Quick answer
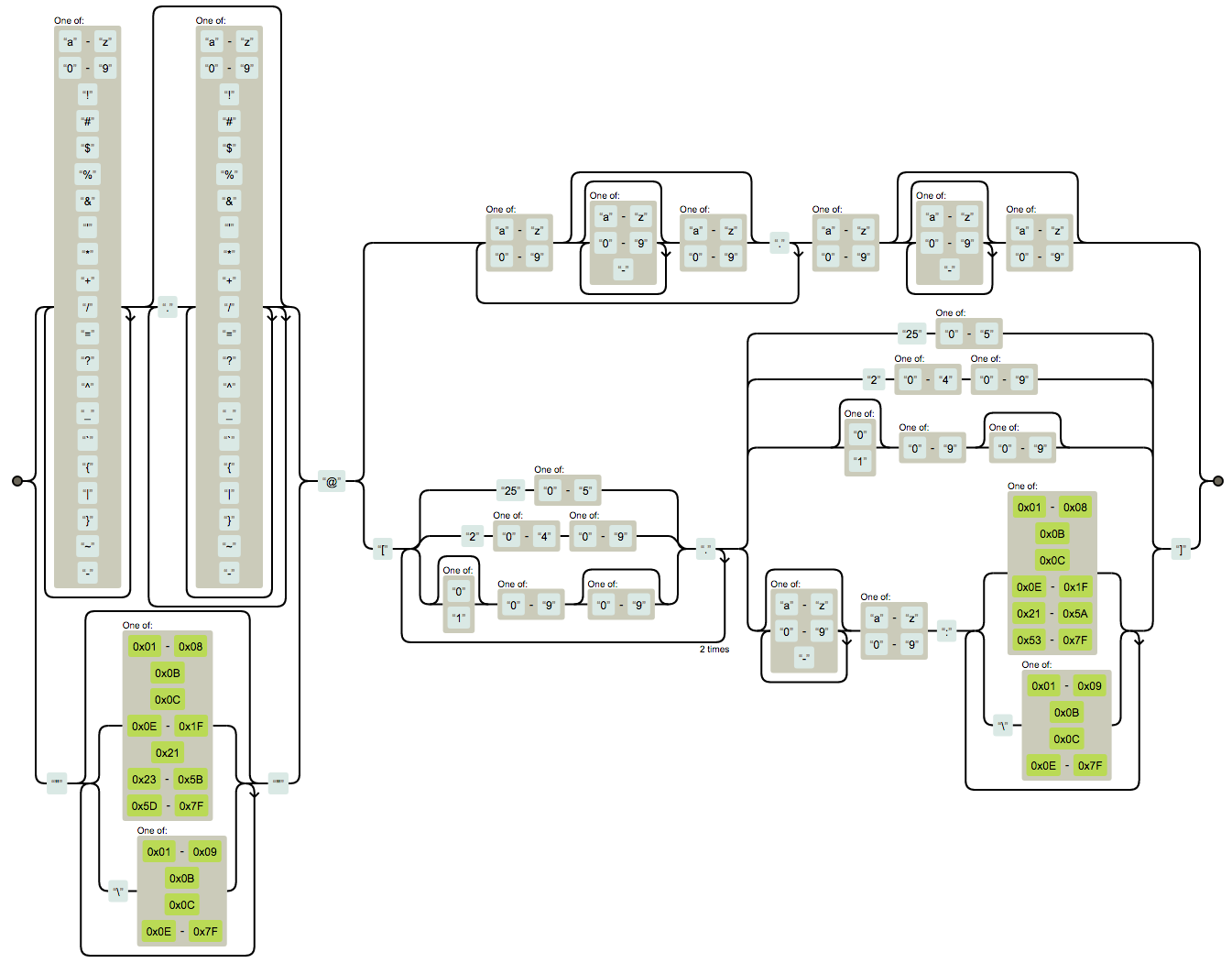
Use the following regex for input validation:
([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?(\.[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?)+
Addresses matched by this regex:
- have a local part (i.e. the part before the @-sign) that is strictly compliant with RFC 5321/5322,
- have a domain part (i.e. the part after the @-sign) that is a host name with at least two labels, each of which is at most 63 characters long.
