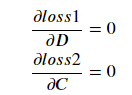From model documentation:
loss: String (name of objective function) or objective function. See losses. If the model has multiple outputs, you can use a different loss on each output by passing a dictionary or a list of losses. The loss value that will be minimized by the model will then be the sum of all individual losses.
...
loss_weights: Optional list or dictionary specifying scalar coefficients (Python floats) to weight the loss contributions of different model outputs. The loss value that will be minimized by the model will then be the weighted sum of all individual losses, weighted by the loss_weights coefficients. If a list, it is expected to have a 1:1 mapping to the model's outputs. If a tensor, it is expected to map output names (strings) to scalar coefficients.
So, yes, the final loss will be the "weighted sum of all individual losses, weighted by the loss_weights coeffiecients".
You can check the code where the loss is calculated.
Also, what does it mean during training? Is the loss2 only used to update the weights on layers where y2 comes from? Or is it used for all the model's layers?
The weights are updated through backpropagation, so each loss will affect only layers that connect the input to the loss.
For example:
+----+
> C |-->loss1
/+----+
/
/
+----+ +----+/
-->| A |--->| B |\
+----+ +----+ \
\
\+----+
> D |-->loss2
+----+
loss1 will affect A, B, and C.loss2 will affect A, B, and D.