For the final, definitive answer to this question, jump straight down to the section below titled "Final answer to my question".
UPDATE 30 Oct. 2018: I was accidentally referencing the (slightly) wrong documents (but which said the exact same thing), so I've fixed them in my answer here. See "Notes about the 30 Oct. 2018 changes" at bottom of this answer for details.
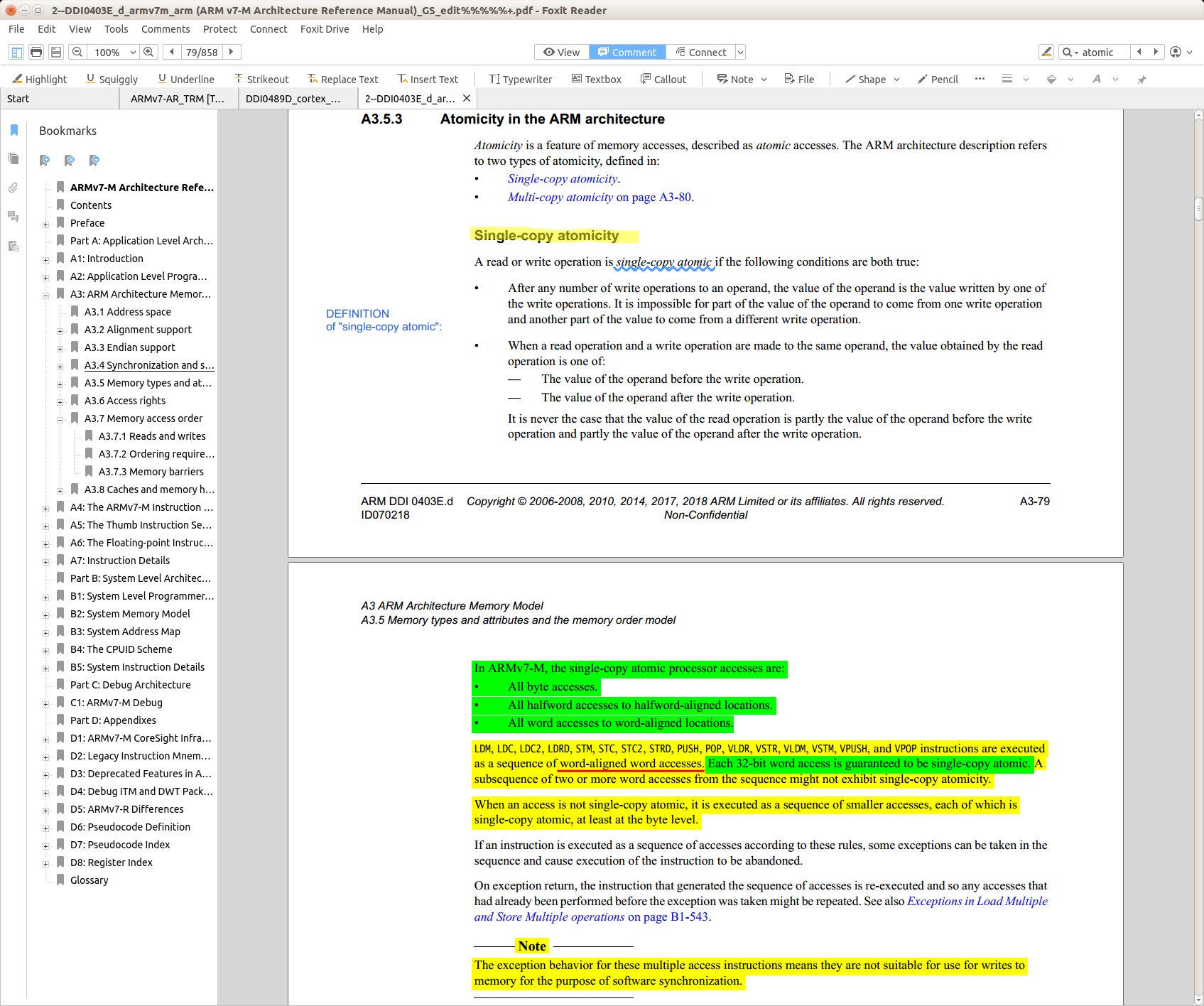
I definitely don't understand every word here, but the ARM v7-M Architecture Reference Manual (Online source; PDF file direct download) (NOT the Technical Reference Manual [TRM], since it doesn't discuss atomicity) validates my assumptions:
![enter image description here]()
So...I think my 7 assumptions at the bottom of my question are all correct. [30 Oct. 2018: Yes, that is correct. See below for details.]
UPDATE 29 Oct. 2018:
One more little tidbit: FreeRTOS is sure on this
...and it's used in thousands of safety-critical applications world-wide.
Richard Barry, FreeRTOS founder, expert, and core developer, states in tasks.c in two different places (ex: here in the official FreeRTOS V11.0.1 release) that:
/* A critical section is not required because the variables are of type BaseType_t. */
And, for most (all?) 32-bit microcontrollers, such as STM32F4 ARM Cortex-M4 with floating point unit (hence the folder name ARM_CM4F), you can see here in FreeRTOS-Kernel/portable/GCC/ARM_CM4F/portmacro.h that BaseType_t is typedefed as long, and UBaseType_t is typedefed as unsigned long:
typedef long BaseType_t;
typedef unsigned long UBaseType_t;
...and in the code where the above "critical section is not required" comments are, the variables in question are of type UBaseType_t. Furthermore, long for these chips is int32_t (4 bytes), and unsigned long is uint32_t (4 bytes). So, this means that Richard Barry is saying that 4-byte reads and writes are atomic on these 32-bit microcontrollers. This means that he, at least, is 100% sure 4-byte reads and writes are atomic on STM32. He doesn't mention smaller-byte reads, but for 4-byte reads he is conclusively sure. I have to assume that 4-byte variables being the native processor width, and also, word-aligned, is critical to this being true.
