Here is how I'm discussing CAP, regarding P particularly.
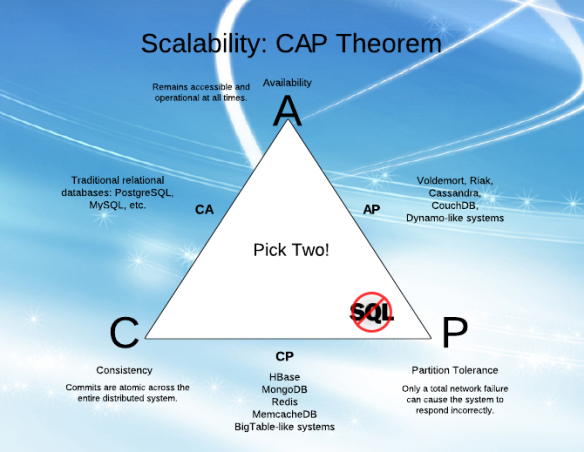
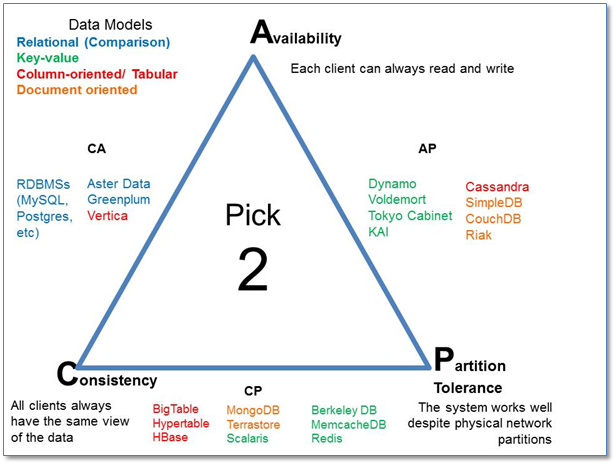
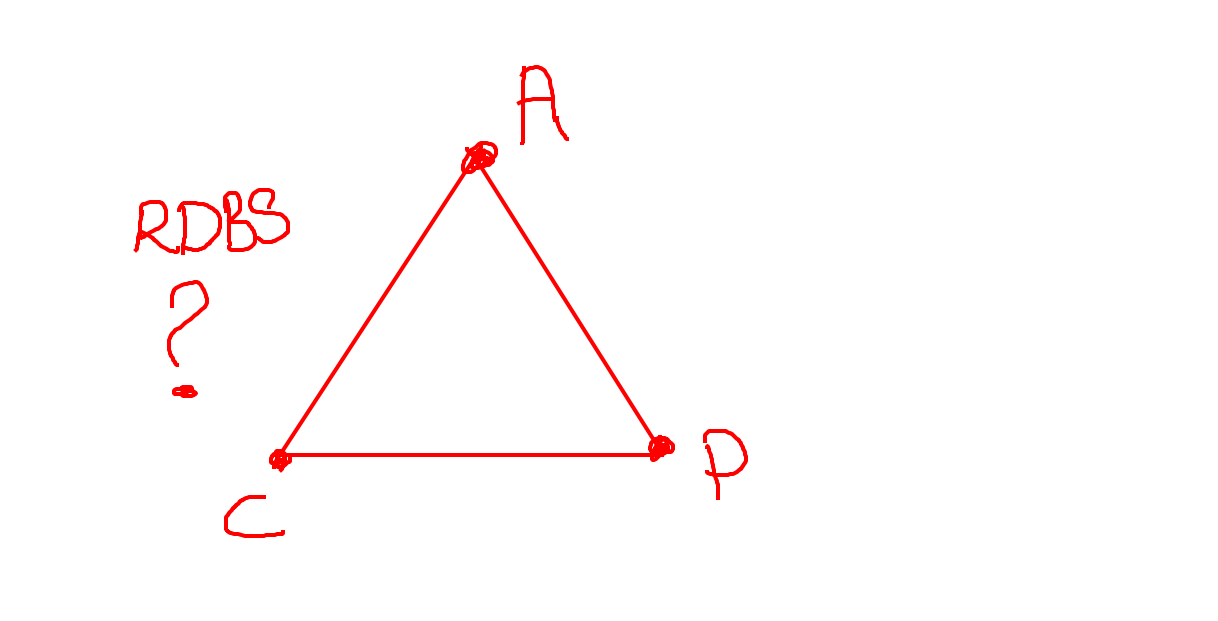
CA is only possible if you are OK with a monolithic, single server database (maybe with replication but all data on one "failure block" - servers are not considered to partially fail).
If your problem requires scale out, distributed, and multi-server --- network partitions can happen. You're already requiring P. Few problems I approach are amenable to single-server-always paradigms (or, as Stonebraker said, "distributed is table stakes"). If you can find a CA problem, solutions like a traditional non-scale-out RDBMS provides a lot of benefits.
For me, rare: so we move on to discussing AP vs CP.
You only choose between AP and CP operation when you have a partition. If the network & hardware is operating correctly, you get your cake and eat it too.
Let's discuss the AP / CP distinction.
AP - when there is a network partition, let the independent parts operate freely.
CP - when there is a network partition, shut down nodes or disallow reads and writes so there are deterministic failures.
I like architectures that can do both, because some problems are AP and some are CP - and some databases can do both. Among the CP and AP solutions, there are subtleties as well.
For example, in an AP dataset, you have the possibility of both inconsistent reads, and generating write conflicts - these are two different possible AP modes. Can your system be configured for AP with high read availability but disallows write conflicts? Or can your AP system accept write conflicts, with a strong and flexible resolution system? Will you need both eventually, or can you pick a system that only does one?
In a CP system, how much unavailability do you get with small partitions (single server), if any? Greater replication can increase unavailability in a CP system, how does the system handle those tradeoffs?
These are all questions to ask with CP vs AP.
A great read in this area right now is Brewer's "12 years later" post. I believe this moves forward the CAP debate with clarity, and recommend it highly.
http://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed