I have a PDF with 4 pages. I want to create another PDF where the pages are positioned one after the another (Vertical aligment) in a single page. Which commandline tool can be used for that?
How to join multiple PDF pages to a single Page
Asked Answered
there are several ways to perform this task, one easier, one harder
The EASIER: A MULTIVALENT.JAR WAY
Multivalent.jar is a stunning piece of free software able to perform many useful tasks on pdf
you can download from one of these links (the 2009 multivalent.jar build available on sourceforge has no more pdf tools inside)
you need to know the width and height of your pdf (in Linux you can use pdfinfo)
- assuming your multipage pdf is in ISO A4 size (21x29.7cm), type:
java -cp path..to/Multivalent.jar tool.pdf.Impose -dim 4x1 -paper 84x29.7cm input.pdf
this is the resulting page, composed by the 4 sequential pages stitched side by side together:

- resulting pdf file http://ge.tt/98Kv4ce/v/0
explication:
-dim 4x1 means number of columns for rows
-paper 84x29.7cm means paper size of your final imposed document containing the 4 pages joined side by side. obviously, since in your final pdf file, you will have 4 columns and only one row, you need to multiply by 4 the document witdh (21 cm)
multivalent can accept, as unity input, also inches (-paper 33.4x11.68in) or postscript points (-paper 2380x841pt)
THE HARDER: A LATEX WAY:
4_pdf_pages_appended_side_by_side
some years ago, Peter Flynn, in comp.text.pdf suggested, for a similar task, a way to appending pdf pages side by side with the only help of LateX. If you are a LaTeXian, you can act as follows:
since you need to append side by side the four pages of your single multipage pdf, you will write a latex preamble, creating a new document like this:
assuming your pdf document has name input.pdf and its size is ISO A4, and you have this multipage pdf in your working folder, you will have
\documentclass[a4paper]{article}
\usepackage[margin=0mm,nohead,nofoot]{geometry}
\usepackage{pdfpages}
\pagestyle{empty}
\parindent0pt
\begin{document}
\includepdfmerge[nup=1x4,landscape]{input.pdf,1,input.pdf,2,input.pdf,3,input.pdf,4}
\end{document}
Thanks for pointing me to a good version of Multivalent. I strongly recommend getting it from ge.tt/#!/21OPDHX/v/4 as the other link redirects you to another domain and wants to download a .exe file. It might be a self-extracting archive, but I suspect it will install other cruft as well. –
Venicevenin
many thanks; I replaced the ziddu link (even if using adblock and noscript you are able to download multivalent.jar without pain - the -exe is a downloader tool for ziddu site but you are able to skip this and download only the Multivalent.jar file-) with rapidshare link; the best option I think could be add a torrent link in future –
Selle
In the latex way, what should I do if I have 4 single-page pdf files? –
Wrench
Just use
\includepdfmerge[nup=1x4,landscape]{input1.pdf,1,input2.pdf,1,input3.pdf,1,input4.pdf,1} –
Itinerant If you use a Unix-like operating system, there is pdfjam, which combines the Latex backend with an easy command:
pdfjam --nup 1x4,landscape input.pdf
EDIT: recently I had issues with pdfjam with that exact command. I had it working with:
cat input.pdf | pdfjam -nup 1x4 -landscape –outfile out.pdf
From their docs:
A potential drawback of pdfjam and other scripts based upon it is that any hyperlinks in the source PDF are lost
This fails if the PDF is password protected. I was able to remove this protection by specifing an empty password to PDFTK:
pdftk input.pdf input_pw "" output output.pdf –
Ankle @Ankle Or, you start by unprotecting the PDF, assuming that protection is not relevant, as in https://mcmap.net/q/1008601/-unlock-protected-pdf-files –
Lyonnesse
in version 2.08 the proper command is
pdfjam --nup 1x4,landscape p1.pdf p2.pdf p3.pdf p4.pdf --outfile output.pdf –
Lythraceous FIY: "A potential drawback of pdfjam and other scripts based upon it is that any hyperlinks in the source PDF are lost" –
Lightish
@FFish i'll point it out, thanks –
Lyonnesse
there are several ways to perform this task, one easier, one harder
The EASIER: A MULTIVALENT.JAR WAY
Multivalent.jar is a stunning piece of free software able to perform many useful tasks on pdf
