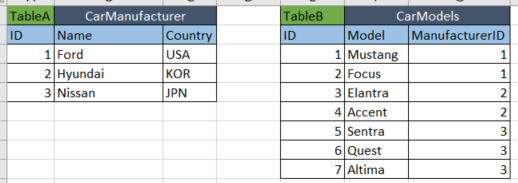
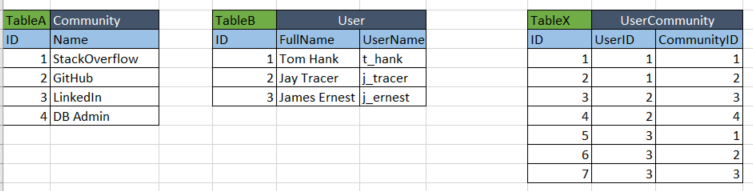
Many-to-many relationships are quite common in the real world. For instance, a reader can read many newspapers, and a newspaper can have many readers.
Normalized version
Newspaper Reader Subscription
--------- ------ ------------
id id id
name name newspaper_id
address reader_id
Here the Subscription table is what we generally call a 'join' table.
We should understand the need for this table.
Let's say A is reader of N1 and N2 newspapers. B is a reader of N2 and N3 newspapers.
For the above schema the tables would be as following.
Newspaper Reader Subscription
--------- ------ ------------
1 N1 1 A xyz 1 1 1
2 N2 2 B abc 2 1 2
3 N3 3 2 2
4 2 3
Queries
Query 1: find the names of the newspapers read by A
Query 2: find the names of readers who read N2
Query 3: add a newspaper N3 to reader A
Denormalized schema
Let's say there was no table Subscription. Then I would have to add records of readers in my Newspaper table and newspapers in my Reader table. The denormalized schema would be as follows.
Newspaper Reader
--------- ------
id id
nid rid
name name
reader_name address
newspaper_name
The tables would look like the following:
Newspaper Reader
--------- ------
1 1 N1 A 1 1 A xyz N1
2 2 N2 A 2 1 A xyz N2
3 2 N2 B 3 2 B abc N2
4 3 N3 B 4 2 B abc N3
Information duplication
As you can see there is duplication in storage here. When we have to add a new subscription for user A for N3 (query 3), we would need to insert rows both in Reader and Newspaper tables while in the earlier schema there would only be a single new row added in the Subscription table.
Compute vs IO
But in the read path you have to do compute intensive joins.
In query 1, you will have to get the id of A from Reader table, join the tables Subscription and Newspaper to get the newspaper names read by A. If you were to do query 1/2 in the denormalized version, you will have to only read 1 table.
Type Normalized Denormalized
Query 1 Read 3 reads 1 read
Query 2 Read 3 reads 1 read
Query 3 Write 2 reads (reading of id) 2 reads (for reading id)
1 write 2 writes
It would take a careful analysis of your current usage pattern requirements and future evolution to take the call between the two.
If you were to use a RDBMS like MySQL, and would like to optimize storage, you would go for the normalized schema. If you were to use a NoSQL like Cassandra, you would probably go for the denormalized schema. In the age of cloud where storage is cheaper than compute (probably because of slowing down of Moore's law), often the denormalized schema makes more business sense when your scale of data becomes huge.