The second constraint is a restriction on RFC 5321/5322.
Elaborate answer
Using a regular expression that recognizes email addresses could be useful in various situations: for example to scan for email addresses in a document, to validate user input, or as an integrity constraint on a data repository.
It should however be noted that if you want to find out if the address actually refers to an existing mailbox, there's no substitute for sending a message to the address. If you only want to check if an address is grammatically correct then you could use a regular expression, but note that ""@[] is a grammatically correct email address that certainly doesn't refer to an existing mailbox.
The syntax of email addresses has been defined in various RFCs, most notably RFC 822 and RFC 5322. RFC 822 should be seen as the "original" standard and RFC 5322 as the latest standard. The syntax defined in RFC 822 is the most lenient and subsequent standards have restricted the syntax further and further, where newer systems or services should recognize obsolete syntax, but never produce it.
In this answer I’ll take “email address” to mean addr-spec as defined in the RFCs (i.e. [email protected], but not "John Doe"<[email protected]>, nor some-group:[email protected],[email protected];).
There's one problem with translating the RFC syntaxes into regexes: the syntaxes are not regular! This is because they allow for optional comments in email addresses that can be infinitely nested, while infinite nesting can't be described by a regular expression. To scan for or validate addresses containing comments you need a parser or more powerful expressions. (Note that languages like Perl have constructs to describe context free grammars in a regex-like way.) In this answer I'll disregard comments and only consider proper regular expressions.
The RFCs define syntaxes for email messages, not for email addresses as such. Addresses may appear in various header fields and this is where they are primarily defined. When they appear in header fields addresses may contain (between lexical tokens) whitespace, comments and even linebreaks. Semantically this has no significance however. By removing this whitespace, etc. from an address you get a semantically equivalent canonical representation. Thus, the canonical representation of first. last (comment) @ [3.5.7.9] is first.last@[3.5.7.9].
Different syntaxes should be used for different purposes. If you want to scan for email addresses in a (possibly very old) document it may be a good idea to use the syntax as defined in RFC 822. On the other hand, if you want to validate user input you may want to use the syntax as defined in RFC 5322, probably only accepting canonical representations. You should decide which syntax applies to your specific case.
I use POSIX "extended" regular expressions in this answer, assuming an ASCII compatible character set.
RFC 822
I arrived at the following regular expression. I invite everyone to try and break it. If you find any false positives or false negatives, please post them in a comment and I'll try to fix the expression as soon as possible.
([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]))*(\\\r)*")(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]))*(\\\r)*"))*@([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]))*(\\\r)*])(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]))*(\\\r)*]))*
I believe it's fully compliant with RFC 822 including the errata. It only recognizes email addresses in their canonical form. For a regex that recognizes (folding) whitespace see the derivation below.
The derivation shows how I arrived at the expression. I list all the relevant grammar rules from the RFC exactly as they appear, followed by the corresponding regex. Where an erratum has been published I give a separate expression for the corrected grammar rule (marked "erratum") and use the updated version as a subexpression in subsequent regular expressions.
As stated in paragraph 3.1.4. of RFC 822 optional linear white space may be inserted between lexical tokens. Where applicable I've expanded the expressions to accommodate this rule and marked the result with "opt-lwsp".
CHAR = <any ASCII character>
=~ .
CTL = <any ASCII control character and DEL>
=~ [\x00-\x1F\x7F]
CR = <ASCII CR, carriage return>
=~ \r
LF = <ASCII LF, linefeed>
=~ \n
SPACE = <ASCII SP, space>
=~
HTAB = <ASCII HT, horizontal-tab>
=~ \t
<"> = <ASCII quote mark>
=~ "
CRLF = CR LF
=~ \r\n
LWSP-char = SPACE / HTAB
=~ [ \t]
linear-white-space = 1*([CRLF] LWSP-char)
=~ ((\r\n)?[ \t])+
specials = "(" / ")" / "<" / ">" / "@" / "," / ";" / ":" / "\" / <"> / "." / "[" / "]"
=~ [][()<>@,;:\\".]
quoted-pair = "\" CHAR
=~ \\.