you can download from one of these links (the 2009 multivalent.jar build available on sourceforge has no more pdf tools inside)
you need to know the width and height of your pdf (in Linux you can use pdfinfo)
- assuming your multipage pdf is in ISO A4 size (21x29.7cm), type:
java -cp path..to/Multivalent.jar tool.pdf.Impose -dim 4x1 -paper 84x29.7cm input.pdf
this is the resulting page, composed by the 4 sequential pages stitched side by side together:
- resulting pdf file http://ge.tt/98Kv4ce/v/0
explication:
-dim 4x1 means number of columns for rows
-paper 84x29.7cm means paper size of your final imposed document containing the 4 pages joined side by side. obviously, since in your final pdf file, you will have 4 columns and only one row, you need to multiply by 4 the document witdh (21 cm)
multivalent can accept, as unity input, also inches (-paper 33.4x11.68in) or postscript points (-paper 2380x841pt)
THE HARDER: A LATEX WAY:
4_pdf_pages_appended_side_by_side
some years ago, Peter Flynn, in comp.text.pdf suggested, for a similar task, a way to appending pdf pages side by side with the only help of LateX. If you are a LaTeXian, you can act as follows:
since you need to append side by side the four pages of your single multipage pdf, you will write a latex preamble, creating a new document like this:
assuming your pdf document has name input.pdf and its size is ISO A4, and you have this multipage pdf in your working folder, you will have
\documentclass[a4paper]{article}
\usepackage[margin=0mm,nohead,nofoot]{geometry}
\usepackage{pdfpages}
\pagestyle{empty}
\parindent0pt
\begin{document}
\includepdfmerge[nup=1x4,landscape]{input.pdf,1,input.pdf,2,input.pdf,3,input.pdf,4}
\end{document}
Thanks for pointing me to a good version of Multivalent. I strongly recommend getting it from ge.tt/#!/21OPDHX/v/4 as the other link redirects you to another domain and wants to download a .exe file. It might be a self-extracting archive, but I suspect it will install other cruft as well. –
Venicevenin
many thanks; I replaced the ziddu link (even if using adblock and noscript you are able to download multivalent.jar without pain - the -exe is a downloader tool for ziddu site but you are able to skip this and download only the Multivalent.jar file-) with rapidshare link; the best option I think could be add a torrent link in future –
Selle
In the latex way, what should I do if I have 4 single-page pdf files? –
Wrench
Just use
\includepdfmerge[nup=1x4,landscape]{input1.pdf,1,input2.pdf,1,input3.pdf,1,input4.pdf,1} –
Itinerant I just did this with CoherentPDF
cpdf -impose-xy "0 4" in.pdf -o out.pdf
If the number of pages is unknown, set it to something bigger like
cpdf -impose-xy "0 99" in.pdf -o out.pdf
The x value for -impose-xy may be set to zero to indicate an infinitely-wide page; the y value to indicate an infinitely-long one. In both cases, the pages in the input file (*) are assumed to be of the same dimensions.
More options can be explored in the excellent manual:
https://www.coherentpdf.com/cpdfmanual/cpdfmanualch9.html#x13-860009.2
(*) In my case first I had to scale the last page to fit the dimensions of the other pages, followed by the imposing.
cpdf \
-scale-to-fit "768pt 1024pt" -top 0 in.pdf end \
AND \
-impose-xy "99 0" in.pdf \
-o out.pdf
I recently had a similar problem. I needed to develop a solution to preprocess a PDF to better identify the tables using the tabula-py package. Here's the step-by-step solution to my problem:
- Remove header and footer from all
npages; - Split the PDF into
nfiles containing 1 single page each; - Crop the single page from the
nfiles according to its bounding box; - Merge the
nfiles into 1 single PDF containing 1 page, keeping the order; - Read and preprocess tables from text based PDF using
tabula-py.
In my case, step 3 of the process can generate files with different dimensions. When using the pdfjam command I had problems aligning the pages in step 4, even using the --pagetemplate parameter. For me the vertical alignment was the worst.
Fortunately, I was able to solve this page alignment problem using a LaTeX based approach. Here is the base source code I used -- put all files in the same directory.
