I'm facing a problem implementing data-synchronization between a server and multiple clients. I read about Event Sourcing and I would like to use it to accomplish the syncing-part.
I know that this is not a technical question, more of a conceptional one.
I would just send all events live to the server, but the clients are designed to be used offline from time to time.
This is the basic concept: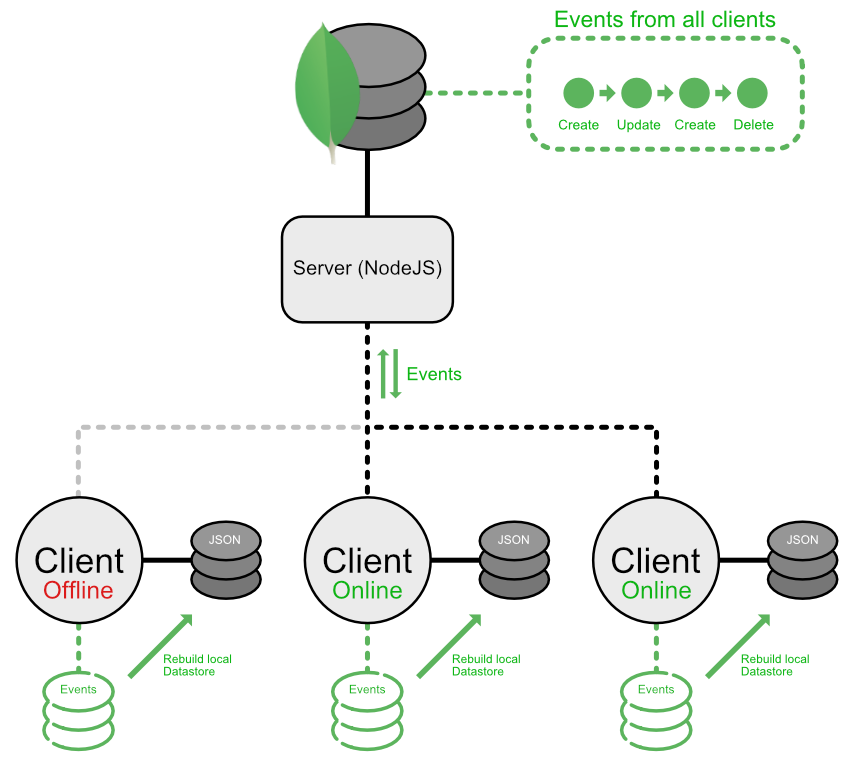
The Server stores all events that every client should know about, it does not replay those events to serve the data because the main purpose is to sync the events between the clients, enabling them to replay all events locally.
The Clients have its one JSON store, also keeping all events and rebuilding all the different collections from the stored/synced events.
As clients can modify data offline, it is not that important to have consistent syncing cycles. With this in mind, the server should handle conflicts when merging the different events and ask the specific user in the case of a conflict.
So, the main problem for me is to dertermine the diffs between the client and the server to avoid sending all events to the server. I'm also having trouble with the order of the synchronization process: push changes first, pull changes first?
What I've currently built is a default MongoDB implementation on the serverside, which is isolating all documents of a specific user group in all my queries (Currently only handling authentication and server-side database work). On the client, I've built a wrapper around a NeDB store, enabling me to intercept all query operations to create and manage events per-query, while keeping the default query behaviour intact. I've also compensated for the different ID systems of neDB and MongoDB by implementing custom ids that are generated by the clients and are part of the document data, so that recreating a database won't mess up the IDs (When syncing, these IDs should be consistent across all clients).
The event format will look something like this:
{
type: 'create/update/remove',
collection: 'CollectionIdentifier',
target: ?ID, //The global custom ID of the document updated
data: {}, //The inserted/updated data
timestamp: '',
creator: //Some way to identify the author of the change
}
To save some memory on the clients, I will create snapshots at certain amounts of events, so that fully replaying all events will be more efficient.
So, to narrow down the problem: I'm able to replay events on the client side, I'm also able to create and maintain the events on the client and serverside, Merging the events on serverside should also not be a problem, Also replicating a whole database with existing tools is not an option as I'm only syncing certain parts of the database (Not even entire collections as the documents are assigned different groups in which they should sync).
But what I am having trouble with is:
- The process of determining what events to send from the client when syncing (Avoid sending duplicate events, or even all events)
- Determining what events to send back to the client (Avoid sending duplicate events, or even all events)
- The right order of syncing the events (Push/Pull changes)
Another Question I would like to ask, is whether storing the updates directly on the documents in a revision-like style is more efficient?
If my question is unclear, duplicate (I found some questions, but they didnt help me in my scenario) or something is missing, please leave a comment, I will maintain it as best as I can to keep it simple, as I've just written everything down that could help you understand the concept.
Thanks in advance!