I have a problem statement at hand wherein I want to unpivot table in Spark SQL / PySpark. I have gone through the documentation and I could see there is support only for pivot, but no support for un-pivot so far.
Is there a way I can achieve this?
Let my initial table look like this:
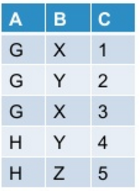
When I pivot this in PySpark:
df.groupBy("A").pivot("B").sum("C")
I get this as the output:
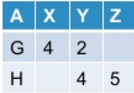
Now I want to unpivot the pivoted table. In general, this operation may/may not yield the original table based on how I've pivoted the original table.
Spark SQL as of now doesn't provide out of the box support for unpivot. Is there a way I can achieve this?
A,B? Do you always want rows for X,Y and Z even if there is no value for them (e.g. there is no Z for G)? – Homager