qtext = <any CHAR excepting <">, "\" & CR, and including linear-white-space>
=~ [^"\\\r]|((\r\n)?[ \t])+
dtext = <any CHAR excluding "[", "]", "\" & CR, & including linear-white-space>
=~ [^][\\\r]|((\r\n)?[ \t])+
quoted-string = <"> *(qtext|quoted-pair) <">
=~ "([^"\\\r]|((\r\n)?[ \t])|\\.)*"
(erratum) =~ "(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*"
domain-literal = "[" *(dtext|quoted-pair) "]"
=~ \[([^][\\\r]|((\r\n)?[ \t])|\\.)*]
(erratum) =~ \[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]
atom = 1*<any CHAR except specials, SPACE and CTLs>
=~ [^][()<>@,;:\\". \x00-\x1F\x7F]+
word = atom / quoted-string
=~ [^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*"
domain-ref = atom
sub-domain = domain-ref / domain-literal
=~ [^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]
local-part = word *("." word)
=~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*")(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*"))*
(opt-lwsp) =~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*")(((\r\n)?[ \t])*\.((\r\n)?[ \t])*([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*"))*
domain = sub-domain *("." sub-domain)
=~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*])(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]))*
(opt-lwsp) =~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*])(((\r\n)?[ \t])*\.((\r\n)?[ \t])*([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]))*
addr-spec = local-part "@" domain
=~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*")(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*"))*@([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*])(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]))*
(opt-lwsp) =~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*")((\r\n)?[ \t])*(\.((\r\n)?[ \t])*([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*")((\r\n)?[ \t])*)*@((\r\n)?[ \t])*([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*])(((\r\n)?[ \t])*\.((\r\n)?[ \t])*([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]|(\r\n)?[ \t]))*(\\\r)*]))*
(canonical) =~ ([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]))*(\\\r)*")(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|"(\n|(\\\r)*([^"\\\r\n]|\\[^\r]))*(\\\r)*"))*@([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]))*(\\\r)*])(\.([^][()<>@,;:\\". \x00-\x1F\x7F]+|\[(\n|(\\\r)*([^][\\\r\n]|\\[^\r]))*(\\\r)*]))*
RFC 5322
I arrived at the following regular expression. I invite everyone to try and break it. If you find any false positives or false negatives, please post them in a comment and I'll try to fix the expression as soon as possible.
([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|\[[\t -Z^-~]*])
I believe it's fully compliant with RFC 5322 including the errata. It only recognizes email addresses in their canonical form. For a regex that recognizes (folding) whitespace see the derivation below.
The derivation shows how I arrived at the expression. I list all the relevant grammar rules from the RFC exactly as they appear, followed by the corresponding regex. For rules that include semantically irrelevant (folding) whitespace, I give a separate regex marked "(normalized)" that doesn't accept this whitespace.
I ignored all the "obs-" rules from the RFC. This means that the regexes only match email addresses that are strictly RFC 5322 compliant. If you have to match "old" addresses (as the looser grammar including the "obs-" rules does), you can use one of the RFC 822 regexes from the previous paragraph.
VCHAR = %x21-7E
=~ [!-~]
ALPHA = %x41-5A / %x61-7A
=~ [A-Za-z]
DIGIT = %x30-39
=~ [0-9]
HTAB = %x09
=~ \t
CR = %x0D
=~ \r
LF = %x0A
=~ \n
SP = %x20
=~
DQUOTE = %x22
=~ "
CRLF = CR LF
=~ \r\n
WSP = SP / HTAB
=~ [\t ]
quoted-pair = "\" (VCHAR / WSP)
=~ \\[\t -~]
FWS = ([*WSP CRLF] 1*WSP)
=~ ([\t ]*\r\n)?[\t ]+
ctext = %d33-39 / %d42-91 / %d93-126
=~ []!-'*-[^-~]
("comment" is left out in the regex)
ccontent = ctext / quoted-pair / comment
=~ []!-'*-[^-~]|(\\[\t -~])
(not regular)
comment = "(" *([FWS] ccontent) [FWS] ")"
(is equivalent to FWS when leaving out comments)
CFWS = (1*([FWS] comment) [FWS]) / FWS
=~ ([\t ]*\r\n)?[\t ]+
atext = ALPHA / DIGIT / "!" / "#" / "$" / "%" / "&" / "'" / "*" / "+" / "-" / "/" / "=" / "?" / "^" / "_" / "`" / "{" / "|" / "}" / "~"
=~ [-!#-'*+/-9=?A-Z^-~]
dot-atom-text = 1*atext *("." 1*atext)
=~ [-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*
dot-atom = [CFWS] dot-atom-text [CFWS]
=~ (([\t ]*\r\n)?[\t ]+)?[-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*(([\t ]*\r\n)?[\t ]+)?
