There are various ways to achieve that. Will leave below various options, that one can use, depending on specificities of one's use case.
One will consider that OP's dataframe is stored in the variable df.
Option 1
For OP's case, considering that the only column with values 0 is the line_race, the following will do the work
df_new = df[df != 0].dropna()
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
However, as that is not always the case, would recommend checking the following options where one will specify the column name.
Option 2
tshauck's approach ends up being better than Option 1, because one is able to specify the column. There are, however, additional variations depending on how one wants to refer to the column:
For example, using the position in the dataframe
df_new = df[df[df.columns[2]] != 0]
Or by explicitly indicating the column as follows
df_new = df[df['line_race'] != 0]
One can also follow the same login but using a custom lambda function, such as
df_new = df[df.apply(lambda x: x['line_race'] != 0, axis=1)]
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Option 3
Using pandas.Series.map and a custom lambda function
df_new = df['line_race'].map(lambda x: x != 0)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Option 4
Using pandas.DataFrame.drop as follows
df_new = df.drop(df[df['line_race'] == 0].index)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Option 5
Using pandas.DataFrame.query as follows
df_new = df.query('line_race != 0')
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Option 6
Using pandas.DataFrame.drop and pandas.DataFrame.query as follows
df_new = df.drop(df.query('line_race == 0').index)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.000000 56.000000
1 2007-03-10 83 11.0 67 1.000000 67.000000
2 2007-02-10 111 9.0 66 1.000000 66.000000
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
Option 7
If one doesn't have strong opinions on the output, one can use a vectorized approach with numpy.select
df_new = np.select([df != 0], [df], default=np.nan)
[Out]:
[['2007-03-31' 62 11.0 56 1.0 56.0]
['2007-03-10' 83 11.0 67 1.0 67.0]
['2007-02-10' 111 9.0 66 1.0 66.0]
['2007-01-13' 139 10.0 83 0.880678 73.096278]
['2006-12-23' 160 10.0 88 0.793033 69.786942]
['2006-11-09' 204 9.0 52 0.636655 33.106077]
['2006-10-22' 222 8.0 66 0.581946 38.408408]
['2006-09-29' 245 9.0 70 0.518825 36.317752]
['2006-09-16' 258 11.0 68 0.486226 33.063381]
['2006-08-30' 275 8.0 72 0.446667 32.160051]
['2006-02-11' 475 5.0 65 0.164591 10.698423]]
This can also be converted to a dataframe with
df_new = pd.DataFrame(df_new, columns=df.columns)
[Out]:
line_date daysago line_race rating rw wrating
0 2007-03-31 62 11.0 56 1.0 56.0
1 2007-03-10 83 11.0 67 1.0 67.0
2 2007-02-10 111 9.0 66 1.0 66.0
3 2007-01-13 139 10.0 83 0.880678 73.096278
4 2006-12-23 160 10.0 88 0.793033 69.786942
5 2006-11-09 204 9.0 52 0.636655 33.106077
6 2006-10-22 222 8.0 66 0.581946 38.408408
7 2006-09-29 245 9.0 70 0.518825 36.317752
8 2006-09-16 258 11.0 68 0.486226 33.063381
9 2006-08-30 275 8.0 72 0.446667 32.160051
10 2006-02-11 475 5.0 65 0.164591 10.698423
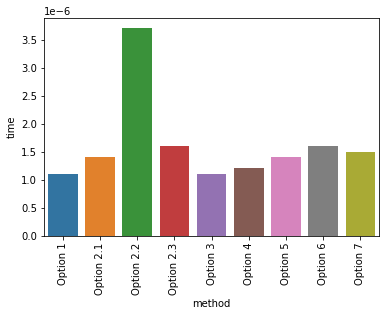
With regards to the most efficient solution, that would depend on how one wants to measure efficiency. Assuming that one wants to measure the time of execution, one way that one can go about doing it is with time.perf_counter().
If one measures the time of execution for all the options above, one gets the following
method time
0 Option 1 0.00000110000837594271
1 Option 2.1 0.00000139995245262980
2 Option 2.2 0.00000369996996596456
3 Option 2.3 0.00000160001218318939
4 Option 3 0.00000110000837594271
5 Option 4 0.00000120000913739204
6 Option 5 0.00000140001066029072
7 Option 6 0.00000159995397552848
8 Option 7 0.00000150001142174006
![enter image description here]()
However, this might change depending on the dataframe one uses, on the requirements (such as hardware), and more.
Notes: