are doing lots of these operations in a tight loop. However it can suffer because of the expense of a 'cache miss', where the CPU has to fetch some of the table from main memory. (Look up each byte separately to keep the table small.) If you want popcount for a contiguous range of numbers, only the low byte is changing for groups of 256 numbers, making this very good.
If you know that your bytes will be mostly 0's or mostly 1's then there are efficient algorithms for these scenarios, e.g. clearing the lowest set with a bithack in a loop until it becomes zero.
I believe a very good general purpose algorithm is the following, known as 'parallel' or 'variable-precision SWAR algorithm'. I have expressed this in a C-like pseudo language, you may need to adjust it to work for a particular language (e.g. using uint32_t for C++ and >>> in Java):
GCC10 and clang 10.0 can recognize this pattern / idiom and compile it to a hardware popcnt or equivalent instruction when available, giving you the best of both worlds. (Godbolt)
int numberOfSetBits(uint32_t i)
{
// Java: use int, and use >>> instead of >>. Or use Integer.bitCount()
// C or C++: use uint32_t
i = i - ((i >> 1) & 0x55555555); // add pairs of bits
i = (i & 0x33333333) + ((i >> 2) & 0x33333333); // quads
i = (i + (i >> 4)) & 0x0F0F0F0F; // groups of 8
i *= 0x01010101; // horizontal sum of bytes
return i >> 24; // return just that top byte (after truncating to 32-bit even when int is wider than uint32_t)
}
For JavaScript: coerce to integer with |0 for performance: change the first line to i = (i|0) - ((i >> 1) & 0x55555555);
This has the best worst-case behaviour of any of the algorithms discussed, so will efficiently deal with any usage pattern or values you throw at it. (Its performance is not data-dependent on normal CPUs where all integer operations including multiply are constant-time. It doesn't get any faster with "simple" inputs, but it's still pretty decent.)
References:
i = i - ((i >> 1) & 0x55555555);
The first step is an optimized version of masking to isolate the odd / even bits, shifting to line them up, and adding. This effectively does 16 separate additions in 2-bit accumulators (SWAR = SIMD Within A Register). Like (i & 0x55555555) + ((i>>1) & 0x55555555).
The next step takes the odd/even eight of those 16x 2-bit accumulators and adds again, producing 8x 4-bit sums. The i - ... optimization isn't possible this time so it does just mask before / after shifting. Using the same 0x33... constant both times instead of 0xccc... before shifting is a good thing when compiling for ISAs that need to construct 32-bit constants in registers separately.
The final shift-and-add step of (i + (i >> 4)) & 0x0F0F0F0F widens to 4x 8-bit accumulators. It masks after adding instead of before, because the maximum value in any 4-bit accumulator is 4, if all 4 bits of the corresponding input bits were set. 4+4 = 8 which still fits in 4 bits, so carry between nibble elements is impossible in i + (i >> 4).
So far this is just fairly normal SIMD using SWAR techniques with a few clever optimizations. Continuing on with the same pattern for 2 more steps can widen to 2x 16-bit then 1x 32-bit counts. But there is a more efficient way on machines with fast hardware multiply:
Once we have few enough "elements", a multiply with a magic constant can sum all the elements into the top element. In this case byte elements. Multiply is done by left-shifting and adding, so a multiply of x * 0x01010101 results in x + (x<<8) + (x<<16) + (x<<24). Our 8-bit elements are wide enough (and holding small enough counts) that this doesn't produce carry into that top 8 bits.
A 64-bit version of this can do 8x 8-bit elements in a 64-bit integer with a 0x0101010101010101 multiplier, and extract the high byte with >>56. So it doesn't take any extra steps, just wider constants. This is what GCC uses for __builtin_popcountll on x86 systems when the hardware popcnt instruction isn't enabled. If you can use builtins or intrinsics for this, do so to give the compiler a chance to do target-specific optimizations.
This bitwise-SWAR algorithm could parallelize to be done in multiple vector elements at once, instead of in a single integer register, for a speedup on CPUs with SIMD but no usable popcount instruction. (e.g. x86-64 code that has to run on any CPU, not just Nehalem or later.)
However, the best way to use vector instructions for popcount is usually by using a variable-shuffle to do a table-lookup for 4 bits at a time of each byte in parallel. (The 4 bits index a 16 entry table held in a vector register).
On Intel CPUs, the hardware 64bit popcnt instruction can outperform an SSSE3 PSHUFB bit-parallel implementation by about a factor of 2, but only if your compiler gets it just right. Otherwise SSE can come out significantly ahead. Newer compiler versions are aware of the popcnt false dependency problem on Intel.
vpternlogd making Harley-Seal very good.)unsigned int, to easily show that it is free of any sign bit complications. Also would uint32_t be safer, as in, you get what you expect on all platforms? –
Tolerant >> is implementation-defined for negative values. The argument needs to be changed (or cast) to unsigned, and since the code is 32-bit-specific, it should probably be using uint32_t. –
Corves Integer.bitCount(int) (since 1.5 but that's a while back already). –
Bowlin i = (i|0) - ((i >> 1) & 0x55555555); The |0 coerces the value to an int32, giving a significant speed-up. Also using >>> over >> seems slightly faster (although as previous comments have pointed out, both will in fact work correctly in this algorithm). See performance tests here: jsperf.com/fast-int32-bit-count –
Knives popcnt instruction when targeting x86. So assuming their idiom recognizers for this are non-buggy, that's rock-solid proof of correctness. –
Grane int count = 0; while (n) { count += n & 1; n >>= 1; } return count; –
Urbanism i *= 0x01010101; return i >> 24;. Maybe with a comment on the multiply about truncating to 32 bits before the shift. We definitely don't want an actual & 0xFF; some compilers might not optimize that away. –
Grane Some languages portably expose the operation in a way that can use efficient hardware support if available, otherwise some library fallback that's hopefully decent.
For example (from a table by language):
std::bitset<>::count(), or C++20 std::popcount(T x)java.lang.Integer.bitCount() (also for Long or BigInteger)System.Numerics.BitOperations.PopCount()int.bit_count() (since 3.10)Not all compilers / libraries actually manage to use HW support when it's available, though. (Notably MSVC, even with options that make std::popcount inline as x86 popcnt, its std::bitset::count still always uses a lookup table. This will hopefully change in future versions.)
Also consider the built-in functions of your compiler when the portable language doesn't have this basic bit operation. In GNU C for example:
int __builtin_popcount (unsigned int x);
int __builtin_popcountll (unsigned long long x);
In the worst case (no single-instruction HW support) the compiler will generate a call to a function (which in current GCC uses a shift/and bit-hack like this answer, at least for x86). In the best case the compiler will emit a cpu instruction to do the job. (Just like a * or / operator - GCC will use a hardware multiply or divide instruction if available, otherwise will call a libgcc helper function.) Or even better, if the operand is a compile-time constant after inlining, it can do constant-propagation to get a compile-time-constant popcount result.
The GCC builtins even work across multiple platforms. Popcount has almost become mainstream in the x86 architecture, so it makes sense to start using the builtin now so you can recompile to let it inline a hardware instruction when you compile with -mpopcnt or something that includes that (example). Other architectures have had popcount for years, but in the x86 world there are still some ancient Core 2 and similar vintage AMD CPUs in use.
On x86, you can tell the compiler that it can assume support for popcnt instruction with -mpopcnt (also implied by -msse4.2). See GCC x86 options. -march=nehalem -mtune=skylake (or -march= whatever CPU you want your code to assume and to tune for) could be a good choice. Running the resulting binary on an older CPU will result in an illegal-instruction fault.
To make binaries optimized for the machine you build them on, use -march=native (with gcc, clang, or ICC).
MSVC provides an intrinsic for the x86 popcnt instruction, but unlike gcc it's really an intrinsic for the hardware instruction and requires hardware support.
std::bitset<>::count() instead of a built-inIn theory, any compiler that knows how to popcount efficiently for the target CPU should expose that functionality through ISO C++ std::bitset<>. In practice, you might be better off with the bit-hack AND/shift/ADD in some cases for some target CPUs.
For target architectures where hardware popcount is an optional extension (like x86), not all compilers have a std::bitset that takes advantage of it when available. For example, MSVC has no way to enable popcnt support at compile time, and it's std::bitset<>::count always uses a table lookup, even with /Ox /arch:AVX (which implies SSE4.2, which in turn implies the popcnt feature.) (Update: see below; that does get MSVC's C++20 std::popcount to use x86 popcnt, but still not its bitset<>::count. MSVC could fix that by updating their standard library headers to use std::popcount when available.)
But at least you get something portable that works everywhere, and with gcc/clang with the right target options, you get hardware popcount for architectures that support it.
#include <bitset>
#include <limits>
#include <type_traits>
template<typename T>
//static inline // static if you want to compile with -mpopcnt in one compilation unit but not others
typename std::enable_if<std::is_integral<T>::value, unsigned >::type
popcount(T x)
{
static_assert(std::numeric_limits<T>::radix == 2, "non-binary type");
// sizeof(x)*CHAR_BIT
constexpr int bitwidth = std::numeric_limits<T>::digits + std::numeric_limits<T>::is_signed;
// std::bitset constructor was only unsigned long before C++11. Beware if porting to C++03
static_assert(bitwidth <= std::numeric_limits<unsigned long long>::digits, "arg too wide for std::bitset() constructor");
typedef typename std::make_unsigned<T>::type UT; // probably not needed, bitset width chops after sign-extension
std::bitset<bitwidth> bs( static_cast<UT>(x) );
return bs.count();
}
See asm from gcc, clang, icc, and MSVC on the Godbolt compiler explorer.
x86-64 gcc -O3 -std=gnu++11 -mpopcnt emits this:
unsigned test_short(short a) { return popcount(a); }
movzx eax, di # note zero-extension, not sign-extension
popcnt rax, rax
ret
unsigned test_int(int a) { return popcount(a); }
mov eax, edi
popcnt rax, rax # unnecessary 64-bit operand size
ret
unsigned test_u64(unsigned long long a) { return popcount(a); }
xor eax, eax # gcc avoids false dependencies for Intel CPUs
popcnt rax, rdi
ret
PowerPC64 gcc -O3 -std=gnu++11 emits (for the int arg version):
rldicl 3,3,0,32 # zero-extend from 32 to 64-bit
popcntd 3,3 # popcount
blr
This source isn't x86-specific or GNU-specific at all, but only compiles well with gcc/clang/icc, at least when targeting x86 (including x86-64).
