I do think you are trying to solve the problem in a bit wrong way. It might sound groundless, so I'd better show my results first.
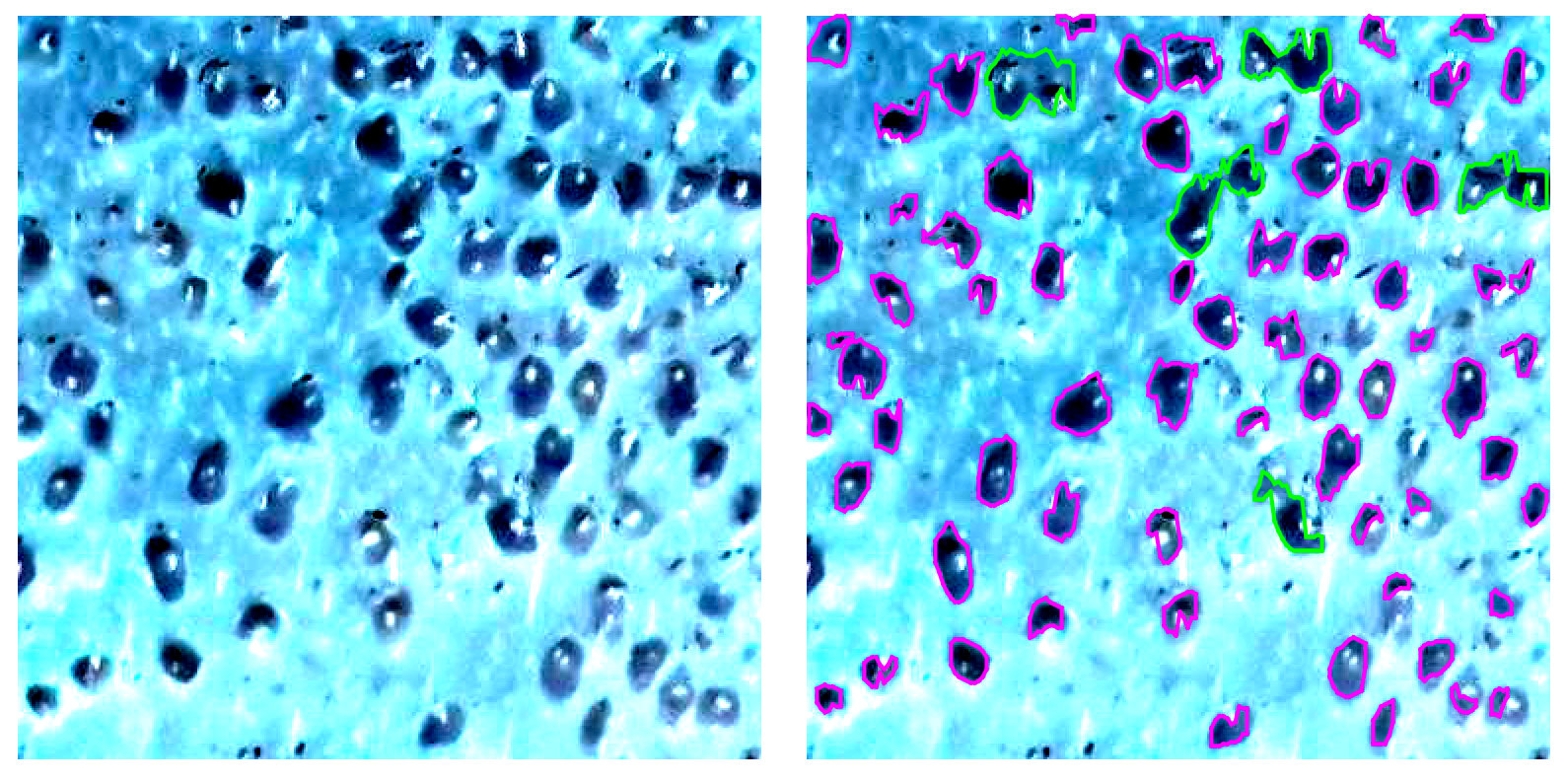
Below I have a crop of you image on the left and discovered transplants on the right. Green color is used to highlight areas with more than one transplant.
![enter image description here]()
The overall approach is very basic (will describe it later), but still it provides close to be accurate results. Please note, it was a first try, so there is a lot of room for enhancements.
Anyway, let's get back to the initial statement saying you approach is wrong. There are several major issues:
- the quality of your image is awful
- you say you want to find spots, but actually you are looking for hair transplant
objects
- you completely ignores the fact average head is far from being flat
- it does look like you think filters will add some important details to your initial image
- you expect algorithms to do magic for you
Let's review all these items one by one.