(normalized) =~ [-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*
qtext = %d33 / %d35-91 / %d93-126
=~ []!#-[^-~]
qcontent = qtext / quoted-pair
=~ []!#-[^-~]|(\\[\t -~])
(erratum)
quoted-string = [CFWS] DQUOTE ((1*([FWS] qcontent) [FWS]) / FWS) DQUOTE [CFWS]
=~ (([\t ]*\r\n)?[\t ]+)?"(((([\t ]*\r\n)?[\t ]+)?([]!#-[^-~]|(\\[\t -~])))+(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?)"(([\t ]*\r\n)?[\t ]+)?
(normalized) =~ "([]!#-[^-~ \t]|(\\[\t -~]))+"
dtext = %d33-90 / %d94-126
=~ [!-Z^-~]
domain-literal = [CFWS] "[" *([FWS] dtext) [FWS] "]" [CFWS]
=~ (([\t ]*\r\n)?[\t ]+)?\[((([\t ]*\r\n)?[\t ]+)?[!-Z^-~])*(([\t ]*\r\n)?[\t ]+)?](([\t ]*\r\n)?[\t ]+)?
(normalized) =~ \[[\t -Z^-~]*]
local-part = dot-atom / quoted-string
=~ (([\t ]*\r\n)?[\t ]+)?[-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?"(((([\t ]*\r\n)?[\t ]+)?([]!#-[^-~]|(\\[\t -~])))+(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?)"(([\t ]*\r\n)?[\t ]+)?
(normalized) =~ [-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+"
domain = dot-atom / domain-literal
=~ (([\t ]*\r\n)?[\t ]+)?[-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?\[((([\t ]*\r\n)?[\t ]+)?[!-Z^-~])*(([\t ]*\r\n)?[\t ]+)?](([\t ]*\r\n)?[\t ]+)?
(normalized) =~ [-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|\[[\t -Z^-~]*]
addr-spec = local-part "@" domain
=~ ((([\t ]*\r\n)?[\t ]+)?[-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?"(((([\t ]*\r\n)?[\t ]+)?([]!#-[^-~]|(\\[\t -~])))+(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?)"(([\t ]*\r\n)?[\t ]+)?)@((([\t ]*\r\n)?[\t ]+)?[-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*(([\t ]*\r\n)?[\t ]+)?|(([\t ]*\r\n)?[\t ]+)?\[((([\t ]*\r\n)?[\t ]+)?[!-Z^-~])*(([\t ]*\r\n)?[\t ]+)?](([\t ]*\r\n)?[\t ]+)?)
(normalized) =~ ([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|\[[\t -Z^-~]*])
Note that some sources (notably W3C) claim that RFC 5322 is too strict on the local part (i.e. the part before the @-sign). This is because "..", "a..b" and "a." are not valid dot-atoms, while they may be used as mailbox names. The RFC, however, does allow for local parts like these, except that they have to be quoted. So instead of [email protected] you should write "a..b"@example.net, which is semantically equivalent.