Also note that gcc's fallback for architectures without single-instruction popcount is a byte-at-a-time table lookup. This isn't wonderful for ARM, for example.
std::popcount(T)Current libstdc++ headers unfortunately define it with a special case if(x==0) return 0; at the start, which clang doesn't optimize away when compiling for x86:
#include <bit>
int bar(unsigned x) {
return std::popcount(x);
}
clang 11.0.1 -O3 -std=gnu++20 -march=nehalem Live demo
# clang 11
bar(unsigned int): # @bar(unsigned int)
popcnt eax, edi
cmove eax, edi # redundant: if popcnt result is 0, return the original 0 instead of the popcnt-generated 0...
ret
But GCC compiles nicely:
# gcc 10
xor eax, eax # break false dependency on Intel SnB-family before Ice Lake.
popcnt eax, edi
ret
Even MSVC does well with it, as long as you use -arch:AVX or later (and enable C++20 with -std:c++latest). Live demo
int bar(unsigned int) PROC ; bar, COMDAT
popcnt eax, ecx
ret 0
int bar(unsigned int) ENDP ; bar
std::bitset::count. after inlining this compiles to a single __builtin_popcount call. –
Manteau __builtin functions aren't real functions that get called. If compiling for a target that supports it as a single instruction (e.g. x86 with -mpopcnt), it inlines to just that. However, without that gcc may emit a call to a libgcc.a function like __popcountdi2 instead of inlining those instructions. It's up to the compiler, though; clang4.0 chooses to inline, just like it does for std::bitset.count(). godbolt.org/g/TueMQt –
Grane popcnt instruction performance" mentioned in some of the above comments, the last several generations of Intel CPUs have been able to issue 1 popcnt per cycle, with a latency of 3 cycles, and AMD Zen architecture can issue 4 (!!) popcnt instructions per cycle with a latency of 1 cycle. So we can say that popcnt is "really fast" on modern hardware, and in AMD's case as fast as trivial instructions like or and add. –
Tot std::popcount() here: en.cppreference.com/w/cpp/numeric/popcount However, I prefer this answer because it also handles signed values. :) –
Blastula bit_count wasn't introduced until 3.10. I'm stuck at 3.8 so I can't use it. –
Lehmbruck In my opinion, the "best" solution is the one that can be read by another programmer (or the original programmer two years later) without copious comments. You may well want the fastest or cleverest solution which some have already provided but I prefer readability over cleverness any time.
unsigned int bitCount (unsigned int value) {
unsigned int count = 0;
while (value > 0) { // until all bits are zero
if ((value & 1) == 1) // check lower bit
count++;
value >>= 1; // shift bits, removing lower bit
}
return count;
}
If you want more speed (and assuming you document it well to help out your successors), you could use a table lookup:
// Lookup table for fast calculation of bits set in 8-bit unsigned char.
static unsigned char oneBitsInUChar[] = {
// 0 1 2 3 4 5 6 7 8 9 A B C D E F (<- n)
// =====================================================
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, // 0n
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, // 1n
: : :
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8, // Fn
};
// Function for fast calculation of bits set in 16-bit unsigned short.
unsigned char oneBitsInUShort (unsigned short x) {
return oneBitsInUChar [x >> 8]
+ oneBitsInUChar [x & 0xff];
}
// Function for fast calculation of bits set in 32-bit unsigned int.
unsigned char oneBitsInUInt (unsigned int x) {
return oneBitsInUShort (x >> 16)
+ oneBitsInUShort (x & 0xffff);
}
These rely on specific data type sizes so they're not that portable. But, since many performance optimisations aren't portable anyway, that may not be an issue. If you want portability, I'd stick to the readable solution.
if ((value & 1) == 1) { count++; } with count += value & 1? –
Rostrum int cnt=0; for( int b=0; b < 32; b++) if( (val>>b) & 1) cnt++; But I think this question isn't that interesting until speed is a priority. –
Gomphosis unsigned in the function prototype :-) –
Uuge while (value > 0) .. and if ((value & 1) == 1) .. That implies that by "another programmer" you truly mean "another programmer of another language" or "original programmer who forgot C in the meanwhile" while tempting the casual reader to think you are advocating simpler algorithms. It is IDIOMATIC & easier to read while (value) .. and if (value & 1) .. Your true position is "code as would morons". –
Willowwillowy unsigned int count_bits (unsigned int val) { unsigned int n; for (n = 0; val; val >>= 1) n += val & 1; return n; } There .. was that so hard? And I stopped coding in C about 15 years ago, and it's easier to read. Going by your reputation the only rationale I can think of for your original answer is that you were trolling and establishing some kind of a moron honeypot to warn everybody else, lol. –
Willowwillowy count += (value & 1); // add the low bit is more readable than using an if around an increment. Or I guess you could say it's equally readable but a different conceptual algorithm: add all the bits together without their place-values, vs. counting occurrences. –
Grane if (value & 1) is more readable since there's less going on than if ((value & 1) == 1). And especially the value > 0 loop condition is non-obvious vs. value != 0. Maybe that was to match with your original /= 2 division, to cast this as a math problem on arbitrary numbers without any specific base being special, rather than a bit-manipulation exercise using binary numbers in a language where integers are inherently already binary? But still, != 0 makes at least as much sense, and doesn't require thinking through unsigned –
Grane From Hacker's Delight, p. 66, Figure 5-2
int pop(unsigned x)
{
x = x - ((x >> 1) & 0x55555555);
x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
x = (x + (x >> 4)) & 0x0F0F0F0F;
x = x + (x >> 8);
x = x + (x >> 16);
return x & 0x0000003F;
}
Executes in ~20-ish instructions (arch dependent), no branching.
Hacker's Delight is delightful! Highly recommended.
Integer.bitCount(int) uses this same exact implementation. –
Overalls pop instead of population_count (or pop_cnt if you must have an abreviation). @MarcoBolis I presume that will be true of all versions of Java, but officially that would be implementation dependent :) –
Bowlin 0x01010101 constant to sum all 4 bytes into the high byte. (I would have done the x>>16 part first, to make the reduction work by narrowing the valuable part in half twice.) On a CPU without a fast multiplier, yes this is preferable (especially if it can do large shifts efficiently, not like 1 bit per cycle. Or if it has some other way to extract the high half; e.g. on a 16-bit CPU it would already be split –
Grane I think the fastest way—without using lookup tables and popcount—is the following. It counts the set bits with just 12 operations.
int popcount(int v) {
v = v - ((v >> 1) & 0x55555555); // put count of each 2 bits into those 2 bits
v = (v & 0x33333333) + ((v >> 2) & 0x33333333); // put count of each 4 bits into those 4 bits
return ((v + (v >> 4) & 0xF0F0F0F) * 0x1010101) >> 24;
}
It works because you can count the total number of set bits by dividing in two halves, counting the number of set bits in both halves and then adding them up. Also know as Divide and Conquer paradigm. Let's get into detail..
v = v - ((v >> 1) & 0x55555555);
The number of bits in two bits can be 0b00, 0b01 or 0b10. Lets try to work this out on 2 bits..
---------------------------------------------
| v | (v >> 1) & 0b0101 | v - x |
---------------------------------------------
0b00 0b00 0b00
0b01 0b00 0b01
0b10 0b01 0b01
0b11 0b01 0b10
This is what was required: the last column shows the count of set bits in every two bit pair. If the two bit number is >= 2 (0b10) then and produces 0b01, else it produces 0b00.
v = (v & 0x33333333) + ((v >> 2) & 0x33333333);
This statement should be easy to understand. After the first operation we have the count of set bits in every two bits, now we sum up that count in every 4 bits.
v & 0b00110011 //masks out even two bits
(v >> 2) & 0b00110011 // masks out odd two bits
We then sum up the above result, giving us the total count of set bits in 4 bits. The last statement is the most tricky.
c = ((v + (v >> 4) & 0xF0F0F0F) * 0x1010101) >> 24;
Let's break it down further...
v + (v >> 4)
It's similar to the second statement; we are counting the set bits in groups of 4 instead. We know—because of our previous operations—that every nibble has the count of set bits in it. Let's look an example. Suppose we have the byte 0b01000010. It means the first nibble has its 4bits set and the second one has its 2bits set. Now we add those nibbles together.
v = 0b01000010
(v >> 4) = 0b00000100
v + (v >> 4) = 0b01000010 + 0b00000100
It gives us the count of set bits in a byte, in the second nibble 0b01000110 and therefore we mask the first four bytes of all the bytes in the number (discarding them).
0b01000110 & 0x0F = 0b00000110
Now every byte has the count of set bits in it. We need to add them up all together. The trick is to multiply the result by 0b10101010 which has an interesting property. If our number has four bytes, A B C D, it will result in a new number with these bytes A+B+C+D B+C+D C+D D. A 4 byte number can have maximum of 32 bits set, which can be represented as 0b00100000.
All we need now is the first byte which has the sum of all set bits in all the bytes, and we get it by >> 24. This algorithm was designed for 32 bit words but can be easily modified for 64 bit words.
c = about? Looks like is should be eliminated. Further, suggest an extra paren set A"(((v + (v >> 4)) & 0xF0F0F0F) * 0x1010101) >> 24" to avoid some classic warnings. –
Phocine popcount(int v) and popcount(unsigned v). For portability, consider popcount(uint32_t v), etc. Really like the *0x1010101 part. –
Phocine return (((i + (i >> 4)) & 0x0F0F0F0F) * 0x01010101) >> 24; so we don't need to count letters to see what you are actually doing (since you discarded the first 0, I accidentally thought you used the wrong (flipped) bit pattern as mask - that is until I noted there are only 7 letters and not 8). –
Ariose 0x0F0F0F0F was on a separate line, like v = v + (v >> 4) & 0xF0F0F0F; // sum nibbles to bytes. There's no benefit or clarity to jamming it onto the same line as the bytes -> int horizontal sum. It would also make the c = ... stray bit of code stand out more :P –
Grane If you happen to be using Java, the built-in method Integer.bitCount will do that.
