I've compiled the following using Visual Studio C++ 2008 SP1, x64 C++ compiler:

I'm curious, why did compiler add those nop instructions after those calls?
PS1. I would understand that the 2nd and 3rd nops would be to align the code on a 4 byte margin, but the 1st nop breaks that assumption.
PS2. The C++ code that was compiled had no loops or special optimization stuff in it:
CTestDlg::CTestDlg(CWnd* pParent /*=NULL*/)
: CDialog(CTestDlg::IDD, pParent)
{
m_hIcon = AfxGetApp()->LoadIcon(IDR_MAINFRAME);
//This makes no sense. I used it to set a debugger breakpoint
::GdiFlush();
srand(::GetTickCount());
}
PS3. Additional Info: First off, thank you everyone for your input.
Here's additional observations:
My first guess was that incremental linking could've had something to do with it. But, the
Releasebuild settings in theVisual Studiofor the project haveincremental linkingoff.This seems to affect
x64builds only. The same code built asx86(orWin32) does not have thosenops, even though instructions used are very similar:

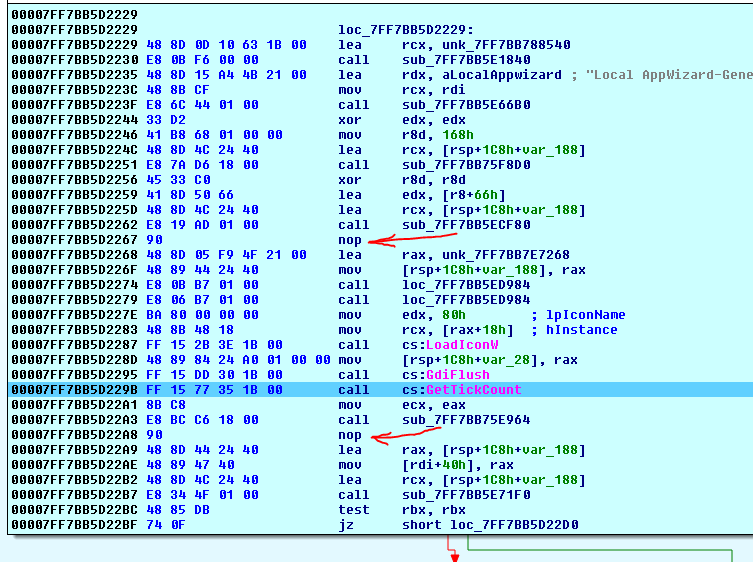
- I tried to build it with a newer linker, and even though the
x64code produced byVS 2013looks somewhat different, it still adds thosenops after somecalls:
- Also
dynamicvsstaticlinking to MFC made no difference on presence of thosenops. This one is built with dynamical linking to MFC dlls withVS 2013:
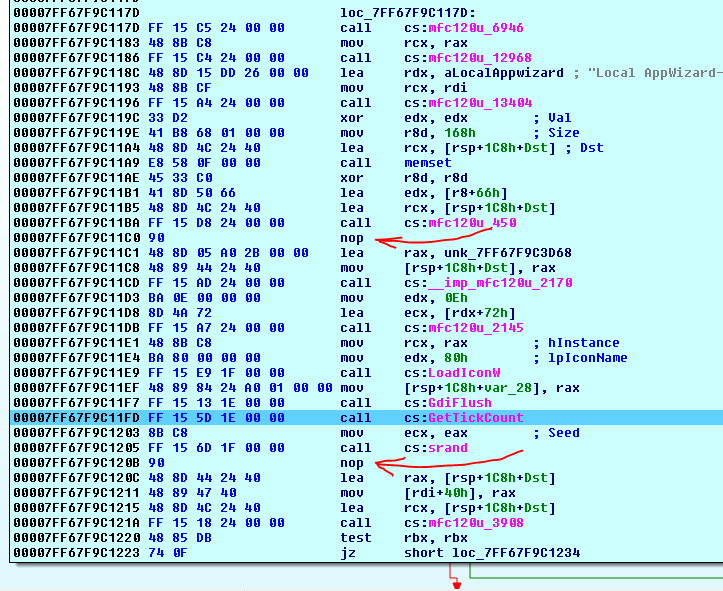
- Also note that those
nops can appear afternearandfarcalls as well, and they have nothing to do with alignment. Here's a part of the code that I got fromIDAif I step a little bit further on:
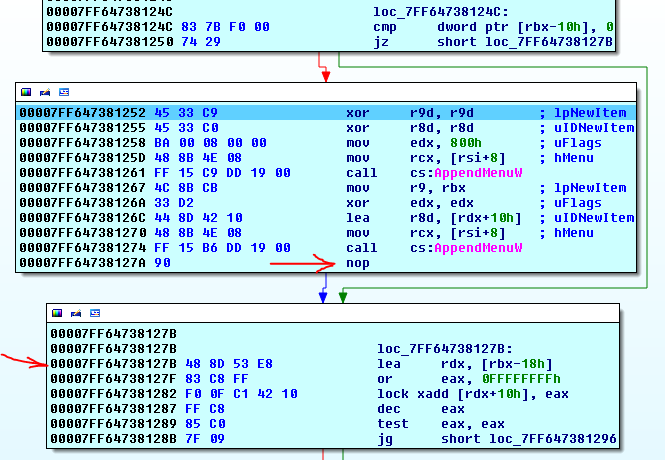
As you see, the nop is inserted after a far call that happens to "align" the next lea instruction on the B address! That makes no sense if those were added for alignment only.
- I was originally inclined to believe that since
nearrelativecalls (i.e. those that start withE8) are somewhat faster thanfarcalls (or the ones that start withFF,15in this case)

the linker may try to go with near calls first, and since those are one byte shorter than far calls, if it succeeds, it may pad the remaining space with nops at the end. But then the example (5) above kinda defeats this hypothesis.
So I still don't have a clear answer to this.
call cs:LoadIconWinstruction in the disassembly above is an example of this. The location the disassembler has calledLoadIconWcontains a pointer to the actualLoadIconWfunction. – Harbouragecallinstruction with a prefix, but I'm not sure that's guaranteed to be future-proof. Some future ISA extension might userep callto mean something special. I tested, andcallworks on Skylake when preceded byrep, or0x40(REX.W=0), or0x48(REX.W=1). I'd guess that a REX prefix is more future-proof. A linker would need to check that there wasn't already a REX prefix, though (e.g. from hand-written code with padding), and that's impossible because you can't unambiguously step backwards in x86. Multiple REP prefixes would be ok – Blackingtoncallorjmpinstruction, right? The opcode has to change from indirect to rel32. (Hmm, prefixes onjccinstructions have special meaning as branch-prediction hints on P4. Butjcccan't be indirect anyway, so could only appear for conditional tailcalls that were already using a direct jump.) – BlackingtonREXhas to be the last prefix if it appears, so checking the byte before thecallopcode can give false positives (previous instruction ended with0x4?), but not false negatives. – Blackingtoncallon pretty much everything and highly unlikely to ever change the meaning ofcall? That's what GNU ld is using. – Rosarosabelsyscallandsysenter, but no OS I'm aware of uses them). The difference is direct vs indirect. – Rosarosabelnops are still there even with dynamic linking, the linker relaxation idea's gotta be wrong then. – Rosarosabelcall/nop: « add the necessary call/nop to those functions within the “.init” section » (cseweb.ucsd.edu/~gbournou/CSE131/GlobalAndStaticVars.pdf) But them doesn't explain why. Makes the answers here not very satisfying to me. – Sachsse