I have seen the weights of neural networks initialized to random numbers so I am curious why the weights of logistic regression get initialized to zeros?
Why do weight parameters of logistic regression get initialized to zeros?
Asked Answered
Incase of Neural Networks there n neurons in each layer. So if you initialize weight of each neuron with 0 then after back propogation each of them will have same weights :

Neurons a1 and a2 in the first layer will have same weights no matter how long you iterate. Since they are calculating the same function.
Which is not the case with logistic regression its simply y = Wx + b.
Does that mean for NN because there's no bias added hence it will always remains the same? But it's not the case for logistic regression? 🤔 –
Chainey
I think the above answers are a bit misleading. Actually, the sigmoid function, which is also called the logit function, is always used in logistic regression for its special properties. For example,
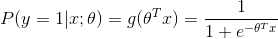
(Sorry for the ugly formula). And its corresponding function is shown as below:
 Thus, zeros ensure the values are always on the linear area, making the propagation easier.
Thus, zeros ensure the values are always on the linear area, making the propagation easier.
Pardon me asking, but why would it matter if our weights are closer or far from zero? Doesn't the logistic function
force the activation output to be between 0 and 1 regardless of the value of weight? The point about randomness producing the same backpropagation weights as an answer makes more sense to me logically. –
Collis If the values' absolute values are too large, the gradient would be zero, which hinders your training. –
Calzada
If all the weights are initialized to zero, backpropagation will not work as expected because the gradient for the intermediate neurons and starting neurons will die out(become zero) and will not update ever. The reason is, in backward pass of the NN, the gradient at some intermediate neuron is multiplied by the weights of the outgoing edge from that neuron to the neuron in next layer, which would be zero and hence the gradient at that intermediate node would be zero too. Subsequently all the weights will never improve and the model will end up only correcting the weights directly connected to output neurons only.
In logistic regression, the linear equation a = Wx + b where a is a scalar and W and x are both vectors. The derivative of the binary cross entropy loss with respect to a single dimension in the weight vector W[i] is a function of x[i], which is in general different than x[j] when i not equal j.
© 2022 - 2024 — McMap. All rights reserved.