I got bored, and timed a billion iterations of three approaches. Compiler is gcc -O3. CPU is whatever they put in the 1st gen Macbook Pro.
Fastest is the following, at 3.7 seconds:
static unsigned char wordbits[65536] = { bitcounts of ints between 0 and 65535 };
static int popcount( unsigned int i )
{
return( wordbits[i&0xFFFF] + wordbits[i>>16] );
}
Second place goes to the same code but looking up 4 bytes instead of 2 halfwords. That took around 5.5 seconds.
Third place goes to the bit-twiddling 'sideways addition' approach, which took 8.6 seconds.
Fourth place goes to GCC's __builtin_popcount(), at a shameful 11 seconds.
The counting one-bit-at-a-time approach was waaaay slower, and I got bored of waiting for it to complete.
So if you care about performance above all else then use the first approach. If you care, but not enough to spend 64Kb of RAM on it, use the second approach. Otherwise use the readable (but slow) one-bit-at-a-time approach.
It's hard to think of a situation where you'd want to use the bit-twiddling approach.
Edit: Similar results here.
unsigned int count_bit(unsigned int x)
{
x = (x & 0x55555555) + ((x >> 1) & 0x55555555);
x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
x = (x & 0x0F0F0F0F) + ((x >> 4) & 0x0F0F0F0F);
x = (x & 0x00FF00FF) + ((x >> 8) & 0x00FF00FF);
x = (x & 0x0000FFFF) + ((x >> 16)& 0x0000FFFF);
return x;
}
Let me explain this algorithm.
This algorithm is based on Divide and Conquer Algorithm. Suppose there is a 8bit integer 213(11010101 in binary), the algorithm works like this(each time merge two neighbor blocks):
+-------------------------------+
| 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | <- x
| 1 0 | 0 1 | 0 1 | 0 1 | <- first time merge
| 0 0 1 1 | 0 0 1 0 | <- second time merge
| 0 0 0 0 0 1 0 1 | <- third time ( answer = 00000101 = 5)
+-------------------------------+
x=... lines here. My edits demangled it some (keeping the optimized logic, improving readability and adding comments), and I added a section that explains the SWAR bithacks involved. This answer is still useful, though, at least for the diagram. Or for a hypothetical 32-bit machine with a slow multiply instruction. –
Grane This is one of those questions where it helps to know your micro-architecture. I just timed two variants under gcc 4.3.3 compiled with -O3 using C++ inlines to eliminate function call overhead, one billion iterations, keeping the running sum of all counts to ensure the compiler doesn't remove anything important, using rdtsc for timing (clock cycle precise).
inline int pop2(unsigned x, unsigned y)
{
x = x - ((x >> 1) & 0x55555555);
y = y - ((y >> 1) & 0x55555555);
x = (x & 0x33333333) + ((x >> 2) & 0x33333333);
y = (y & 0x33333333) + ((y >> 2) & 0x33333333);
x = (x + (x >> 4)) & 0x0F0F0F0F;
y = (y + (y >> 4)) & 0x0F0F0F0F;
x = x + (x >> 8);
y = y + (y >> 8);
x = x + (x >> 16);
y = y + (y >> 16);
return (x+y) & 0x000000FF;
}
The unmodified Hacker's Delight took 12.2 gigacycles. My parallel version (counting twice as many bits) runs in 13.0 gigacycles. 10.5s total elapsed for both together on a 2.4GHz Core Duo. 25 gigacycles = just over 10 seconds at this clock frequency, so I'm confident my timings are right.
This has to do with instruction dependency chains, which are very bad for this algorithm. I could nearly double the speed again by using a pair of 64-bit registers. In fact, if I was clever and added x+y a little sooner I could shave off some shifts. The 64-bit version with some small tweaks would come out about even, but count twice as many bits again.
With 128 bit SIMD registers, yet another factor of two, and the SSE instruction sets often have clever short-cuts, too.
There's no reason for the code to be especially transparent. The interface is simple, the algorithm can be referenced on-line in many places, and it's amenable to comprehensive unit test. The programmer who stumbles upon it might even learn something. These bit operations are extremely natural at the machine level.
OK, I decided to bench the tweaked 64-bit version. For this one sizeof(unsigned long) == 8
inline int pop2(unsigned long x, unsigned long y)
{
x = x - ((x >> 1) & 0x5555555555555555);
y = y - ((y >> 1) & 0x5555555555555555);
x = (x & 0x3333333333333333) + ((x >> 2) & 0x3333333333333333);
y = (y & 0x3333333333333333) + ((y >> 2) & 0x3333333333333333);
x = (x + (x >> 4)) & 0x0F0F0F0F0F0F0F0F;
y = (y + (y >> 4)) & 0x0F0F0F0F0F0F0F0F;
x = x + y;
x = x + (x >> 8);
x = x + (x >> 16);
x = x + (x >> 32);
return x & 0xFF;
}
That looks about right (I'm not testing carefully, though). Now the timings come out at 10.70 gigacycles / 14.1 gigacycles. That later number summed 128 billion bits and corresponds to 5.9s elapsed on this machine. The non-parallel version speeds up a tiny bit because I'm running in 64-bit mode and it likes 64-bit registers slightly better than 32-bit registers.
Let's see if there's a bit more OOO pipelining to be had here. This was a bit more involved, so I actually tested a bit. Each term alone sums to 64, all combined sum to 256.
inline int pop4(unsigned long x, unsigned long y,
unsigned long u, unsigned long v)
{
enum { m1 = 0x5555555555555555,
m2 = 0x3333333333333333,
m3 = 0x0F0F0F0F0F0F0F0F,
m4 = 0x000000FF000000FF };
x = x - ((x >> 1) & m1);
y = y - ((y >> 1) & m1);
u = u - ((u >> 1) & m1);
v = v - ((v >> 1) & m1);
x = (x & m2) + ((x >> 2) & m2);
y = (y & m2) + ((y >> 2) & m2);
u = (u & m2) + ((u >> 2) & m2);
v = (v & m2) + ((v >> 2) & m2);
x = x + y;
u = u + v;
x = (x & m3) + ((x >> 4) & m3);
u = (u & m3) + ((u >> 4) & m3);
x = x + u;
x = x + (x >> 8);
x = x + (x >> 16);
x = x & m4;
x = x + (x >> 32);
return x & 0x000001FF;
}
I was excited for a moment, but it turns out gcc is playing inline tricks with -O3 even though I'm not using the inline keyword in some tests. When I let gcc play tricks, a billion calls to pop4() takes 12.56 gigacycles, but I determined it was folding arguments as constant expressions. A more realistic number appears to be 19.6gc for another 30% speed-up. My test loop now looks like this, making sure each argument is different enough to stop gcc from playing tricks.
hitime b4 = rdtsc();
for (unsigned long i = 10L * 1000*1000*1000; i < 11L * 1000*1000*1000; ++i)
sum += pop4 (i, i^1, ~i, i|1);
hitime e4 = rdtsc();
256 billion bits summed in 8.17s elapsed. Works out to 1.02s for 32 million bits as benchmarked in the 16-bit table lookup. Can't compare directly, because the other bench doesn't give a clock speed, but looks like I've slapped the snot out of the 64KB table edition, which is a tragic use of L1 cache in the first place.
Update: decided to do the obvious and create pop6() by adding four more duplicated lines. Came out to 22.8gc, 384 billion bits summed in 9.5s elapsed. So there's another 20% Now at 800ms for 32 billion bits.
Why not iteratively divide by 2?
count = 0
while n > 0
if (n % 2) == 1
count += 1
n /= 2
I agree that this isn't the fastest, but "best" is somewhat ambiguous. I'd argue though that "best" should have an element of clarity
n always return 0. –
Phocine n%2 and n/2 are only equivalent to n&1 and n>>1 when n >=0. So, with unsigned it's fine (and the example is only really correct with unsigned, anyway). In this example, even with int, the compiler could prove that those ops are never reached unless n>=0, so it's not a reflection on the general case; if compiler can't prove n>=0, you will get something like (n -(n>>31))>>1 for the n/2, and similar weirdness for the n%2. In general case, if( (n%2)!=0) could optimize to (n&1)!=0 but if( (n%2)==1) cannot. –
Gomphosis n%2 == 1 will be false for all negative n, in language like C where integer division truncates toward zero so -3 % 2 == -1. This might work in Python where integer division works differently; based on syntax using only indenting for nesting, it might well be Python, but that (and the reason it works) are not stated in the answer. Using division / remainder makes sense semantically when looking at collections of bits as numbers, but here we really do want to look at it as a collection of bits so shift and AND is most natural. Using arithmetic is an obfuscation. –
Grane The Hacker's Delight bit-twiddling becomes so much clearer when you write out the bit patterns.
unsigned int bitCount(unsigned int x)
{
x = ((x >> 1) & 0b01010101010101010101010101010101)
+ (x & 0b01010101010101010101010101010101);
x = ((x >> 2) & 0b00110011001100110011001100110011)
+ (x & 0b00110011001100110011001100110011);
x = ((x >> 4) & 0b00001111000011110000111100001111)
+ (x & 0b00001111000011110000111100001111);
x = ((x >> 8) & 0b00000000111111110000000011111111)
+ (x & 0b00000000111111110000000011111111);
x = ((x >> 16)& 0b00000000000000001111111111111111)
+ (x & 0b00000000000000001111111111111111);
return x;
}
The first step adds the even bits to the odd bits, producing a sum of bits in each two. The other steps add high-order chunks to low-order chunks, doubling the chunk size all the way up, until we have the final count taking up the entire int.