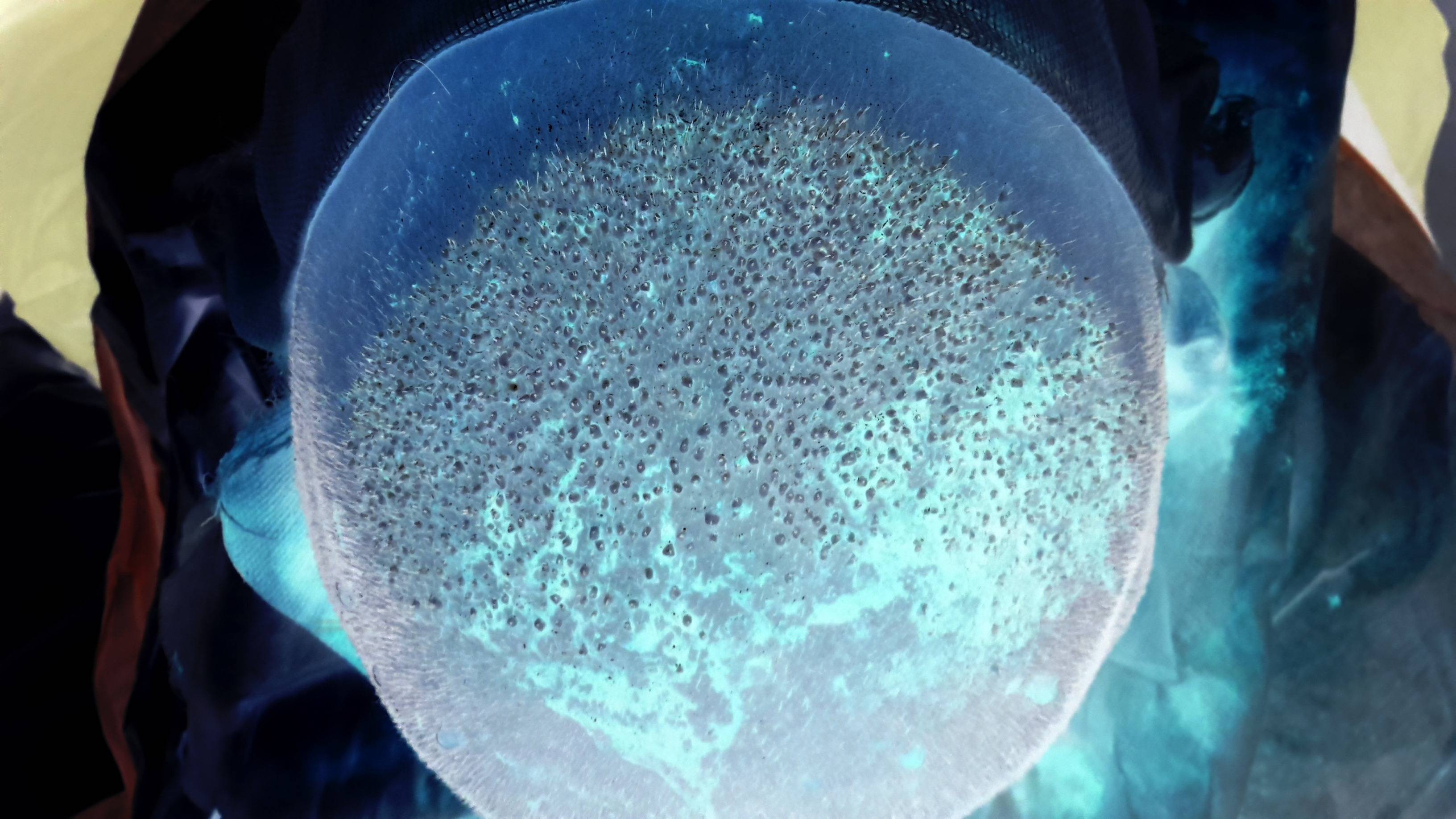
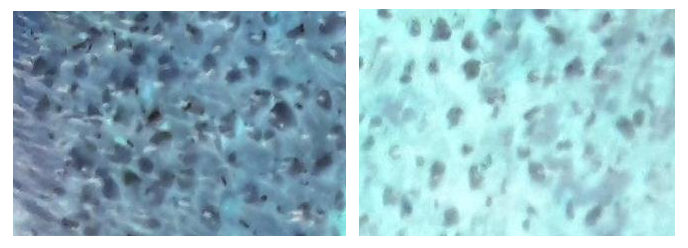
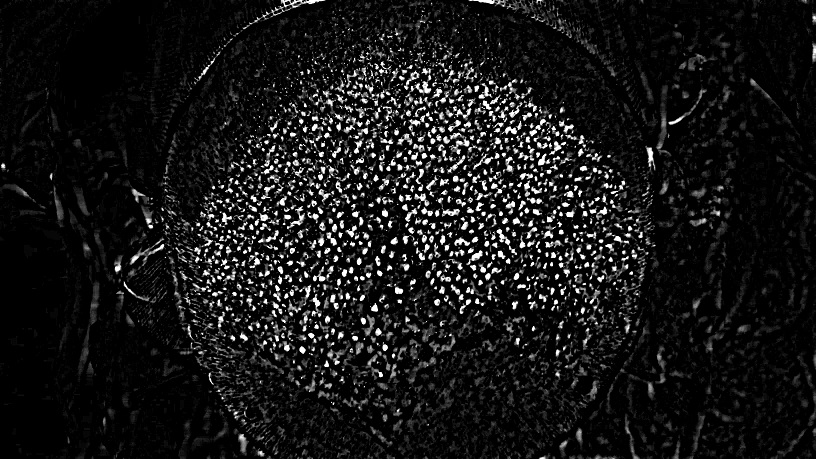
1. Image quality
It might be very obvious statement, but before the actual processing you need to make sure you have best possible initial data. You might spend weeks trying to find a way to process photos you have without any significant achievements. Here are some problematic areas:
![enter image description here]()
I bet it is hard for you to "read" those crops, despite the fact you have the most advanced object recognition algorithms in your brain.
Also, your time is expensive and you still need best possible accuracy and stability. So, for any reasonable price try to get: proper contrast, sharp edges, better colors and color separation.
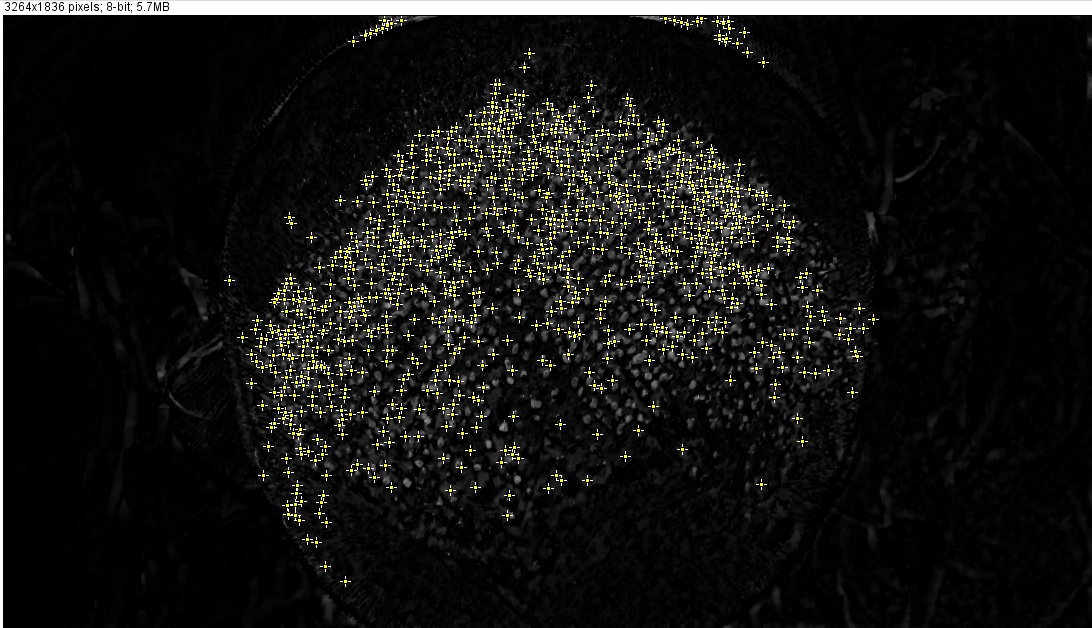
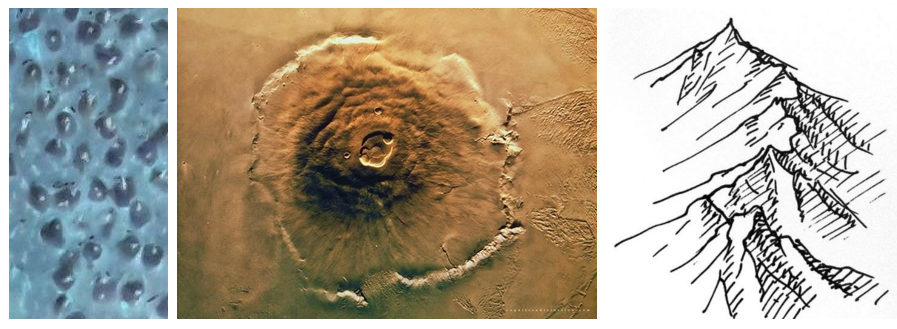
2. Better understanding of the objects to be identified
Generally speaking, you have a 3D objects to be identified. So you can analyze shadows in order to improve accuracy. BTW, it is almost like a Mars surface analysis :)