Further restrictions
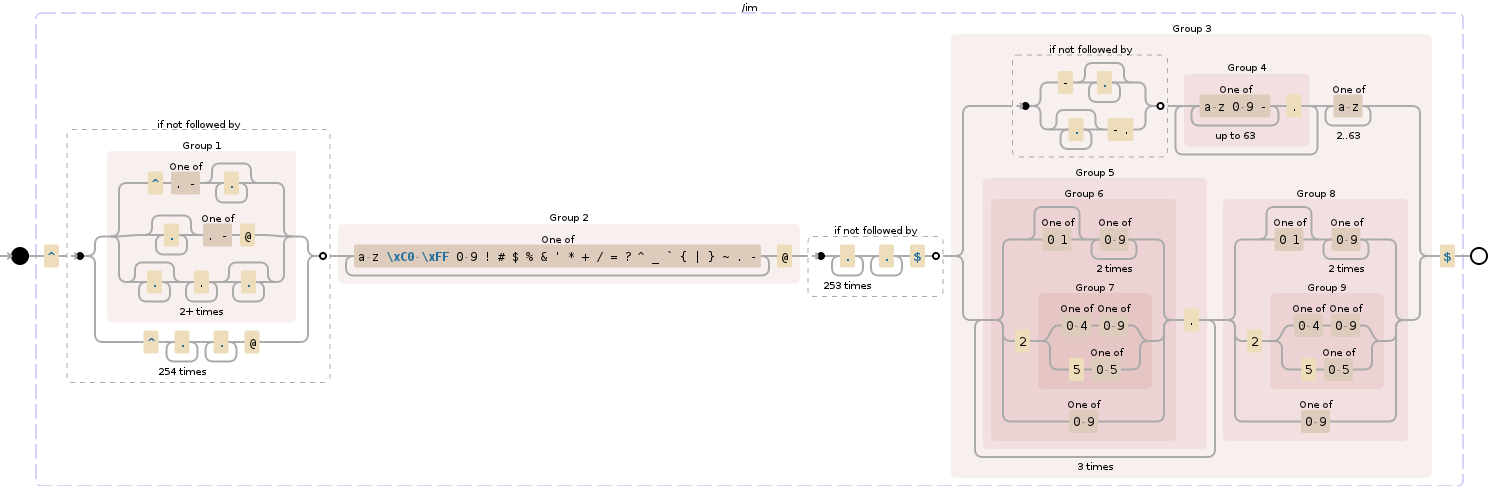
SMTP (as defined in RFC 5321) further restricts the set of valid email addresses (or actually: mailbox names). It seems reasonable to impose this stricter grammar, so that the matched email address can actually be used to send an email.
RFC 5321 basically leaves alone the "local" part (i.e. the part before the @-sign), but is stricter on the domain part (i.e. the part after the @-sign). It allows only host names in place of dot-atoms and address literals in place of domain literals.
The grammar presented in RFC 5321 is too lenient when it comes to both host names and IP addresses. I took the liberty of "correcting" the rules in question, using this draft and RFC 1034 as guidelines. Here's the resulting regex.
([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@([0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?(\.[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?)*|\[((25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}|IPv6:((((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){6}|::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){5}|[0-9A-Fa-f]{0,4}::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){4}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):)?(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){3}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,2}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){2}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,3}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,4}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,5}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,6}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)|(?!IPv6:)[0-9A-Za-z-]*[0-9A-Za-z]:[!-Z^-~]+)])
Note that depending on the use case you may not want to allow for a "General-address-literal" in your regex. Also note that I used a negative lookahead (?!IPv6:) in the final regex to prevent the "General-address-literal" part to match malformed IPv6 addresses. Some regex processors don't support negative lookahead. Remove the substring |(?!IPv6:)[0-9A-Za-z-]*[0-9A-Za-z]:[!-Z^-~]+ from the regex if you want to take the whole "General-address-literal" part out.
Here's the derivation:
Let-dig = ALPHA / DIGIT
=~ [0-9A-Za-z]
Ldh-str = *( ALPHA / DIGIT / "-" ) Let-dig
=~ [0-9A-Za-z-]*[0-9A-Za-z]
(regex is updated to make sure sub-domains are max. 63 characters long - RFC 1034 section 3.5)
sub-domain = Let-dig [Ldh-str]
=~ [0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?
