I wanted to perform moving average through timestamps. I have two columns: Temperature and timestamps (time-date) and I want to perform the moving average based on every 15 minutes successive temperature observations. In other words, selecting data to perform the average based on 15 minutes time interval. Moreover, it is possible to have different number of observations for different time sequences. I meant all the window sizes are equal (15 minutes) but it is possible to have different number of observations in each window. For example: For a first window we have to calculate the average of n observation and for second window calculate the average of the observation for n+5 observation.
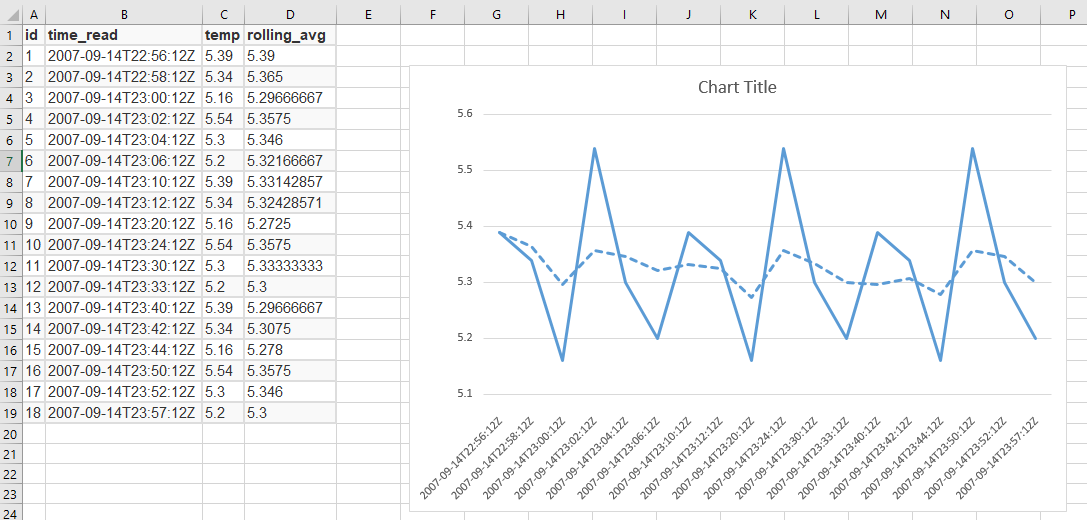
Data Sample:
ID Timestamps Temperature 1 2007-09-14 22:56:12 5.39 2 2007-09-14 22:58:12 5.34 3 2007-09-14 23:00:12 5.16 4 2007-09-14 23:02:12 5.54 5 2007-09-14 23:04:12 5.30 6 2007-09-14 23:06:12 5.20 7 2007-09-14 23:10:12 5.39 8 2007-09-14 23:12:12 5.34 9 2007-09-14 23:20:12 5.16 10 2007-09-14 23:24:12 5.54 11 2007-09-14 23:30:12 5.30 12 2007-09-14 23:33:12 5.20 13 2007-09-14 23:40:12 5.39 14 2007-09-14 23:42:12 5.34 15 2007-09-14 23:44:12 5.16 16 2007-09-14 23:50:12 5.54 17 2007-09-14 23:52:12 5.30 18 2007-09-14 23:57:12 5.20
Main Challenges:
How I can learn the code to discriminate every 15 minute while there are not exact 15 minutes time intervals due to different sampling frequency.