For a happy medium between a 232 lookup table and iterating through each bit individually:
int bitcount(unsigned int num){
int count = 0;
static int nibblebits[] =
{0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4};
for(; num != 0; num >>= 4)
count += nibblebits[num & 0x0f];
return count;
}
O(floor(log2(num))/4), assuming num can be as arbitrarily large as possible? Because the while loop runs as long as there's a nibble to process? There are floor(log2(num)) bits and floor(log2(num)) / 4 nibbles. Is the reasoning correct? –
Quarterage do{}while loop that doesn't compare/branch until after checking the low 4 bits. Or unroll to check 2x 4 bits on the first iteration. That means the branch-prediction pattern is the same for all inputs from 0..255, and making the branching more predictable is often a Good Thing, when the work saved is much cheaper than a branch mispredict. (Of course that depends on the CPU, and you wouldn't typically use this on a high-end CPU where branch misses are most expensive.) –
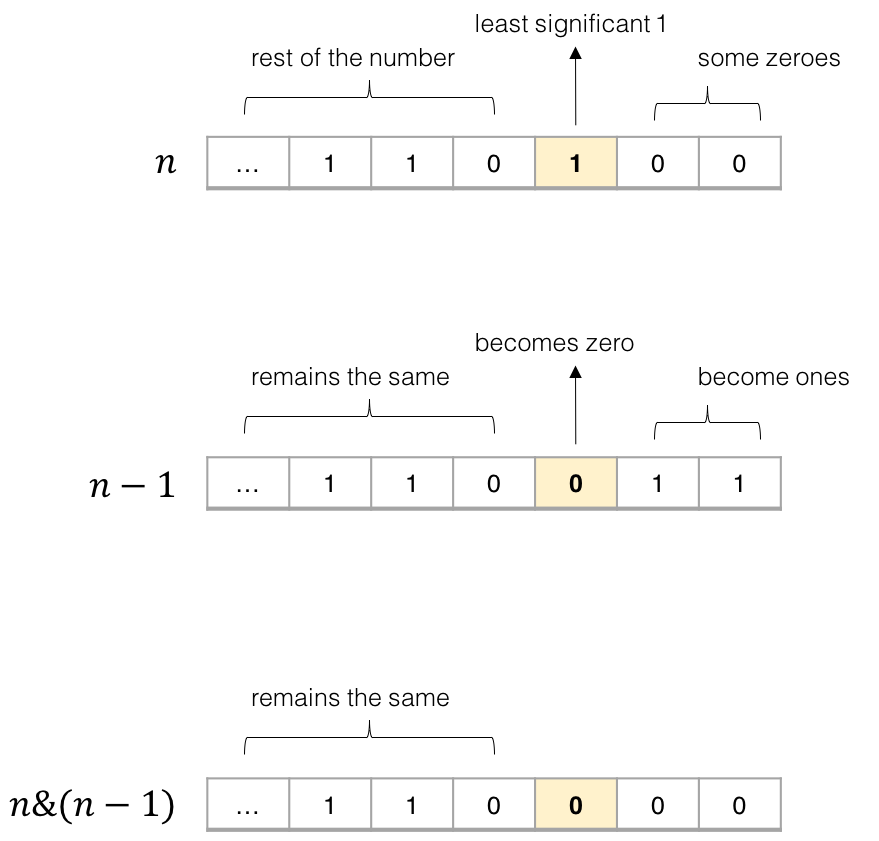
Grane This can be done in O(k), where k is the number of bits set.
int NumberOfSetBits(int n)
{
int count = 0;
while (n){
++ count;
n = (n - 1) & n;
}
return count;
}
n &= (n-1) form. –
Ossein It's not the fastest or best solution, but I found the same question in my way, and I started to think and think. finally I realized that it can be done like this if you get the problem from mathematical side, and draw a graph, then you find that it's a function which has some periodic part, and then you realize the difference between the periods... so here you go:
unsigned int f(unsigned int x)
{
switch (x) {
case 0:
return 0;
case 1:
return 1;
case 2:
return 1;
case 3:
return 2;
default:
return f(x/4) + f(x%4);
}
}
def f(i, d={0:lambda:0, 1:lambda:1, 2:lambda:1, 3:lambda:2}): return d.get(i, lambda: f(i//4) + f(i%4))() –
Alden I think the Brian Kernighan's method will be useful too... It goes through as many iterations as there are set bits. So if we have a 32-bit word with only the high bit set, then it will only go once through the loop.
int countSetBits(unsigned int n) {
unsigned int n; // count the number of bits set in n
unsigned int c; // c accumulates the total bits set in n
for (c=0;n>0;n=n&(n-1)) c++;
return c;
}
Published in 1988, the C Programming Language 2nd Ed. (by Brian W. Kernighan and Dennis M. Ritchie) mentions this in exercise 2-9. On April 19, 2006 Don Knuth pointed out to me that this method "was first published by Peter Wegner in CACM 3 (1960), 322. (Also discovered independently by Derrick Lehmer and published in 1964 in a book edited by Beckenbach.)"
private int get_bits_set(int v)
{
int c; // 'c' accumulates the total bits set in 'v'
for (c = 0; v>0; c++)
{
v &= v - 1; // Clear the least significant bit set
}
return c;
}
The function you are looking for is often called the "sideways sum" or "population count" of a binary number. Knuth discusses it in pre-Fascicle 1A, pp11-12 (although there was a brief reference in Volume 2, 4.6.3-(7).)
The locus classicus is Peter Wegner's article "A Technique for Counting Ones in a Binary Computer", from the Communications of the ACM, Volume 3 (1960) Number 5, page 322. He gives two different algorithms there, one optimized for numbers expected to be "sparse" (i.e., have a small number of ones) and one for the opposite case.
Few open questions:-
we can modify the algo to support the negative number as follows:-
count = 0
while n != 0
if ((n % 2) == 1 || (n % 2) == -1
count += 1
n /= 2
return count
now to overcome the second problem we can write the algo like:-
int bit_count(int num)
{
int count=0;
while(num)
{
num=(num)&(num-1);
count++;
}
return count;
}
for complete reference see :
http://goursaha.freeoda.com/Miscellaneous/IntegerBitCount.html
I use the below code which is more intuitive.
int countSetBits(int n) {
return !n ? 0 : 1 + countSetBits(n & (n-1));
}
Logic : n & (n-1) resets the last set bit of n.
P.S : I know this is not O(1) solution, albeit an interesting solution.
O(ONE-BITS). It is indeed O(1) since there are at most 32 one-bits. –
Accumulator C++20 std::popcount
The following proposal has been merged http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2019/p0553r4.html and should add it to a the <bit> header.
I expect the usage to be like:
#include <bit>
#include <iostream>
int main() {
std::cout << std::popcount(0x55) << std::endl;
}
I'll give it a try when support arrives to GCC, GCC 9.1.0 with g++-9 -std=c++2a still doesn't support it.
The proposal says:
Header:
<bit>namespace std { // 25.5.6, counting template<class T> constexpr int popcount(T x) noexcept;
and:
template<class T> constexpr int popcount(T x) noexcept;Constraints: T is an unsigned integer type (3.9.1 [basic.fundamental]).
Returns: The number of 1 bits in the value of x.
std::rotl and std::rotr were also added to do circular bit rotations: Best practices for circular shift (rotate) operations in C++
You can do:
while(n){
n = n & (n-1);
count++;
}
The logic behind this is the bits of n-1 is inverted from rightmost set bit of n.
If n=6, i.e., 110 then 5 is 101 the bits are inverted from rightmost set bit of n.
So if we & these two we will make the rightmost bit 0 in every iteration and always go to the next rightmost set bit. Hence, counting the set bit. The worst time complexity will be O(log n) when every bit is set.
if you're using C++ another option is to use template metaprogramming:
// recursive template to sum bits in an int
template <int BITS>
int countBits(int val) {
// return the least significant bit plus the result of calling ourselves with
// .. the shifted value
return (val & 0x1) + countBits<BITS-1>(val >> 1);
}
// template specialisation to terminate the recursion when there's only one bit left
template<>
int countBits<1>(int val) {
return val & 0x1;
}
usage would be:
// to count bits in a byte/char (this returns 8)
countBits<8>( 255 )
// another byte (this returns 7)
countBits<8>( 254 )
// counting bits in a word/short (this returns 1)
countBits<16>( 256 )
you could of course further expand this template to use different types (even auto-detecting bit size) but I've kept it simple for clarity.
edit: forgot to mention this is good because it should work in any C++ compiler and it basically just unrolls your loop for you if a constant value is used for the bit count (in other words, I'm pretty sure it's the fastest general method you'll find)
constexpr though. –
Chromonema I wrote a fast bitcount macro for RISC machines in about 1990. It does not use advanced arithmetic (multiplication, division, %), memory fetches (way too slow), branches (way too slow), but it does assume the CPU has a 32-bit barrel shifter (in other words, >> 1 and >> 32 take the same amount of cycles.) It assumes that small constants (such as 6, 12, 24) cost nothing to load into the registers, or are stored in temporaries and reused over and over again.
With these assumptions, it counts 32 bits in about 16 cycles/instructions on most RISC machines. Note that 15 instructions/cycles is close to a lower bound on the number of cycles or instructions, because it seems to take at least 3 instructions (mask, shift, operator) to cut the number of addends in half, so log_2(32) = 5, 5 x 3 = 15 instructions is a quasi-lowerbound.
#define BitCount(X,Y) \
Y = X - ((X >> 1) & 033333333333) - ((X >> 2) & 011111111111); \
Y = ((Y + (Y >> 3)) & 030707070707); \
Y = (Y + (Y >> 6)); \
Y = (Y + (Y >> 12) + (Y >> 24)) & 077;
Here is a secret to the first and most complex step:
input output
AB CD Note
00 00 = AB
01 01 = AB
10 01 = AB - (A >> 1) & 0x1
11 10 = AB - (A >> 1) & 0x1
so if I take the 1st column (A) above, shift it right 1 bit, and subtract it from AB, I get the output (CD). The extension to 3 bits is similar; you can check it with an 8-row boolean table like mine above if you wish.
What do you means with "Best algorithm"? The shorted code or the fasted code? Your code look very elegant and it has a constant execution time. The code is also very short.
But if the speed is the major factor and not the code size then I think the follow can be faster:
static final int[] BIT_COUNT = { 0, 1, 1, ... 256 values with a bitsize of a byte ... };
static int bitCountOfByte( int value ){
return BIT_COUNT[ value & 0xFF ];
}
static int bitCountOfInt( int value ){
return bitCountOfByte( value )
+ bitCountOfByte( value >> 8 )
+ bitCountOfByte( value >> 16 )
+ bitCountOfByte( value >> 24 );
}
I think that this will not more faster for a 64 bit value but a 32 bit value can be faster.
