To add to the other (fine) answer:
You can minimize the error_count by increasing the shard_size-parameter, like this:
"aggs":{ "group_by_creator":{ "terms":{
"field":"creator",
"size": 20,
"shard_size": 100
} } } }
What does this do?
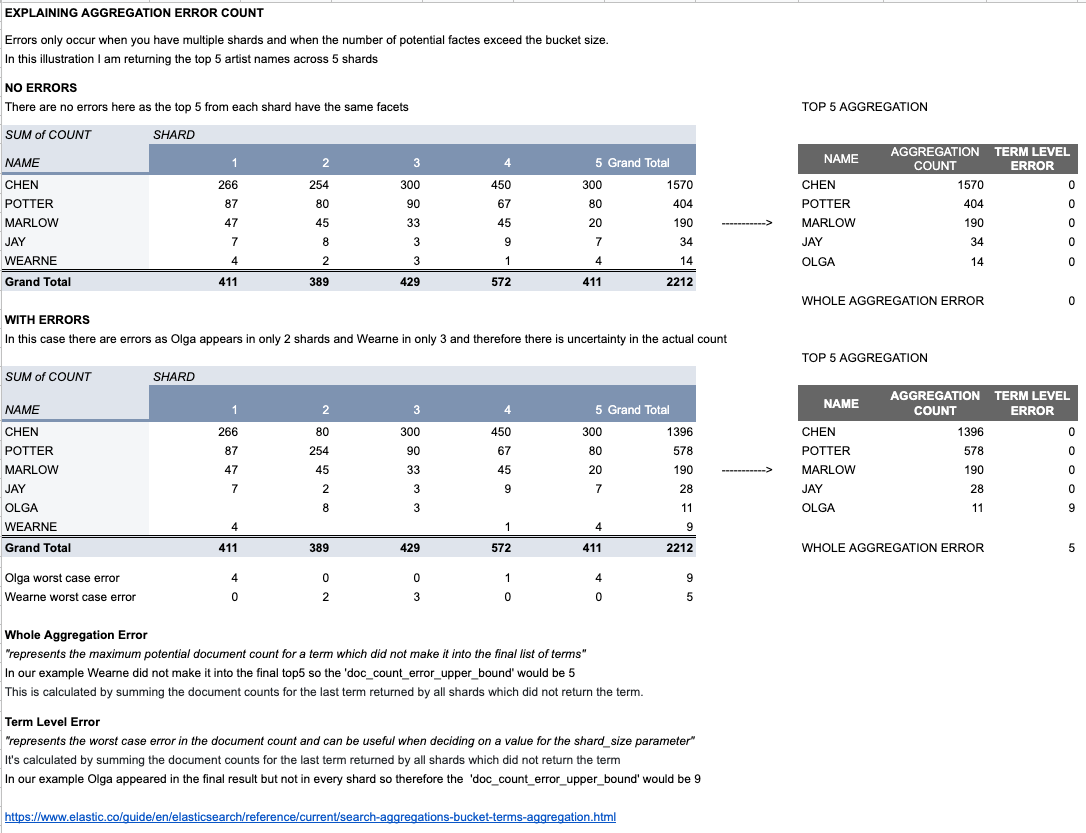
When you ask for a terms-aggregation, elastic passes it on to individual shards, and then later recombines the results. This could for example look like this (though I shrank it for brevity):
- Shard 0 reports this:
A: 10, B: 8, C:6, D:4, E:2
- Shard 1 reports:
A: 12, C:8, F: 5, B: 4, G: 4
The coordinating node adds this up to:
A: 22
C: 14
B: 12
F: 5 (plus up to 2 missing)
D: 4 (plus up to 4 missing)
G: 4 (plus up to 2 missing)
E: 2 (plus up to 4 missing)
This means the coordinating node could return a top-3 that is guaranteed accurate, but the top-5 would have a doc_count_error_upper_bound of 4, because we missed some data.
To prevent this problem, elastic can actually request each shard to report on more terms. As you see, if we just wanted a top-3, requesting each shard to report on their top-5 solved the problem.
And to get an accurate top-5, requesting each shard sends their top-10 might well have solved our problem.
That's what shard_size does: it requests each node to report a larger amount of terms, so that we hopefully get a report for enough terms to lower the error-rate. Though it comes at the cost of needing some processing by each node, so setting it to a ridiculous value like int.MaxValue (like another answer is suggesting) is a very bad idea if you have a lot of documents.
Why doesn't elastic already do this by itself?
Surprise: it does. It's just not always enough, but if you experiment with the value, you'll see you can get worse results. By default (as mentioned in the docs), it uses size * 1.5 + 10, giving a value of 25 for the default top-10, or 40 for your use-case.