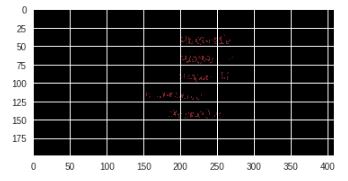
I'm using the Google Vision API to extract the text from some pictures, however, I have been trying to improve the accuracy (confidence) of the results with no luck.
every time I change the image from the original I lose accuracy in detecting some characters.
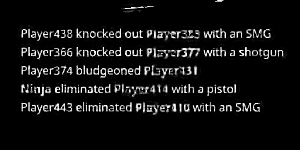
I have isolated the issue to have multiple colors for different words with can be seen that words in red for example have incorrect results more often than the other words.
Example:
some variations on the image from gray scale or b&w
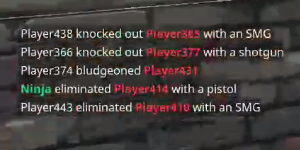
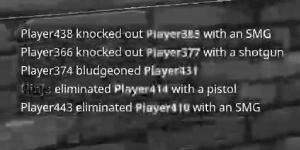



What ideas can I try to make this work better, specifically changing the colors of text to a uniform color or just black on a white background since most algorithms expect that?
some ideas I already tried, also some thresholding.
dimg = ImageOps.grayscale(im)
cimg = ImageOps.invert(dimg)
contrast = ImageEnhance.Contrast(dimg)
eimg = contrast.enhance(1)
sharp = ImageEnhance.Sharpness(dimg)
eimg = sharp.enhance(1)