I always use this in competitive programming, and it's easy to write and is efficient:
#include <bits/stdc++.h>
using namespace std;
int countOnes(int n) {
bitset<32> b(n);
return b.count();
}
I found an implementation of bit counting in an array with using of SIMD instruction (SSSE3 and AVX2). It has in 2-2.5 times better performance than if it will use __popcnt64 intrinsic function.
SSSE3 version:
#include <smmintrin.h>
#include <stdint.h>
const __m128i Z = _mm_set1_epi8(0x0);
const __m128i F = _mm_set1_epi8(0xF);
//Vector with pre-calculated bit count:
const __m128i T = _mm_setr_epi8(0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4);
uint64_t BitCount(const uint8_t * src, size_t size)
{
__m128i _sum = _mm128_setzero_si128();
for (size_t i = 0; i < size; i += 16)
{
//load 16-byte vector
__m128i _src = _mm_loadu_si128((__m128i*)(src + i));
//get low 4 bit for every byte in vector
__m128i lo = _mm_and_si128(_src, F);
//sum precalculated value from T
_sum = _mm_add_epi64(_sum, _mm_sad_epu8(Z, _mm_shuffle_epi8(T, lo)));
//get high 4 bit for every byte in vector
__m128i hi = _mm_and_si128(_mm_srli_epi16(_src, 4), F);
//sum precalculated value from T
_sum = _mm_add_epi64(_sum, _mm_sad_epu8(Z, _mm_shuffle_epi8(T, hi)));
}
uint64_t sum[2];
_mm_storeu_si128((__m128i*)sum, _sum);
return sum[0] + sum[1];
}
AVX2 version:
#include <immintrin.h>
#include <stdint.h>
const __m256i Z = _mm256_set1_epi8(0x0);
const __m256i F = _mm256_set1_epi8(0xF);
//Vector with pre-calculated bit count:
const __m256i T = _mm256_setr_epi8(0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4);
uint64_t BitCount(const uint8_t * src, size_t size)
{
__m256i _sum = _mm256_setzero_si256();
for (size_t i = 0; i < size; i += 32)
{
//load 32-byte vector
__m256i _src = _mm256_loadu_si256((__m256i*)(src + i));
//get low 4 bit for every byte in vector
__m256i lo = _mm256_and_si256(_src, F);
//sum precalculated value from T
_sum = _mm256_add_epi64(_sum, _mm256_sad_epu8(Z, _mm256_shuffle_epi8(T, lo)));
//get high 4 bit for every byte in vector
__m256i hi = _mm256_and_si256(_mm256_srli_epi16(_src, 4), F);
//sum precalculated value from T
_sum = _mm256_add_epi64(_sum, _mm256_sad_epu8(Z, _mm256_shuffle_epi8(T, hi)));
}
uint64_t sum[4];
_mm256_storeu_si256((__m256i*)sum, _sum);
return sum[0] + sum[1] + sum[2] + sum[3];
}
A fast C# solution using a pre-calculated table of Byte bit counts with branching on the input size.
public static class BitCount
{
public static uint GetSetBitsCount(uint n)
{
var counts = BYTE_BIT_COUNTS;
return n <= 0xff ? counts[n]
: n <= 0xffff ? counts[n & 0xff] + counts[n >> 8]
: n <= 0xffffff ? counts[n & 0xff] + counts[(n >> 8) & 0xff] + counts[(n >> 16) & 0xff]
: counts[n & 0xff] + counts[(n >> 8) & 0xff] + counts[(n >> 16) & 0xff] + counts[(n >> 24) & 0xff];
}
public static readonly uint[] BYTE_BIT_COUNTS =
{
0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7,
4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8
};
}
(0xe994 >>(k*2))&3,without memory access... –
Gomphosis BitOperations.PopCount((uint)number); –
Bolivar Java JDK1.5
Integer.bitCount(n);
where n is the number whose 1's are to be counted.
check also,
Integer.highestOneBit(n);
Integer.lowestOneBit(n);
Integer.numberOfLeadingZeros(n);
Integer.numberOfTrailingZeros(n);
//Beginning with the value 1, rotate left 16 times
n = 1;
for (int i = 0; i < 16; i++) {
n = Integer.rotateLeft(n, 1);
System.out.println(n);
}
I'm particularly fond of this example from the fortune file:
#define BITCOUNT(x) (((BX_(x)+(BX_(x)>>4)) & 0x0F0F0F0F) % 255)
#define BX_(x) ((x) - (((x)>>1)&0x77777777)
- (((x)>>2)&0x33333333)
- (((x)>>3)&0x11111111))
I like it best because it's so pretty!
There are many algorithm to count the set bits; but i think the best one is the faster one! You can see the detailed on this page:
I suggest this one:
Counting bits set in 14, 24, or 32-bit words using 64-bit instructions
unsigned int v; // count the number of bits set in v
unsigned int c; // c accumulates the total bits set in v
// option 1, for at most 14-bit values in v:
c = (v * 0x200040008001ULL & 0x111111111111111ULL) % 0xf;
// option 2, for at most 24-bit values in v:
c = ((v & 0xfff) * 0x1001001001001ULL & 0x84210842108421ULL) % 0x1f;
c += (((v & 0xfff000) >> 12) * 0x1001001001001ULL & 0x84210842108421ULL)
% 0x1f;
// option 3, for at most 32-bit values in v:
c = ((v & 0xfff) * 0x1001001001001ULL & 0x84210842108421ULL) % 0x1f;
c += (((v & 0xfff000) >> 12) * 0x1001001001001ULL & 0x84210842108421ULL) %
0x1f;
c += ((v >> 24) * 0x1001001001001ULL & 0x84210842108421ULL) % 0x1f;
This method requires a 64-bit CPU with fast modulus division to be efficient. The first option takes only 3 operations; the second option takes 10; and the third option takes 15.
Here is a portable module ( ANSI-C ) which can benchmark each of your algorithms on any architecture.
Your CPU has 9 bit bytes? No problem :-) At the moment it implements 2 algorithms, the K&R algorithm and a byte wise lookup table. The lookup table is on average 3 times faster than the K&R algorithm. If someone can figure a way to make the "Hacker's Delight" algorithm portable feel free to add it in.
#ifndef _BITCOUNT_H_
#define _BITCOUNT_H_
/* Return the Hamming Wieght of val, i.e. the number of 'on' bits. */
int bitcount( unsigned int );
/* List of available bitcount algorithms.
* onTheFly: Calculate the bitcount on demand.
*
* lookupTalbe: Uses a small lookup table to determine the bitcount. This
* method is on average 3 times as fast as onTheFly, but incurs a small
* upfront cost to initialize the lookup table on the first call.
*
* strategyCount is just a placeholder.
*/
enum strategy { onTheFly, lookupTable, strategyCount };
/* String represenations of the algorithm names */
extern const char *strategyNames[];
/* Choose which bitcount algorithm to use. */
void setStrategy( enum strategy );
#endif
.
#include <limits.h>
#include "bitcount.h"
/* The number of entries needed in the table is equal to the number of unique
* values a char can represent which is always UCHAR_MAX + 1*/
static unsigned char _bitCountTable[UCHAR_MAX + 1];
static unsigned int _lookupTableInitialized = 0;
static int _defaultBitCount( unsigned int val ) {
int count;
/* Starting with:
* 1100 - 1 == 1011, 1100 & 1011 == 1000
* 1000 - 1 == 0111, 1000 & 0111 == 0000
*/
for ( count = 0; val; ++count )
val &= val - 1;
return count;
}
/* Looks up each byte of the integer in a lookup table.
*
* The first time the function is called it initializes the lookup table.
*/
static int _tableBitCount( unsigned int val ) {
int bCount = 0;
if ( !_lookupTableInitialized ) {
unsigned int i;
for ( i = 0; i != UCHAR_MAX + 1; ++i )
_bitCountTable[i] =
( unsigned char )_defaultBitCount( i );
_lookupTableInitialized = 1;
}
for ( ; val; val >>= CHAR_BIT )
bCount += _bitCountTable[val & UCHAR_MAX];
return bCount;
}
static int ( *_bitcount ) ( unsigned int ) = _defaultBitCount;
const char *strategyNames[] = { "onTheFly", "lookupTable" };
void setStrategy( enum strategy s ) {
switch ( s ) {
case onTheFly:
_bitcount = _defaultBitCount;
break;
case lookupTable:
_bitcount = _tableBitCount;
break;
case strategyCount:
break;
}
}
/* Just a forwarding function which will call whichever version of the
* algorithm has been selected by the client
*/
int bitcount( unsigned int val ) {
return _bitcount( val );
}
#ifdef _BITCOUNT_EXE_
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
/* Use the same sequence of pseudo random numbers to benmark each Hamming
* Weight algorithm.
