Sort using a key
Since pandas 1.1.0, we can pass a key= parameter which admits a function as a sorting key much like the key argument in the builtin sorted() function in Python. However, unlike the function passed to sorted's key, this function has to be vectorized, which means it must output a Series/DataFrame to be used to sort the input.
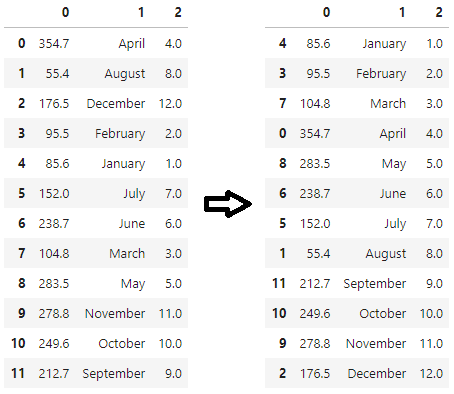
For the example in the OP, instead of creating column '2' to sort by column '1', we could directly apply a sorting key to column '1'. Because the column(s) passed as by= arguments are operated on internally in .sort_values(), we can create a month name-to-number mapper dictionary and pass a lambda that maps this dictionary to the column '1'.
import calendar # <--- the builtin calendar module
month_to_number_mapper = {m:i for i,m in enumerate(calendar.month_name)}
df1 = df.sort_values(by='1', key=lambda col: col.map(month_to_number_mapper))
As you see, this is reminiscent of the following sorted() call in vanilla Python:
li = sorted(df.values, key=lambda row: month_to_number_mapper[row[1]])
For the example in the OP, since column '1' is a column of month names, we can treat it as if it were a datetime column to sort the dataframe. To do that we can pass pandas' to_datetime function as key.
df1 = df.sort_values(by='1', key=lambda col: pd.to_datetime(col, format='%B'))
This is reminiscent of the following sorted() call in vanilla Python:
from datetime import datetime
li = sorted(df.values, key=lambda row: datetime.strptime(row[1], '%B'))
Sort by index
Pandas' .loc[] rearranges rows according to values passed to it. So another way to sort could be to sort column '1' using whatever sorting key and then pass the sorted object's index to loc[].
sorted_index = pd.to_datetime(df['1'], format='%B').sort_values().index
df1 = df.loc[sorted_index]
All three ways listed above perform the following transformation:
![result]()
ascending=False– Complected