Is a read on an atomic variable guaranteed to acquire the current value of it
No
Even though each atomic variable has a single modification order (which is observed by all threads), that does not mean that all threads observe modifications at the same time scale.
Consider this code:
std::atomic<int> g{0};
// thread 1
g.store(42);
// thread 2
int a = g.load();
// do stuff with a
int b = g.load();
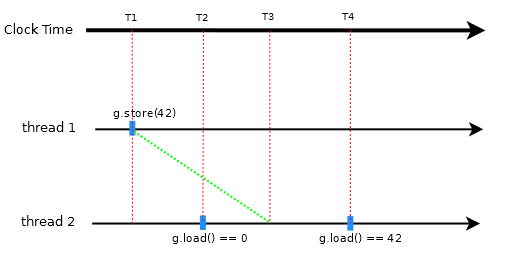
A possible outcome is (see diagram):
- thread 1: 42 is stored at time T1
- thread 2: the first load returns 0 at time T2
- thread 2: the store from thread 1 becomes visible at time T3
- thread 2: the second load returns 42 at time T4.
![enter image description here]()
This outcome is possible even though the first load at time T2 occurs after the store at T1 (in clock time).
The standard says:
Implementations should make atomic stores visible to atomic loads within a reasonable amount of time.
It does not require a store to become visible right away and it even allows room for a store to remain invisible (e.g. on systems without cache-coherency).
In that case, an atomic read-modify-write (RMW) is required to access the last value.
Atomic read-modify-write operations shall always read the last value (in the modification order) written
before the write associated with the read-modify-write operation.
Needless to say, RMW's are more expensive to execute (they lock the bus) and that is why a regular atomic load is allowed to return an older (cached) value.
If a regular load was required to return the last value, performance would be horrible while there would be hardly any benefit.