I am trying to create a new column 'ab_weighted' in a Pandas dataframe based on two columns 'a','b' in that dataframe grouped by 'c'.
Specifically, I am trying to replicate the output from this R code:
library(data.table)
df = data.table(a = 1:6,
b = 7:12,
c = c('q', 'q', 'q', 'q', 'w', 'w')
)
df[, ab_weighted := sum(a)/sum(b), by = "c"]
df[, c('c', 'a', 'b', 'ab_weighted')]
Output:

So far, I tried the following in Python:
import pandas as pd
df = pd.DataFrame({'a':[1,2,3,4,5,6],
'b':[7,8,9,10,11,12],
'c':['q', 'q', 'q', 'q', 'w', 'w']
})
df.groupby(['c'])['a', 'b'].apply(lambda x: sum(x['a'])/sum(x['b']))
Output:

When I change the apply in the code above to transform I get an error:
TypeError: an integer is required
transform() works fine, if I use only a single column though:
import pandas as pd
df = pd.DataFrame({'a':[1,2,3,4,5,6],
'b':[7,8,9,10,11,12],
'c':['q', 'q', 'q', 'q', 'w', 'w']
})
df.groupby(['c'])['a', 'b'].transform(lambda x: sum(x))
But obviously, this is not the same answer:
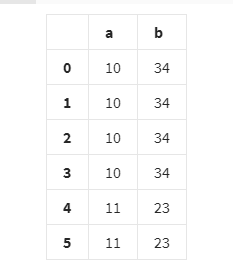
Is there a way to get the result from my R data.table code in Pandas without having to generate intermediate columns (i.e. use pandas transform to directly generate the final column (ab_weighted = sum(a)/sum(b))?
df.groupby(['c'])['a', 'b']...should readdf.groupby('c')[['a', 'b']]...– Tarragona