The key here is to convert your data into a matrix (adjacency matrix in
which rows correspond to 'from' and columns correspond to 'to').
df = read.table(textConnection("
Brand_from model_from Brand_to Model_to
VOLVO s80 BMW 5series
BMW 3series BMW 3series
VOLVO s60 VOLVO s60
VOLVO s60 VOLVO s80
BMW 3series AUDI s4
AUDI a4 BMW 3series
AUDI a5 AUDI a5
"), header = TRUE, stringsAsFactors = FALSE)
from = paste(df[[1]], df[[2]], sep = ",")
to = paste(df[[3]], df[[4]], sep = ",")
mat = matrix(0, nrow = length(unique(from)), ncol = length(unique(to)))
rownames(mat) = unique(from)
colnames(mat) = unique(to)
for(i in seq_along(from)) mat[from[i], to[i]] = 1
Value of mat is
> mat
BMW,5series BMW,3series VOLVO,s60 VOLVO,s80 AUDI,s4 AUDI,a5
VOLVO,s80 1 0 0 0 0 0
BMW,3series 0 1 0 0 1 0
VOLVO,s60 0 0 1 1 0 0
AUDI,a4 0 1 0 0 0 0
AUDI,a5 0 0 0 0 0 1
Then send the matrix to chordDiagram with specifying order and directional.
Manual specification of order is to make sure same brands are grouped together.
par(mar = c(1, 1, 1, 1))
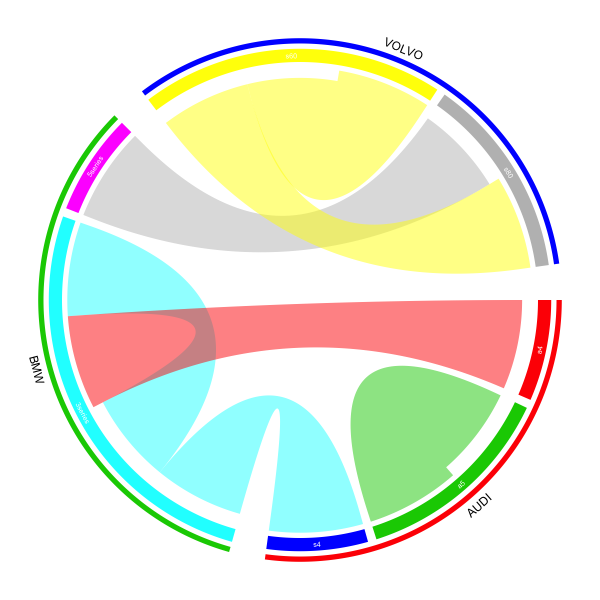
chordDiagram(mat, order = sort(union(from, to)), directional = TRUE)
circos.clear()
To make the figure more complex, You can create a track for brand names,
a track for identication of brands, a track for model names. Also we
can set the gap between brands larger than inside each brand.
1 set gap.degree
circos.par(gap.degree = c(2, 2, 8, 2, 8, 2, 8))
2 before drawing chord diagram, we create two empty tracks, one for brand names,
one for identification lines by preAllocateTracks argument.
par(mar = c(1, 1, 1, 1))
chordDiagram(mat, order = sort(union(from, to)),
direction = TRUE, annotationTrack = "grid", preAllocateTracks = list(
list(track.height = 0.02),
list(track.height = 0.02))
)
3 add the model name to the annotation track (this track is created by default,
the thicker track in both left and right figures. Note this is the third track from
outside circle to inside)
circos.trackPlotRegion(track.index = 3, panel.fun = function(x, y) {
xlim = get.cell.meta.data("xlim")
ylim = get.cell.meta.data("ylim")
sector.index = get.cell.meta.data("sector.index")
model = strsplit(sector.index, ",")[[1]][2]
circos.text(mean(xlim), mean(ylim), model, col = "white", cex = 0.8, facing = "inside", niceFacing = TRUE)
}, bg.border = NA)
4 add brand identification line. Because brand covers more than one sector, we need
to manually calculate the start and end degree for the line (arc). In following,
rou1 and rou2 are height of two borders in the second track. The idendification lines
are drawn in the second track.
all_sectors = get.all.sector.index()
rou1 = get.cell.meta.data("yplot", sector.index = all_sectors[1], track.index = 2)[1]
rou2 = get.cell.meta.data("yplot", sector.index = all_sectors[1], track.index = 2)[2]
start.degree = get.cell.meta.data("xplot", sector.index = all_sectors[1], track.index = 2)[1]
end.degree = get.cell.meta.data("xplot", sector.index = all_sectors[3], track.index = 2)[2]
draw.sector(start.degree, end.degree, rou1, rou2, clock.wise = TRUE, col = "red", border = NA)
5 first get the coordinate of text in the polar coordinate system, then map to data coordinate
system by reverse.circlize. Note the cell you map coordinate back and the cell you draw text
should be the same cell.
m = reverse.circlize( (start.degree + end.degree)/2, 1, sector.index = all_sectors[1], track.index = 1)
circos.text(m[1, 1], m[1, 2], "AUDI", cex = 1.2, facing = "inside", adj = c(0.5, 0), niceFacing = TRUE,
sector.index = all_sectors[1], track.index = 1)
For the other two brand, with the same code.
start.degree = get.cell.meta.data("xplot", sector.index = all_sectors[4], track.index = 2)[1]
end.degree = get.cell.meta.data("xplot", sector.index = all_sectors[5], track.index = 2)[2]
draw.sector(start.degree, end.degree, rou1, rou2, clock.wise = TRUE, col = "green", border = NA)
m = reverse.circlize( (start.degree + end.degree)/2, 1, sector.index = all_sectors[1], track.index = 1)
circos.text(m[1, 1], m[1, 2], "BMW", cex = 1.2, facing = "inside", adj = c(0.5, 0), niceFacing = TRUE,
sector.index = all_sectors[1], track.index = 1)
start.degree = get.cell.meta.data("xplot", sector.index = all_sectors[6], track.index = 2)[1]
end.degree = get.cell.meta.data("xplot", sector.index = all_sectors[7], track.index = 2)[2]
draw.sector(start.degree, end.degree, rou1, rou2, clock.wise = TRUE, col = "blue", border = NA)
m = reverse.circlize( (start.degree + end.degree)/2, 1, sector.index = all_sectors[1], track.index = 1)
circos.text(m[1, 1], m[1, 2], "VOLVO", cex = 1.2, facing = "inside", adj = c(0.5, 0), niceFacing = TRUE,
sector.index = all_sectors[1], track.index = 1)
circos.clear()
If you want to set colors, please go to the package vignette, If you want, you can also use circos.axis to add axes on the plot.
![enter image description here]()




2:4and2:8of brand_color and model_color are hard-coded and if you use your own data would need to be dynamically coded as, egmodel_color = structure(seq(2,length(names(brand))+1), names = names(brand))– Zymase