![enter image description here]()
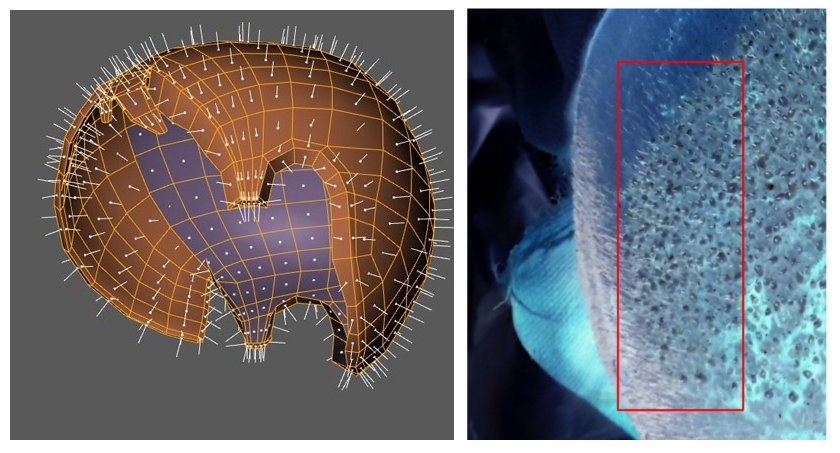
3. The form of the head should not be ignored
Because of the form of the head you have distortions. Again, in order to get proper accuracy those distortions should be corrected before the actual analysis. Basically, you need to flatten analyzed area.
![enter image description here]()
3D model source
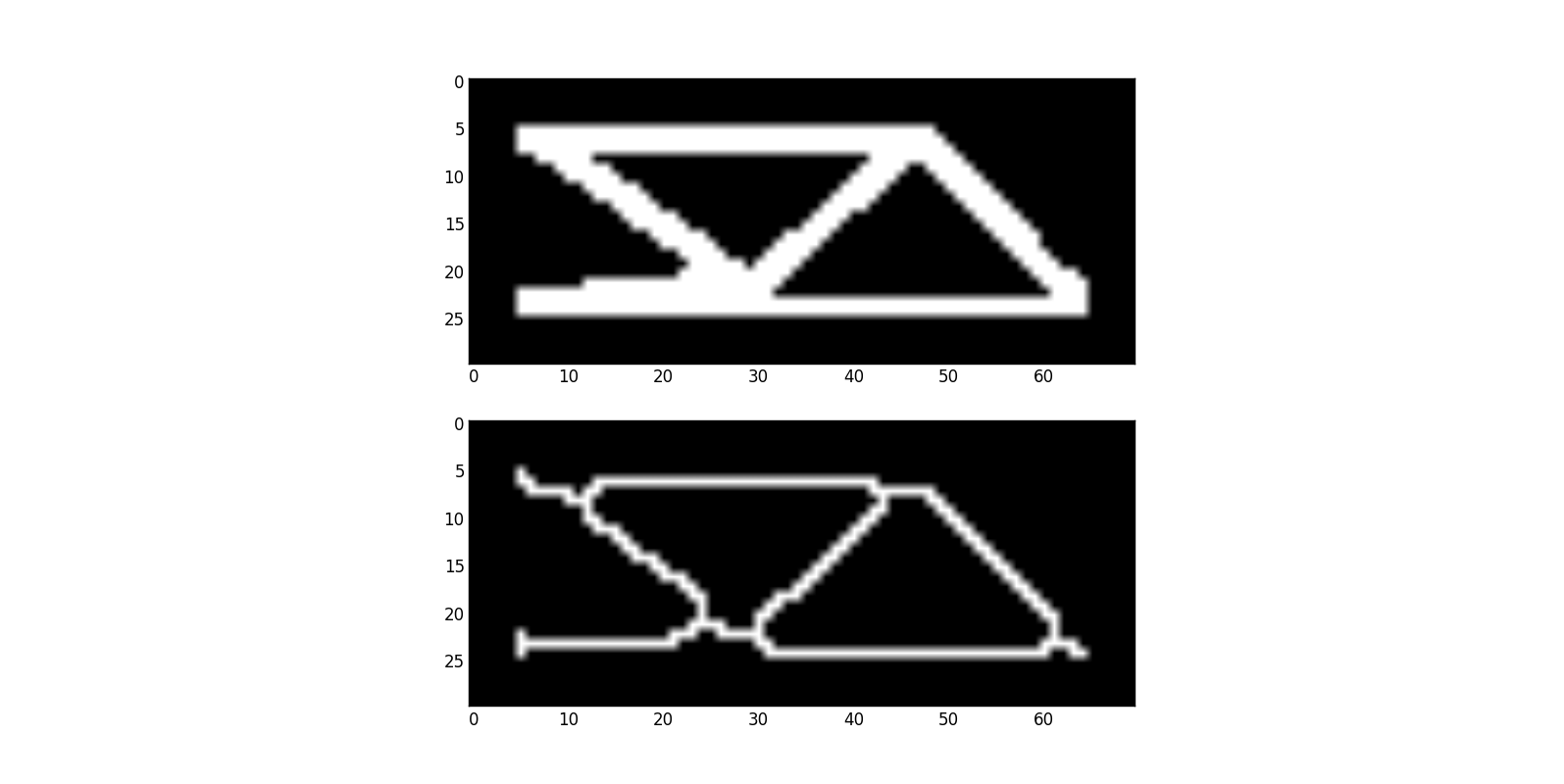
4. Filters might not help
Filters do not add information, but they can easily remove some important details. You've mentioned Hough transform, so here is interesting question: Find lines in shape
I will use this question as an example. Basically, you need to extract a geometry from a given picture. Lines in shape looks a bit complex, so you might decide to use skeletonization
![enter image description here]()
All of a sadden, you have more complex geometry to deal with and virtually no chances to understand what actually was on the original picture.
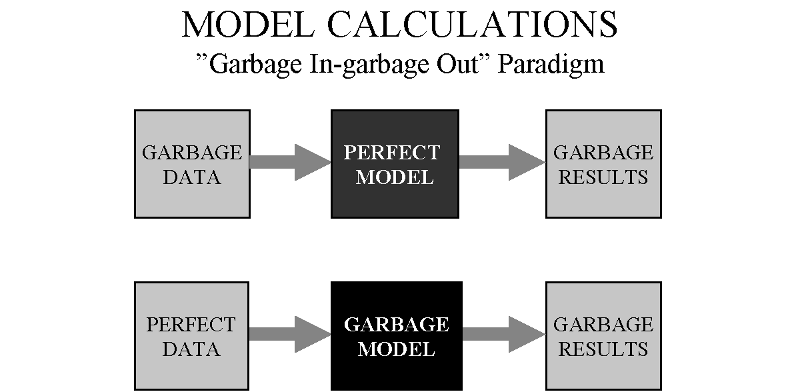