*/
void benchmark( int reps ) {
clock_t start, stop;
int i, j;
static const int iterations = 1000000;
for ( j = 0; j != strategyCount; ++j ) {
setStrategy( j );
srand( 257 );
start = clock( );
for ( i = 0; i != reps * iterations; ++i )
bitcount( rand( ) );
stop = clock( );
printf
( "\n\t%d psudoe-random integers using %s: %f seconds\n\n",
reps * iterations, strategyNames[j],
( double )( stop - start ) / CLOCKS_PER_SEC );
}
}
int main( void ) {
int option;
while ( 1 ) {
printf( "Menu Options\n"
"\t1.\tPrint the Hamming Weight of an Integer\n"
"\t2.\tBenchmark Hamming Weight implementations\n"
"\t3.\tExit ( or cntl-d )\n\n\t" );
if ( scanf( "%d", &option ) == EOF )
break;
switch ( option ) {
case 1:
printf( "Please enter the integer: " );
if ( scanf( "%d", &option ) != EOF )
printf
( "The Hamming Weight of %d ( 0x%X ) is %d\n\n",
option, option, bitcount( option ) );
break;
case 2:
printf
( "Please select number of reps ( in millions ): " );
if ( scanf( "%d", &option ) != EOF )
benchmark( option );
break;
case 3:
goto EXIT;
break;
default:
printf( "Invalid option\n" );
}
}
EXIT:
printf( "\n" );
return 0;
}
#endif
Naive Solution
Time Complexity is O(no. of bits in n)
int countSet(unsigned int n)
{
int res=0;
while(n!=0){
res += (n&1);
n >>= 1; // logical right shift, like C unsigned or Java >>>
}
return res;
}
Brian Kerningam's algorithm
Time Complexity is O(no of set bits in n)
int countSet(unsigned int n)
{
int res=0;
while(n != 0)
{
n = (n & (n-1));
res++;
}
return res;
}
Lookup table method for 32-bit number- In this method we break the 32-bit number into chunks of four, 8-bit numbers
Time Complexity is O(1)
static unsigned char table[256]; /* the table size is 256,
the number of values i&0xFF (8 bits) can have */
void initialize() //holds the number of set bits from 0 to 255
{
table[0]=0;
for(unsigned int i=1;i<256;i++)
table[i]=(i&1)+table[i>>1];
}
int countSet(unsigned int n)
{
// 0xff is hexadecimal representation of 8 set bits.
int res=table[n & 0xff];
n=n>>8;
res=res+ table[n & 0xff];
n=n>>8;
res=res+ table[n & 0xff];
n=n>>8;
res=res+ table[n & 0xff];
return res;
}
32-bit or not ? I just came with this method in Java after reading "cracking the coding interview" 4th edition exercice 5.5 ( chap 5: Bit Manipulation). If the least significant bit is 1 increment count, then right-shift the integer.
public static int bitCount( int n){
int count = 0;
for (int i=n; i!=0; i = i >> 1){
count += i & 1;
}
return count;
}
I think this one is more intuitive than the solutions with constant 0x33333333 no matter how fast they are. It depends on your definition of "best algorithm" .
bitCount(), the for loop never terminates when n < 0. –
Phocine def hammingWeight(n: int) -> int:
sums = 0
while (n!=0):
sums+=1
n = n &(n-1)
return sums
In the binary representation, the least significant 1-bit in n always corresponds to a 0-bit in n - 1. Therefore, anding the two numbers n and n - 1 always flips the least significant 1-bit in n to 0, and keeps all other bits the same.
int countBits(int x)
{
int n = 0;
if (x) do n++;
while(x=x&(x-1));
return n;
}
Or also:
int countBits(int x) { return (x)? 1+countBits(x&(x-1)): 0; }
7 1/2 years after my original answer, @PeterMortensen questioned if this was even valid C syntax. I posted a link to an online compiler showing that it is in fact perfectly valid syntax (code below).
#include <stdio.h>
int countBits(int x)
{
int n = 0;
if (x) do n++; /* Totally Normal Valid code. */
while(x=x&(x-1)); /* Nothing to see here. */
return n;
}
int main(void) {
printf("%d\n", countBits(25));
return 0;
}
3
If you want to re-write it for clarity, it would look like:
if (x)
{
do
{
n++;
} while(x=x&(x-1));
}
But that seems excessive to my eye.
However, I've also realized the function can be made shorter, but perhaps more cryptic, written as:
int countBits(int x)
{
int n = 0;
while (x) x=(n++,x&(x-1));
return n;
}
if (x) do n++; accepted? Does it actually compile? –
Unpeg Personally I use this :
public static int myBitCount(long L){
int count = 0;
while (L != 0) {
count++;
L ^= L & -L;
}
return count;
}
I am providing one more unmentioned algorithm, called Parallel, taken from here. The nice point about it that it is generic, meaning that the code is the same for bit sizes 8, 16, 32, 64, and 128.
I checked the correctness of its values and timings on an amount of 2^26 numbers for bits sizes 8, 16, 32, and 64. See the timings below.
This algorithm is a first code snippet. The other two are mentioned here just for reference, because I tested and compared to them.
Algorithms are coded in C++, to be generic, but it can be easily adopted to old C.
#include <type_traits>
#include <cstdint>
template <typename IntT>
inline size_t PopCntParallel(IntT n) {
// https://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetParallel
using T = std::make_unsigned_t<IntT>;
T v = T(n);
v = v - ((v >> 1) & (T)~(T)0/3); // temp
v = (v & (T)~(T)0/15*3) + ((v >> 2) & (T)~(T)0/15*3); // temp
v = (v + (v >> 4)) & (T)~(T)0/255*15; // temp
return size_t((T)(v * ((T)~(T)0/255)) >> (sizeof(T) - 1) * 8); // count
}
Below are two algorithms that I compared with. One is the Kernighan simple method with a loop, taken from here.
template <typename IntT>
inline size_t PopCntKernighan(IntT n) {
// http://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetKernighan
using T = std::make_unsigned_t<IntT>;
T v = T(n);
size_t c;
for (c = 0; v; ++c)
v &= v - 1; // Clear the least significant bit set
return c;
}
Another one is using built-in __popcnt16()/__popcnt()/__popcnt64() MSVC's intrinsic (doc here). Or __builtin_popcount of CLang/GCC (doc here). This intrinsic should provide a very optimized version, possibly hardware:
#ifdef _MSC_VER
// https://learn.microsoft.com/en-us/cpp/intrinsics/popcnt16-popcnt-popcnt64?view=msvc-160
#include <intrin.h>
#define popcnt16 __popcnt16
#define popcnt32 __popcnt
#define popcnt64 __popcnt64
#else
// https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html
#define popcnt16 __builtin_popcount
#define popcnt32 __builtin_popcount
#define popcnt64 __builtin_popcountll
#endif
template <typename IntT>
inline size_t PopCntBuiltin(IntT n) {
using T = std::make_unsigned_t<IntT>;
T v = T(n);
if constexpr(sizeof(IntT) <= 2)
return popcnt16(uint16_t(v));
else if constexpr(sizeof(IntT) <= 4)
return popcnt32(uint32_t(v));
else if constexpr(sizeof(IntT) <= 8)
return popcnt64(uint64_t(v));
else
static_assert([]{ return false; }());
}
Below are the timings, in nanoseconds per one number. All timings are done for 2^26 random numbers. Timings are compared for all three algorithms and all bit sizes among 8, 16, 32, and 64. In sum, all tests took 16 seconds on my machine. The high-resolution clock was used.
08 bit Builtin 8.2 ns
08 bit Parallel 8.2 ns
08 bit Kernighan 26.7 ns
16 bit Builtin 7.7 ns
16 bit Parallel 7.7 ns
16 bit Kernighan 39.7 ns
32 bit Builtin 7.0 ns
32 bit Parallel 7.0 ns
32 bit Kernighan 47.9 ns
64 bit Builtin 7.5 ns
64 bit Parallel 7.5 ns
64 bit Kernighan 59.4 ns
128 bit Builtin 7.8 ns
128 bit Parallel 13.8 ns
128 bit Kernighan 127.6 ns
As one can see, the provided Parallel algorithm (first among three) is as good as MSVC's/CLang's intrinsic.
For reference, below is full code that I used to test speed/time/correctness of all functions.
As a bonus this code (unlike short code snippets above) also tests 128 bit size, but only under CLang/GCC (not MSVC), as they have unsigned __int128.
#include <type_traits>
#include <cstdint>
using std::size_t;
#if defined(_MSC_VER) && !defined(__clang__)
#define IS_MSVC 1
#else
#define IS_MSVC 0
#endif
#if IS_MSVC
#define HAS128 false
#else
using int128_t = __int128;
using uint128_t = unsigned __int128;
#define HAS128 true
#endif
template <typename T> struct UnSignedT { using type = std::make_unsigned_t<T>; };
#if HAS128
template <> struct UnSignedT<int128_t> { using type = uint128_t; };
template <> struct UnSignedT<uint128_t> { using type = uint128_t; };
#endif
template <typename T> using UnSigned = typename UnSignedT<T>::type;
template <typename IntT>
inline size_t PopCntParallel(IntT n) {
// https://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetParallel
using T = UnSigned<IntT>;
T v = T(n);
v = v - ((v >> 1) & (T)~(T)0/3); // temp
v = (v & (T)~(T)0/15*3) + ((v >> 2) & (T)~(T)0/15*3); // temp
v = (v + (v >> 4)) & (T)~(T)0/255*15; // temp
return size_t((T)(v * ((T)~(T)0/255)) >> (sizeof(T) - 1) * 8); // count
}
template <typename IntT>
inline size_t PopCntKernighan(IntT n) {
// http://graphics.stanford.edu/~seander/bithacks.html#CountBitsSetKernighan
using T = UnSigned<IntT>;
T v = T(n);
size_t c;
for (c = 0; v; ++c)
v &= v - 1; // Clear the least significant bit set
return c;
}
#if IS_MSVC
// https://learn.microsoft.com/en-us/cpp/intrinsics/popcnt16-popcnt-popcnt64?view=msvc-160
#include <intrin.h>
#define popcnt16 __popcnt16
#define popcnt32 __popcnt
#define popcnt64 __popcnt64
#else
// https://gcc.gnu.org/onlinedocs/gcc/Other-Builtins.html
#define popcnt16 __builtin_popcount
#define popcnt32 __builtin_popcount
#define popcnt64 __builtin_popcountll
#endif
#define popcnt128(x) (popcnt64(uint64_t(x)) + popcnt64(uint64_t(x >> 64)))
template <typename IntT>
inline size_t PopCntBuiltin(IntT n) {
using T = UnSigned<IntT>;
T v = T(n);
if constexpr(sizeof(IntT) <= 2)
return popcnt16(uint16_t(v));
else if constexpr(sizeof(IntT) <= 4)
return popcnt32(uint32_t(v));
else if constexpr(sizeof(IntT) <= 8)
return popcnt64(uint64_t(v));
else if constexpr(sizeof(IntT) <= 16)
return popcnt128(uint128_t(v));
else
static_assert([]{ return false; }());
}
#include <random>
#include <vector>
#include <chrono>
#include <string>
#include <iostream>
#include <iomanip>
#include <map>
inline double Time() {
static auto const gtb = std::chrono::high_resolution_clock::now();
return std::chrono::duration_cast<std::chrono::duration<double>>(
std::chrono::high_resolution_clock::now() - gtb).count();
}
template <typename T, typename F>
void Test(std::string const & name, F f) {
std::mt19937_64 rng{123};
size_t constexpr bit_size = sizeof(T) * 8, ntests = 1 << 6, nnums = 1 << 14;
std::vector<T> nums(nnums);
for (size_t i = 0; i < nnums; ++i)
nums[i] = T(rng() % ~T(0));
static std::map<size_t, size_t> times;
double min_time = 1000;
for (size_t i = 0; i < ntests; ++i) {
double timer = Time();
size_t sum = 0;
for (size_t j = 0; j < nnums; j += 4)
sum += f(nums[j + 0]) + f(nums[j + 1]) + f(nums[j + 2]) + f(nums[j + 3]);
auto volatile vsum = sum;
min_time = std::min(min_time, (Time() - timer) / nnums);
if (times.count(bit_size) && times.at(bit_size) != sum)
std::cout << "Wrong bit cnt checksum!" << std::endl;
times[bit_size] = sum;
}
std::cout << std::setw(2) << std::setfill('0') << bit_size
<< " bit " << name << " " << std::fixed << std::setprecision(1)
<< min_time * 1000000000 << " ns" << std::endl;
}
int main() {
#define TEST(T) \
Test<T>("Builtin", PopCntBuiltin<T>); \
Test<T>("Parallel", PopCntParallel<T>); \
Test<T>("Kernighan", PopCntKernighan<T>); \
std::cout << std::endl;
TEST(uint8_t); TEST(uint16_t); TEST(uint32_t); TEST(uint64_t);
#if HAS128
TEST(uint128_t);
#endif
#undef TEST
}
From Python 3.10 onwards, you will be able to use the int.bit_count() function, but for the time being, you can define this function yourself.