Note that the FreeRTOS version number is found in task.h, here. Here are the two code and comment snippets from tasks.c in FreeRTOS V11.0.1 where he states that a critical section is not required because the variables are of type BaseType_t (or UBaseType_t):
void vTaskSuspendAll( void )
{
traceENTER_vTaskSuspendAll();
#if ( configNUMBER_OF_CORES == 1 )
{
/* A critical section is not required as the variable is of type
* BaseType_t. Please read Richard Barry's reply in the following link to a
* post in the FreeRTOS support forum before reporting this as a bug! -
* https:// goo.gl/wu4acr */
/* portSOFTWARE_BARRIER() is only implemented for emulated/simulated ports that
* do not otherwise exhibit real time behaviour. */
portSOFTWARE_BARRIER();
/* The scheduler is suspended if uxSchedulerSuspended is non-zero. An increment
* is used to allow calls to vTaskSuspendAll() to nest. */
++uxSchedulerSuspended;
/* Enforces ordering for ports and optimised compilers that may otherwise place
* the above increment elsewhere. */
portMEMORY_BARRIER();
}
...
UBaseType_t uxTaskGetNumberOfTasks( void )
{
traceENTER_uxTaskGetNumberOfTasks();
/* A critical section is not required because the variables are of type
* BaseType_t. */
traceRETURN_uxTaskGetNumberOfTasks( uxCurrentNumberOfTasks );
return uxCurrentNumberOfTasks;
}
The short goo.gl link in the first comment above leads to this full link: FreeRTOS Support Archive: Concerns about the atomicity of vTaskSuspendAll(). The key here is that Richard is relying on each individual 4-byte read or write being naturally atomic on this hardware.
Final answer to my question: all types <= 4 bytes (all bolded types in the list of 9 rows below) are atomic.
Furthermore, upon closer inspection of the TRM on p141 as shown in my screenshot above, the key sentences I'd like to point out are:
In ARMv7-M, the single-copy atomic processor accesses are:
• all byte accesses.
• all halfword accesses to halfword-aligned locations.
• all word accesses to word-aligned locations.
And, per this link, the following is true for "basic data types implemented in ARM C and C++" (ie: on STM32):
bool/_Bool is "byte-aligned" (1-byte-aligned)int8_t/uint8_t is "byte-aligned" (1-byte-aligned)int16_t/uint16_t is "halfword-aligned" (2-byte-aligned)int32_t/uint32_t is "word-aligned" (4-byte-aligned)int64_t/uint64_t is "doubleword-aligned" (8-byte-aligned) <-- NOT GUARANTEED ATOMICfloat is "word-aligned" (4-byte-aligned)double is "doubleword-aligned" (8-byte-aligned) <-- NOT GUARANTEED ATOMIClong double is "doubleword-aligned" (8-byte-aligned) <-- NOT GUARANTEED ATOMIC- all pointers are "word-aligned" (4-byte-aligned)
This means that I now have and understand the evidence I need to conclusively state that all bolded rows just above have automatic atomic read and write access (but NOT increment/decrement of course, which is multiple operations). This is the final answer to my question. The only exception to this atomicity might be in packed structs I think, in which case these otherwise-naturally-aligned data types may not be naturally aligned.
Also note that when reading the Technical Reference Manual, "single-copy atomicity" apparently just means "single-core-CPU atomicity", or "atomicity on a single-CPU-core architecture." This is in contrast to "multi-copy atomicity", which refers to a "mutliprocessing system", or multi-core-CPU architecture. Wikipedia states "multiprocessing is the use of two or more central processing units (CPUs) within a single computer system" (https://en.wikipedia.org/wiki/Multiprocessing).
My architecture in question, STM32F767ZI (with ARM Cortex-M7 core), is a single-core architecture, so apparently "single-copy atomicity", as I've quoted above from the TRM, applies.
Further Reading:
Notes about the 30 Oct. 2018 changes:
- I had this reference: ARMv7 TRM (Technical Reference Manual). However, this is wrong in 2 ways: 1) This isn't a TRM at all! The TRM is a short (~200 pgs) Technical Reference Manual. This, however, is the "Architecture Reference Manual", NOT the TRM. It is a much longer and more generic document, as Architecture reference manuals are on the order of ~1000~2000 pgs it turns out. 2) This is for the ARMv7-A and ARMv7-R processors, but the manual I need for the STM32 mcu in question is for the ARMv7-M processor.
- Here is the correct link to the ARM Cortex-M7 Processor Technical Reference Manual. Online: https://developer.arm.com/docs/ddi0489/latest. PDF: https://static.docs.arm.com/ddi0489/d/DDI0489D_cortex_m7_trm.pdf.
- The correct TRM just above, on p99 (5-36) says, "For more
information on atomicity, see the ARM®v7-M Architecture Reference Manual." So, here is that manual. Online download link: https://developer.arm.com/products/architecture/cpu-architecture/m-profile/docs/ddi0403/latest/armv7-m-architecture-reference-manual. PDF: https://static.docs.arm.com/ddi0489/d/DDI0489D_cortex_m7_trm.pdf. It discusses atomicity on p79-80 (A3-79 to A3-80).
To create atomic access guards (usually by turning off interrupts when reads and writes are not atomic) see:
- [my Q&A] What are the various ways to disable and re-enable interrupts in STM32 microcontrollers in order to implement atomic access guards?
- My
doAtomicRead() func here which can do atomic reads withOUT turning off interrupts