5. Sorry, no magic here
Please be aware of the following:
![enter image description here]()
You must try to get better data in order to achieve better accuracy and stability. The model itself is also very important.
Results explained
As I said, my approach is very simple: image was posterized and then I used very basic algorithm to identify areas with a specific color.
![enter image description here]()
Posterization can be done in a more clever way, areas detection can be improved, etc. For this PoC I just have a simple rule to highlight areas with more than one implant. Having areas identified a bit more advanced analysis can be performed.
Anyway, better image quality will let you use even simple method and get proper results.
Finally
How did the clinic manage to get Yondu as client? :)
![enter image description here]()
Update (tools and techniques)
- Posterization - GIMP (default settings,min colors)
- Transplant identification and visualization - Java program, no libraries or other dependencies
- Having areas identified it is easy to find average size, then compare to other areas and mark significantly bigger areas as multiple transplants.
Basically, everything is done "by hand". Horizontal and vertical scan, intersections give areas. Vertical lines are sorted and used to restore the actual shape. Solution is homegrown, code is a bit ugly, so do not want to share it, sorry.
The idea is pretty obvious and well explained (at least I think so). Here is an additional example with different scan step used:
![enter image description here]()
Yet another update
A small piece of code, developed to verify a very basic idea, evolved a bit, so now it can handle 4K video segmentation in real-time. The idea is the same: horizontal and vertical scans, areas defined by intersected lines, etc. Still no external libraries, just a lot of fun and a bit more optimized code.
![enter image description here]()
![enter image description here]()
Additional examples can be found on YouTube: RobotsCanSee
or follow the progress in Telegram: RobotsCanSee






{kind=link}
{kind=link}