def bit_count(integer):
return bin(integer).count("1")
You can use built in function named __builtin_popcount(). There is no__builtin_popcount in C++ but it is a built in function of GCC compiler. This function return the number of set bit in an integer.
int __builtin_popcount (unsigned int x);
Reference : Bit Twiddling Hacks
Another Hamming weight algorithm if you're on a BMI2 capable CPU:
the_weight = __tzcnt_u64(~_pext_u64(data[i], data[i]));
popcnt. pext same,same to pack the bits could be an interesting building-block for something else, but tzcnt and pext both run on the same port as popcnt on Intel CPUs, and pext is very slow on AMD. (agner.org/optimize). You can sort of emulate pext x,x with (1ULL << popcnt(x)) - 1, except for the x==0 case. x86 shifts can't shift out all the bits, because they mask the shift count, and you have to watch out for C undefined behaviour with out of range counts. –
Grane int bitcount(unsigned int n)
{
int count=0;
while(n)
{
count += n & 0x1u;
n >>= 1;
}
return count;
}
Iterated 'count' runs in time proportional to the total number of bits. It simply loops through all the bits, terminating slightly earlier because of the while condition. Useful, if 1'S or the set bits are sparse and among the least significant bits.
Here is a solution that has not been mentioned so far, using bitfields. The following program counts the set bits in an array of 100000000 16-bit integers using 4 different methods. Timing results are given in parentheses (on MacOSX, with gcc -O3):
#include <stdio.h>
#include <stdlib.h>
#define LENGTH 100000000
typedef struct {
unsigned char bit0 : 1;
unsigned char bit1 : 1;
unsigned char bit2 : 1;
unsigned char bit3 : 1;
unsigned char bit4 : 1;
unsigned char bit5 : 1;
unsigned char bit6 : 1;
unsigned char bit7 : 1;
} bits;
unsigned char sum_bits(const unsigned char x) {
const bits *b = (const bits*) &x;
return b->bit0 + b->bit1 + b->bit2 + b->bit3 \
+ b->bit4 + b->bit5 + b->bit6 + b->bit7;
}
int NumberOfSetBits(int i) {
i = i - ((i >> 1) & 0x55555555);
i = (i & 0x33333333) + ((i >> 2) & 0x33333333);
return (((i + (i >> 4)) & 0x0F0F0F0F) * 0x01010101) >> 24;
}
#define out(s) \
printf("bits set: %lu\nbits counted: %lu\n", 8*LENGTH*sizeof(short)*3/4, s);
int main(int argc, char **argv) {
unsigned long i, s;
unsigned short *x = malloc(LENGTH*sizeof(short));
unsigned char lut[65536], *p;
unsigned short *ps;
int *pi;
/* set 3/4 of the bits */
for (i=0; i<LENGTH; ++i)
x[i] = 0xFFF0;
/* sum_bits (1.772s) */
for (i=LENGTH*sizeof(short), p=(unsigned char*) x, s=0; i--; s+=sum_bits(*p++));
out(s);
/* NumberOfSetBits (0.404s) */
for (i=LENGTH*sizeof(short)/sizeof(int), pi=(int*)x, s=0; i--; s+=NumberOfSetBits(*pi++));
out(s);
/* populate lookup table */
for (i=0, p=(unsigned char*) &i; i<sizeof(lut); ++i)
lut[i] = sum_bits(p[0]) + sum_bits(p[1]);
/* 256-bytes lookup table (0.317s) */
for (i=LENGTH*sizeof(short), p=(unsigned char*) x, s=0; i--; s+=lut[*p++]);
out(s);
/* 65536-bytes lookup table (0.250s) */
for (i=LENGTH, ps=x, s=0; i--; s+=lut[*ps++]);
out(s);
free(x);
return 0;
}
While the bitfield version is very readable, the timing results show that it is over 4x slower than NumberOfSetBits(). The lookup-table based implementations are still quite a bit faster, in particular with a 65 kB table.
In C# what about an one liner:
BitOperations.PopCount(Mask);
Returns the population count (number of bits set) of a mask. Similar in behavior to the x86 instruction POPCNT. Compatible with x64! It uses an intrinsic (built-in instruction of the X86 architecture) to count the number of bits very fast in a 32 bit or 64 bit value.
NOTE: BitOperations.PopCount() is not CLS compliant. Take this under consideration.
Cheers
I'll contribute to @Arty's answer
__popcnt16()/__popcnt()/__popcnt64()MSVC's intrinsic (doc here)
popcnt instruction, as noted in "Remarks" section, is available as part of SSE4 instruction set and there is a relatively high chance of it not being available.
If you run code that uses these intrinsics on hardware that doesn't support the popcnt instruction, the results are unpredictable.
So, you need to implement a check as per "Remarks" section:
To determine hardware support for the popcnt instruction, call the __cpuid intrinsic with InfoType=0x00000001 and check bit 23 of CPUInfo[2] (ECX). This bit is 1 if the instruction is supported, and 0 otherwise.
Here's how you do it:
unsigned popcnt(const unsigned input)
{
struct cpuinfo_t
{
union
{
int regs[4];
struct
{
long eax, ebx, ecx, edx;
};
};
cpuinfo_t() noexcept : regs() {}
}
cpuinfo;
// EAX=1: Processor Info and Feature Bits
__cpuid(cpuinfo.regs, 1);
// ECX bit 23: popcnt
if (_bittest(&cpuinfo.ecx, 23))
{
return __popcnt(input);
}
// Choose any fallback implementation you like, there's already a ton of them
unsigned num = input;
num = (num & 0x55555555) + (num >> 1 & 0x55555555);
num = (num & 0x33333333) + (num >> 2 & 0x33333333);
num = (num & 0x0F0F0F0F) + (num >> 4 & 0x0F0F0F0F);
num = (num & 0x00FF00FF) + (num >> 8 & 0x00FF00FF);
num = (num & 0x0000FFFF) + (num >> 16 & 0x0000FFFF);
return num;
}
set counter = 0.
repeat counting till N is not zero.
check last bit. if last bit = 1 , increment counter
Discard last digit of N.
int countSetBits(unsigned int n){
int count = 0;
while(n!=0){
count += n&1;
n = n >>1;
}
return count;
}
Let's use this function.
int main(){
int x = 5;
cout<<countSetBits(x);
return 0;
}
Output: 2
Because 5 has 2 bits set in binary representation (101).
You can run the code here.
For those who want it in C++11 for any unsigned integer type as a consexpr function (tacklelib/include/tacklelib/utility/math.hpp):
#include <stdint.h>
#include <limits>
#include <type_traits>
const constexpr uint32_t uint32_max = (std::numeric_limits<uint32_t>::max)();
namespace detail
{
template <typename T>
inline constexpr T _count_bits_0(const T & v)
{
return v - ((v >> 1) & 0x55555555);
}
template <typename T>
inline constexpr T _count_bits_1(const T & v)
{
return (v & 0x33333333) + ((v >> 2) & 0x33333333);
}
template <typename T>
inline constexpr T _count_bits_2(const T & v)
{
return (v + (v >> 4)) & 0x0F0F0F0F;
}
template <typename T>
inline constexpr T _count_bits_3(const T & v)
{
return v + (v >> 8);
}
template <typename T>
inline constexpr T _count_bits_4(const T & v)
{
return v + (v >> 16);
}
template <typename T>
inline constexpr T _count_bits_5(const T & v)
{
return v & 0x0000003F;
}
template <typename T, bool greater_than_uint32>
struct _impl
{
static inline constexpr T _count_bits_with_shift(const T & v)
{
return
detail::_count_bits_5(
detail::_count_bits_4(
detail::_count_bits_3(
detail::_count_bits_2(
detail::_count_bits_1(
detail::_count_bits_0(v)))))) + count_bits(v >> 32);
}
};
template <typename T>
struct _impl<T, false>
{
static inline constexpr T _count_bits_with_shift(const T & v)
{
return 0;
}
};
}
template <typename T>
inline constexpr T count_bits(const T & v)
{
static_assert(std::is_integral<T>::value, "type T must be an integer");
static_assert(!std::is_signed<T>::value, "type T must be not signed");
return uint32_max >= v ?
detail::_count_bits_5(
detail::_count_bits_4(
detail::_count_bits_3(
detail::_count_bits_2(
detail::_count_bits_1(
detail::_count_bits_0(v)))))) :
detail::_impl<T, sizeof(uint32_t) < sizeof(v)>::_count_bits_with_shift(v);
}
Plus tests in google test library:
#include <stdlib.h>
#include <time.h>
namespace {
template <typename T>
inline uint32_t _test_count_bits(const T & v)
{
uint32_t count = 0;
T n = v;
while (n > 0) {
if (n % 2) {
count += 1;
}
n /= 2;
}
return count;
}
}
TEST(FunctionsTest, random_count_bits_uint32_100K)
{
srand(uint_t(time(NULL)));
for (uint32_t i = 0; i < 100000; i++) {
const uint32_t r = uint32_t(rand()) + (uint32_t(rand()) << 16);
ASSERT_EQ(_test_count_bits(r), count_bits(r));
}
}
TEST(FunctionsTest, random_count_bits_uint64_100K)
{
srand(uint_t(time(NULL)));
for (uint32_t i = 0; i < 100000; i++) {
const uint64_t r = uint64_t(rand()) + (uint64_t(rand()) << 16) + (uint64_t(rand()) << 32) + (uint64_t(rand()) << 48);
ASSERT_EQ(_test_count_bits(r), count_bits(r));
}
}
Kotlin pre 1.4
fun NumberOfSetBits(i: Int): Int {
var i = i
i -= (i ushr 1 and 0x55555555)
i = (i and 0x33333333) + (i ushr 2 and 0x33333333)
return (i + (i ushr 4) and 0x0F0F0F0F) * 0x01010101 ushr 24
}
This is more or less a copy of the answer seen in the top answer.
