I try to scrap some airplane schedule information on www.flightradar24.com website for research project.
The hierarchy of json file i want to obtain is something like that :
Object ID
- country
- link
- name
- airports
- airport0
- code_total
- link
- lat
- lon
- name
- schedule
- ...
- ...
- airport1
- code_total
- link
- lat
- lon
- name
- schedule
- ...
- ...
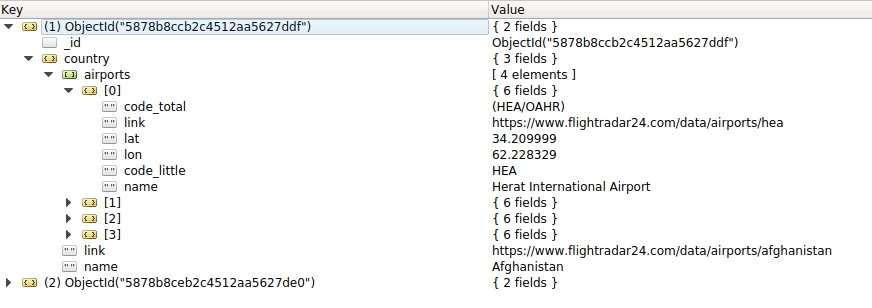
Country and Airport are stored using items, and as you can see on json file the CountryItem (link, name attribute) finally store multiple AirportItem (code_total, link, lat, lon, name, schedule) :
class CountryItem(scrapy.Item):
name = scrapy.Field()
link = scrapy.Field()
airports = scrapy.Field()
other_url= scrapy.Field()
last_updated = scrapy.Field(serializer=str)
class AirportItem(scrapy.Item):
name = scrapy.Field()
code_little = scrapy.Field()
code_total = scrapy.Field()
lat = scrapy.Field()
lon = scrapy.Field()
link = scrapy.Field()
schedule = scrapy.Field()
Here my scrapy code AirportsSpider to do that :
class AirportsSpider(scrapy.Spider):
name = "airports"
start_urls = ['https://www.flightradar24.com/data/airports']
allowed_domains = ['flightradar24.com']
def clean_html(self, html_text):
soup = BeautifulSoup(html_text, 'html.parser')
return soup.get_text()
rules = [
# Extract links matching 'item.php' and parse them with the spider's method parse_item
Rule(LxmlLinkExtractor(allow=('data/airports/',)), callback='parse')
]
def parse(self, response):
count_country = 0
countries = []
for country in response.xpath('//a[@data-country]'):
if count_country > 5:
break
item = CountryItem()
url = country.xpath('./@href').extract()
name = country.xpath('./@title').extract()
item['link'] = url[0]
item['name'] = name[0]
count_country += 1
countries.append(item)
yield scrapy.Request(url[0],meta={'my_country_item':item}, callback=self.parse_airports)
def parse_airports(self,response):
item = response.meta['my_country_item']
airports = []
for airport in response.xpath('//a[@data-iata]'):
url = airport.xpath('./@href').extract()
iata = airport.xpath('./@data-iata').extract()
iatabis = airport.xpath('./small/text()').extract()
name = ''.join(airport.xpath('./text()').extract()).strip()
lat = airport.xpath("./@data-lat").extract()
lon = airport.xpath("./@data-lon").extract()
iAirport = AirportItem()
iAirport['name'] = self.clean_html(name)
iAirport['link'] = url[0]
iAirport['lat'] = lat[0]
iAirport['lon'] = lon[0]
iAirport['code_little'] = iata[0]
iAirport['code_total'] = iatabis[0]
airports.append(iAirport)
for airport in airports:
json_url = 'https://api.flightradar24.com/common/v1/airport.json?code={code}&plugin\[\]=&plugin-setting\[schedule\]\[mode\]=&plugin-setting\[schedule\]\[timestamp\]={timestamp}&page=1&limit=50&token='.format(code=airport['code_little'], timestamp="1484150483")
yield scrapy.Request(json_url, meta={'airport_item': airport}, callback=self.parse_schedule)
item['airports'] = airports
yield {"country" : item}
def parse_schedule(self,response):
item = response.request.meta['airport_item']
jsonload = json.loads(response.body_as_unicode())
json_expression = jmespath.compile("result.response.airport.pluginData.schedule")
item['schedule'] = json_expression.search(jsonload)
Explanation :
In my first parse, i call a request on for each country link i found whith the
CountryItemcreated viameta={'my_country_item':item}. Each of these request callbackself.parse_airportsIn my second level of parse
parse_airports, i catchCountryItemcreated usingitem = response.meta['my_country_item']and i create a new itemiAirport = AirportItem()for each airport i found into this country page. Now i want to getscheduleinformation for eachAirportItemcreated and stored inairportslist.In the second level of parse
parse_airports, i run a for loop onairportsto catchscheduleinformation using a new Request. Because i want to include this schedule information into my AirportItem, i include this item into meta informationmeta={'airport_item': airport}. The callback of this request runparse_scheduleIn the third level of parse
parse_schedule, i inject the schedule information collected by scrapy into the AirportItem previously created usingresponse.request.meta['airport_item']
But i have a problem in my source code, scrapy correctly scrap all the informations (country, airports, schedule), but my comprehension of nested item seems not correct. As you can see the json i produced contain country > list of (airport), but not country > list of (airport > schedule )
My code is on github : https://github.com/IDEES-Rouen/Flight-Scrapping