Say you have N classes in your dataset. If you have 4 labels, dog (index 0), cat (1), donkey (2) and human (3), N would be 4.
Class modes:
"categorical": 2D output (aka. list of numbers of length N), [0, 0, 1, 0], which is a one-hot encoding (only one number is 1/ "hot") representing the donkey. This is for mutually exclusive labels. A dog cannot be a cat, a human is not a dog."binary": 1D output (aka. 1 number), which is either 0, 1, 2, 3 ... N. It is called this because it is binary if there are only two classes (IMHO this is a bad reason), source. I suggest using "binary" just for single label classification, because it documents-in-code, your intention."sparse": After digging in the code, this is the same as "binary". The logic is done with elif self.class_mode in {'binary', 'sparse'}:, and the class_mode is not used after that. I suggest using "sparse" for multilabel classification though, again because it documents-in-code, your intention."input": The label is literally the image again. So the label for an image of the dog, is the same dog picture array. If I knew more about autoencoders I might have been able to explain further.None: No labels, therefore not useful for training, but for inference/ prediction.
The TensorFlow documentation is here but I think it should go into more depth for class_mode:
One of "categorical", "binary", "sparse", "input", or None. Default: "categorical". Determines the type of label arrays that are returned: - "categorical" will be 2D one-hot encoded labels, - "binary" will be 1D binary labels, "sparse" will be 1D integer labels, - "input" will be images identical to input images (mainly used to work with autoencoders). - If None, no labels are returned (the generator will only yield batches of image data, which is useful to use with model.predict()). Please note that in case of class_mode None, the data still needs to reside in a subdirectory of directory for it to work correctly.
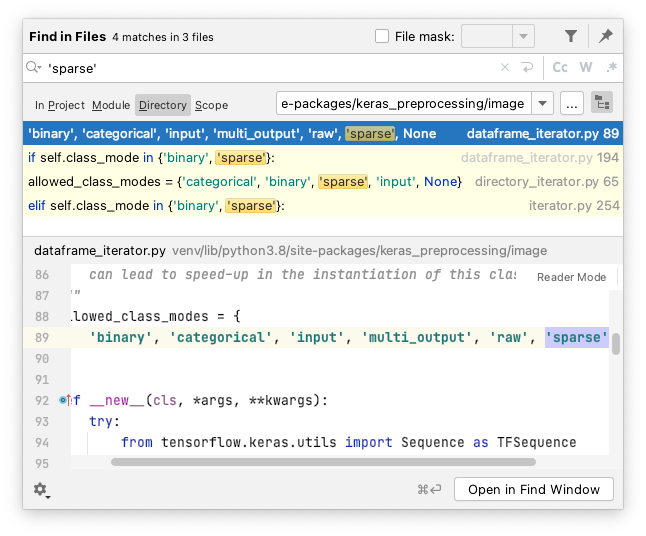
Sparse is the same as binary?:
As you can see in my search results, sparse is only checked twice (line 2 and 4 in search results). I believe the intention of "sparse" is for multi-label classification, and "binary" is designed for single-label classification (Hot-dog vs. No hotdog), but currently there is no difference, since the behaviour is the same:
![enter image description here]()