The answer to this post's question is in the "Shell Script" section, starting from the line "Merging the 'n' pages into a single one using LaTeX...".
Requirements:
I tested this solution using the Debian linux distro. To work on Windows, you can install Debian via WSL, for example. Assuming you are using Debian or Ubuntu, run the following commands:
sudo apt update
sudo apt install texlive-extra-utils texlive-latex-extra poppler-utils ghostscript default-jdk -y
As a result of PDF preprocessing, the final file may have reduced dimensions, especially in width. Even though it is vectorized, reducing the size of the PDF has a negative impact on the quality of extracting tables using the tabula-py tool.
To increase the size of the final PDF file, keeping the aspect ratio, we can use the cpdf tool. In the case of using a Linux distro, just copy the binary file to the same directory as the Shell script. Then give the binary file execute permission:
chmod +x cpdf
LaTeX template:
Create a file named pdf_merge_template.tex with the following content:
\documentclass[dvipdfmx]{article}
\usepackage[margin=0in]{geometry}
\usepackage{pdfpages}
\begin{document}
\centering<PDF-PAGES>
\end{document}
Shell script:
Create a file named pdf-preprocessing.sh with the following content:
#!/bin/bash
# References
# ----------
# [PDF preprocessing] https://mcmap.net/q/925659/-how-to-join-multiple-pdf-pages-to-a-single-page
PDF_MERGE_TEMPLATE_FILENAME="pdf_merge_template.tex"
PDF_MERGE_TEMPLATE_PAGES_MACRO="<PDF-PAGES>"
CPDF_FILENAME="cpdf" # Binary file of "Coherent PDF" tool.
INPUT_FILEPATH=$1
OUTPUT_FILEPATH=$2
if [ "$#" -eq "2" ]; then
echo "Starting PDF preprocessing..."
else
echo "ERROR: Wrong arguments ('INPUT_FILEPATH', 'OUTPUT_FILEPATH')!"
exit
fi
TEMP_DIR_PATH=$(mktemp -d)
echo "Setting up working directory: ${TEMP_DIR_PATH}"
THIS_FILENAME=$(readlink -f "$0")
THIS_DIR=$(dirname "$THIS_FILENAME")
PDF_MERGE_TEMPLATE_PATH="${THIS_DIR}/${PDF_MERGE_TEMPLATE_FILENAME}"
CPDF_BIN_PATH="${THIS_DIR}/${CPDF_FILENAME}"
echo "Removing header and footer from all pages..."
# Removing header and footer from PDF pages based on margin settings (e.g., '5 -75 5 -25'):
pdfcrop --margins '5 -75 5 -25' "${INPUT_FILEPATH}" "${TEMP_DIR_PATH}/input-tmp.pdf"
# Deleting the textual content of the cut parts:
pdftocairo "${TEMP_DIR_PATH}/input-tmp.pdf" "${TEMP_DIR_PATH}/input.pdf" -pdf
# Counting the number of pages from PDF:
NUM_PAGES=$(pdfinfo "${TEMP_DIR_PATH}/input.pdf" | awk '/^Pages:/ {print $2}')
REL_PAGE_WIDTH=$(python -c "print(1 / ${NUM_PAGES})")
PAGES_LIST=""
echo "Cropping each page based on its specific bounding box..."
for i in $(seq 1 $NUM_PAGES)
do
# Splitting current page:
pdfjam "${TEMP_DIR_PATH}/input.pdf" $i --outfile "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
# Fetching bounding box of current page:
PAGE_WIDTH=$(pdfinfo "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" | awk '/^Page size:/ {print $3}')
BBOX=$(gs -dBATCH -dNOPAUSE -q -sDEVICE=bbox "${TEMP_DIR_PATH}/page_${i}-tmp.pdf" 2>&1 | awk '/^%%HiResBoundingBox:/ {print 0 " " $3 " " '${PAGE_WIDTH}' " " $5}')
# Removing content out of current page's bounding box:
PAGE_FILENAME="page_${i}"
PDF_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.pdf"
PS_FILEPATH="${TEMP_DIR_PATH}/${PAGE_FILENAME}.ps"
gs -dNOPAUSE -dBATCH -sDEVICE=pdfwrite -dCompatibilityLevel=1.5 -sOutputFile=$PDF_FILEPATH -c "[/CropBox [${BBOX}] /PAGES pdfmark" -f "${TEMP_DIR_PATH}/page_${i}-tmp.pdf"
PAGES_LIST="${PAGES_LIST}\n \\\includegraphics[width=${REL_PAGE_WIDTH}\\\textwidth]{${PDF_FILEPATH}} \\\\\\\ \\\vspace{-0.03cm}"
done
echo "Merging the 'n' pages into a single one using LaTeX..."
cp $PDF_MERGE_TEMPLATE_PATH "${TEMP_DIR_PATH}/merged.tex"
sed -i "s#${PDF_MERGE_TEMPLATE_PAGES_MACRO}#${PAGES_LIST}#g" "${TEMP_DIR_PATH}/merged.tex"
latex -halt-on-error -output-directory $TEMP_DIR_PATH "${TEMP_DIR_PATH}/merged.tex"
dvipdfm "${TEMP_DIR_PATH}/merged.dvi" -o "${TEMP_DIR_PATH}/merged.pdf"
echo "Finalizing the PDF and sending a copy to the destination directory..."
# Adding margins to the final PDF:
pdfcrop --margins 5 "${TEMP_DIR_PATH}/merged.pdf" "${TEMP_DIR_PATH}/output-tmp.pdf"
# Enlargement of the final PDF file to extract tables correctly using the "tabula-py" tool:
$CPDF_BIN_PATH -scale-page "10 10" "${TEMP_DIR_PATH}/output-tmp.pdf" -o "${TEMP_DIR_PATH}/output.pdf"
# Copying the pre-processed PDF file to the output path:
cp "${TEMP_DIR_PATH}/output.pdf" "${OUTPUT_FILEPATH}"
echo "Deleting temp files..."
rm -rf "${TEMP_DIR_PATH}"
Give execution permission to the script using the following command:
chmod +x pdf-preprocessing.sh
Usage examples:
To preprocess a file called example.pdf, simply run the following command:
sh pdf-preprocessing.sh example.pdf preprocessed-example.pdf
Edit the script parameters as per your case. The header and footer coordinates, for example, will depend on the template of your files. Feel free to suggest improvements and simplifications.
Spot on my use case, thank you! You don't declare pdfcrop though? –
Crevasse
An option is to use pdfxup.
-o .. Outfile
-x .. n columns per page
-y .. n lines per page
-fw 0 .. would remove the frame around the pages
pdfxup -o out.pdf -x 4 -y 1 input.pdf

-l .. landscape-mode
pdfxup -o out.pdf -x 1 -y 4 -l 0 input.pdf
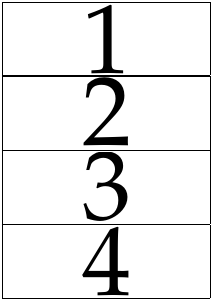
Making a 2x2 Page row wise.
pdfxup -o out.pdf -x 2 -y 2 -l 0 input.pdf
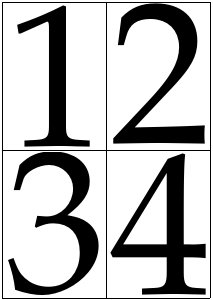
Making a 2x2 Page col wise.
pdfxup -o out.pdf -x 2 -y 2 -l 0 -col input.pdf

Or using pdfjam.
pdfjam --outfile out.pdf --nup 4x1 --landscape input.pdf

pdfjam --outfile out.pdf --nup 1x4 input.pdf

pdfjam --outfile out.pdf --nup 2x2 input.pdf

pdfjam --outfile out.pdf --nup 2x2 --column true input.pdf
Latex code to create the 4 pdf pages.
\documentclass{article}
\pagestyle{empty}
\begin{document}
\fontsize{\textheight}{\textheight}
\fontfamily{ppl}\selectfont
\centering
1\\2\\3\\4
\end{document}
The pdf outputs are converted to png using
pdftoppm -singlefile -scale-to 300 out.pdf out -png
© 2022 - 2024 — McMap. All rights reserved.
pfdunitewould do what you want.... – Savepdfunitecombines mutiple pdfs into one pdf with multiple pages, not what the OP wants. – Wrench