From the link: What is the difference between load/store relaxed atomic and normal variable?
I was deeply impressed by this answer:
Using an atomic variable solves the problem - by using atomics all threads are guarantees to read the latest writen-value even if the memory order is relaxed.
Today, i read the the link below: https://preshing.com/20140709/the-purpose-of-memory_order_consume-in-cpp11/
atomic<int*> Guard(nullptr);
int Payload = 0;
thread1:
Payload = 42;
Guard.store(&Payload, memory_order_release);
thred2:
g = Guard.load(memory_order_consume);
if (g != nullptr)
p = *g;
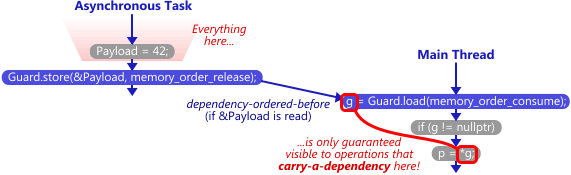
QUESTION: I learned that Data Dependency prevents related instruction be reordered. But i think that is obvious for ensure the correctness of execution results. It doesn't matter whether comsume-release semantic exists or not. So i wonder comsume-release really do. Oh, maybe it uses data dependencies to prevent reordering of instructions while ensuring the visibility of Payload?
So
Is it possible to get the same correct result using memory_order_relaxed if i make that 1.preventing instruction be reordered 2.ensuring the visibility of non atomic var of Payload :
atomic<int*> Guard(nullptr);
volatile int Payload = 0; // 1.Payload is volatile now
// 2.Payload.assign and Guard.store in order for data dependency
Payload = 42;
Guard.store(&Payload, memory_order_release);
// 3.data Dependency make w/r of g/p in order
g = Guard.load(memory_order_relaxed);
if (g != nullptr)
p = *g; // 4. For 1,2,3 there are no reorder, and here, volatile Payload make the value of 42 is visable.
Additional content(because of Sneftel's anwser):
1.Payload = 42; volatile make the W/R of Payload to/from main memory but not to/from cache.So 42 will write to memory.
2.Guard.store(&Payload, any MO flag can use for writting); Guard is non-volatile as you said, but is atomic
Using an atomic variable solves the problem - by using atomics all threads are guarantees to read the latest writen-value even if the memory order is relaxed.
In fact, atomics are always thread safe, regardless of the memory order! The memory order is not for the atomics -> it's for non atomic data.
So after Guard.store performing, Guard.load (with any MO flag can use for reading) can get the address of Payload correcttly. And then get the 42 from memory correcttly.
Above code:
1.no reorder effect for data dependency .
2.no cache effect for volatile Payload
3.no thread-safe problem for atomic Guard
Can i get the correct value - 42?
Back to the main question
When you use consume semantics, you’re basically trying to make the compiler exploit data dependencies on all those processor families. That’s why, in general, it’s not enough to simply change memory_order_acquire to memory_order_consume. You must also make sure there are data dependency chains at the C++ source code level.
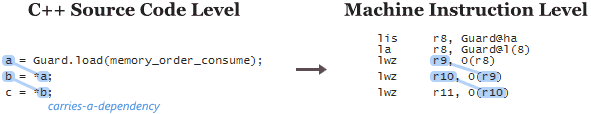
" You must also make sure there are data dependency chains at the C++ source code level."
I think the data dependency chains at the C++ source code level prevents instruction are reordered naturally. So What does memory_order_consume really do?
And can I use memory_order_relaxed to achieve the same result as above code?
Additional content end
a=1; b=2were reordered? – Axemo_relaxedand cross your fingers (with code that would make it hard for a compiler to break the data dependency, e.g. by branching on a value or removing it if it can prove there's only one possible value.) See C++11: the difference between relaxed and consume – Reliant