It is with the Java fixes and is then converted using the converter in the IntelliJ IDEA Community Edition
1.4 and beyond (as of 2021-05-05 - it could change in the future).
fun NumberOfSetBits(i: Int): Int {
return i.countOneBits()
}
Under the hood it uses Integer.bitCount as seen here:
@SinceKotlin("1.4")
@WasExperimental(ExperimentalStdlibApi::class)
@kotlin.internal.InlineOnly
public actual inline fun Int.countOneBits(): Int = Integer.bitCount(this)
For Java, there is a java.util.BitSet.
https://docs.oracle.com/javase/8/docs/api/java/util/BitSet.html
cardinality(): Returns the number of bits set to true in this BitSet.
The BitSet is memory efficient since it's stored as a Long.
Here is the functional master race recursive solution, and it is by far the purest one (and can be used with any bit length!):
template<typename T>
int popcnt(T n)
{
if (n>0)
return n&1 + popcnt(n>>1);
return 0;
}
def hammingWeight(n):
count = 0
while n:
if n&1:
count += 1
n >>= 1
return count
A simple algorithm to count the number of set bits:
int countbits(n) {
int count = 0;
while(n != 0) {
n = n & (n-1);
count++;
}
return count;
}
Take the example of 11 (1011) and try manually running through the algorithm. It should help you a lot!
I have not seen this approach anywhere:
int nbits(unsigned char v) {
return ((((v - ((v >> 1) & 0x55)) * 0x1010101) & 0x30c00c03) * 0x10040041) >> 0x1c;
}
It works per byte, so it would have to be called four times for a 32-bit integer. It is derived from the sideways addition, but it uses two 32-bit multiplications to reduce the number of instructions to only seven.
Most current C compilers will optimize this function using SIMD (SSE2) instructions when it is clear that the number of requests is a multiple of 4, and it becomes quite competitive. It is portable, can be defined as a macro or inline function and does not need data tables.
This approach can be extended to work on 16 bits at a time, using 64-bit multiplications. However, it fails when all 16 bits are set, returning zero, so it can be used only when the 0xFFFF input value is not present. It is also slower due to the 64-bit operations and does not optimize well.
Convert the integer to a binary string and count the ones.
PHP solution:
substr_count(decbin($integer), '1');
#!/user/local/bin/perl
$c=0x11BBBBAB;
$count=0;
$m=0x00000001;
for($i=0;$i<32;$i++)
{
$f=$c & $m;
if($f == 1)
{
$count++;
}
$c=$c >> 1;
}
printf("%d",$count);
ive done it through a perl script. the number taken is $c=0x11BBBBAB
B=3 1s
A=2 1s
so in total
1+1+3+3+3+2+3+3=19
Here's something that works in PHP (all PHP intergers are 32 bit signed, thus 31 bit):
function bits_population($nInteger)
{
$nPop=0;
while($nInteger)
{
$nInteger^=(1<<(floor(1+log($nInteger)/log(2))-1));
$nPop++;
}
return $nPop;
}
Here is the sample code, which might be useful.
private static final int[] bitCountArr = new int[]{0, 1, 1, 2, 1, 2, 2, 3, 1, 2, 2, 3, 2, 3, 3, 4, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 1, 2, 2, 3, 2, 3, 3, 4, 2, 3, 3, 4, 3, 4, 4, 5, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 2, 3, 3, 4, 3, 4, 4, 5, 3, 4, 4, 5, 4, 5, 5, 6, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 3, 4, 4, 5, 4, 5, 5, 6, 4, 5, 5, 6, 5, 6, 6, 7, 4, 5, 5, 6, 5, 6, 6, 7, 5, 6, 6, 7, 6, 7, 7, 8};
private static final int firstByteFF = 255;
public static final int getCountOfSetBits(int value){
int count = 0;
for(int i=0;i<4;i++){
if(value == 0) break;
count += bitCountArr[value & firstByteFF];
value >>>= 8;
}
return count;
}
A simple way which should work nicely for a small amount of bits it something like this (For 4 bits in this example):
(i & 1) + (i & 2)/2 + (i & 4)/4 + (i & 8)/8
Would others recommend this for a small number of bits as a simple solution?
For JavaScript, you can count the number of set bits on a 32-bit value using a lookup table (and this code can be easily translated to C). In addition, added 8-bit and 16-bit versions for completeness for people who find this through web search.
const COUNT_BITS_TABLE = makeLookupTable()
function makeLookupTable() {
const table = new Uint8Array(256)
for (let i = 0; i < 256; i++) {
table[i] = (i & 1) + table[(i / 2) | 0];
}
return table
}
function countOneBits32(n) {
return COUNT_BITS_TABLE[n & 0xff] +
COUNT_BITS_TABLE[(n >> 8) & 0xff] +
COUNT_BITS_TABLE[(n >> 16) & 0xff] +
COUNT_BITS_TABLE[(n >> 24) & 0xff];
}
function countOneBits16(n) {
return COUNT_BITS_TABLE[n & 0xff] +
COUNT_BITS_TABLE[(n >> 8) & 0xff]
}
function countOneBits8(n) {
return COUNT_BITS_TABLE[n & 0xff]
}
console.log('countOneBits32', countOneBits32(0b10101010000000001010101000000000))
console.log('countOneBits32', countOneBits32(0b10101011110000001010101000000000))
console.log('countOneBits16', countOneBits16(0b1010101000000000))
console.log('countOneBits8', countOneBits8(0b10000010))I am giving two algorithms to answer the question,
package countSetBitsInAnInteger;
import java.util.Scanner;
public class UsingLoop {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
try {
System.out.println("Enter a integer number to check for set bits in it");
int n = in.nextInt();
System.out.println("Using while loop, we get the number of set bits as: " + usingLoop(n));
System.out.println("Using Brain Kernighan's Algorithm, we get the number of set bits as: " + usingBrainKernighan(n));
System.out.println("Using ");
}
finally {
in.close();
}
}
private static int usingBrainKernighan(int n) {
int count = 0;
while(n > 0) {
n& = (n-1);
count++;
}
return count;
}
/*
Analysis:
Time complexity = O(lgn)
Space complexity = O(1)
*/
private static int usingLoop(int n) {
int count = 0;
for(int i=0; i<32; i++) {
if((n&(1 << i)) != 0)
count++;
}
return count;
}
/*
Analysis:
Time Complexity = O(32) // Maybe the complexity is O(lgn)
Space Complexity = O(1)
*/
}
You can do something like:
int countSetBits(int n)
{
n=((n&0xAAAAAAAA)>>1) + (n&0x55555555);
n=((n&0xCCCCCCCC)>>2) + (n&0x33333333);
n=((n&0xF0F0F0F0)>>4) + (n&0x0F0F0F0F);
n=((n&0xFF00FF00)>>8) + (n&0x00FF00FF);
return n;
}
int main()
{
int n=10;
printf("Number of set bits: %d",countSetBits(n));
return 0;
}
See heer: http://ideone.com/JhwcX
The working can be explained as follows:
First, all the even bits are shifted towards right & added with the odd bits to count the number of bits in group of two. Then we work in group of two, then four & so on..
n=1234667. You need to combine the two 8-bit chunks that the last step leaves, and clear the high bits. Also, it's apparently possible to be more efficient than this SWAR 1-bit, 2-bit, 4-bit sequence. I haven't grokked the magic of the top answer's bit-twiddling hack, though. stackoverflow.com/questions/109023/… –
Grane // How about the following:
public int CountBits(int value)
{
int count = 0;
while (value > 0)
{
if (value & 1)
count++;
value <<= 1;
}
return count;
}
I use the following function. I haven't checked benchmarks, but it works.
int msb(int num)
{
int m = 0;
for (int i = 16; i > 0; i = i>>1)
{
// debug(i, num, m);
if(num>>i)
{
m += i;
num>>=i;
}
}
return m;
}
This is the implementation in golang
func CountBitSet(n int) int {
count := 0
for n > 0 {
count += n & 1
n >>= 1
}
return count
}
This will also work fine:
int ans = 0;
while(num) {
ans += (num & 1);
num = num >> 1;
}
return ans;
public class BinaryCounter {
private int N;
public BinaryCounter(int N) {
this.N = N;
}
public static void main(String[] args) {
BinaryCounter counter=new BinaryCounter(7);
System.out.println("Number of ones is "+ counter.count());
}
public int count(){
if(N<=0) return 0;
int counter=0;
int K = 0;
do{
K = biggestPowerOfTwoSmallerThan(N);
N = N-K;
counter++;
}while (N != 0);
return counter;
}
private int biggestPowerOfTwoSmallerThan(int N) {
if(N==1) return 1;
for(int i=0;i<N;i++){
if(Math.pow(2, i) > N){
int power = i-1;
return (int) Math.pow(2, power);
}
}
return 0;
}
}
© 2022 - 2024 — McMap. All rights reserved.
[Flags()]enum. – Masteratarms