Domain = sub-domain *("." sub-domain)
=~ [0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?(\.[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?)*
Snum = 1*3DIGIT
=~ [0-9]{1,3}
(suggested replacement for "Snum")
ip4-octet = DIGIT / %x31-39 DIGIT / "1" 2DIGIT / "2" %x30-34 DIGIT / "25" %x30-35
=~ 25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9]
IPv4-address-literal = Snum 3("." Snum)
=~ [0-9]{1,3}(\.[0-9]{1,3}){3}
(suggested replacement for "IPv4-address-literal")
ip4-address = ip4-octet 3("." ip4-octet)
=~ (25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}
(suggested replacement for "IPv6-hex")
ip6-h16 = "0" / ( (%x49-57 / %x65-70 /%x97-102) 0*3(%x48-57 / %x65-70 /%x97-102) )
=~ 0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}
(not from RFC)
ls32 = ip6-h16 ":" ip6-h16 / ip4-address
=~ (0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}
(suggested replacement of "IPv6-addr")
ip6-address = 6(ip6-h16 ":") ls32
/ "::" 5(ip6-h16 ":") ls32
/ [ ip6-h16 ] "::" 4(ip6-h16 ":") ls32
/ [ *1(ip6-h16 ":") ip6-h16 ] "::" 3(ip6-h16 ":") ls32
/ [ *2(ip6-h16 ":") ip6-h16 ] "::" 2(ip6-h16 ":") ls32
/ [ *3(ip6-h16 ":") ip6-h16 ] "::" ip6-h16 ":" ls32
/ [ *4(ip6-h16 ":") ip6-h16 ] "::" ls32
/ [ *5(ip6-h16 ":") ip6-h16 ] "::" ip6-h16
/ [ *6(ip6-h16 ":") ip6-h16 ] "::"
=~ (((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){6}|::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){5}|[0-9A-Fa-f]{0,4}::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){4}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):)?(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){3}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,2}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){2}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,3}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,4}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,5}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,6}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::
IPv6-address-literal = "IPv6:" ip6-address
=~ IPv6:((((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){6}|::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){5}|[0-9A-Fa-f]{0,4}::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){4}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):)?(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){3}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,2}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){2}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,3}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,4}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,5}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,6}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)
Standardized-tag = Ldh-str
=~ [0-9A-Za-z-]*[0-9A-Za-z]
dcontent = %d33-90 / %d94-126
=~ [!-Z^-~]
General-address-literal = Standardized-tag ":" 1*dcontent
=~ [0-9A-Za-z-]*[0-9A-Za-z]:[!-Z^-~]+
address-literal = "[" ( IPv4-address-literal / IPv6-address-literal / General-address-literal ) "]"
=~ \[((25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}|IPv6:((((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){6}|::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){5}|[0-9A-Fa-f]{0,4}::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){4}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):)?(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){3}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,2}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){2}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,3}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,4}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,5}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,6}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)|(?!IPv6:)[0-9A-Za-z-]*[0-9A-Za-z]:[!-Z^-~]+)]
Mailbox = Local-part "@" ( Domain / address-literal )
=~ ([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@([0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?(\.[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?)*|\[((25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3}|IPv6:((((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){6}|::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){5}|[0-9A-Fa-f]{0,4}::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){4}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):)?(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){3}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,2}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){2}|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,3}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,4}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])(\.(25[0-5]|2[0-4][0-9]|1[0-9]{2}|[1-9]?[0-9])){3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,5}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3})|(((0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}):){0,6}(0|[1-9A-Fa-f][0-9A-Fa-f]{0,3}))?::)|(?!IPv6:)[0-9A-Za-z-]*[0-9A-Za-z]:[!-Z^-~]+)])
User input validation
A common use case is user input validation, for example on an html form. In that case it's usually reasonable to preclude address-literals and to require at least two labels in the hostname. Taking the improved RFC 5321 regex from the previous section as a basis, the resulting expression would be:
([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?(\.[0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?)+
I do not recommend restricting the local part further, e.g. by precluding quoted strings, since we don't know what kind of mailbox names some hosts allow (like "a..b"@example.net or even "a b"@example.net).
I also do not recommend explicitly validating against a list of literal top-level domains or even imposing length-constraints (remember how ".museum" invalidated [a-z]{2,4}), but if you must:
([-!#-'*+/-9=?A-Z^-~]+(\.[-!#-'*+/-9=?A-Z^-~]+)*|"([]!#-[^-~ \t]|(\\[\t -~]))+")@([0-9A-Za-z]([0-9A-Za-z-]{0,61}[0-9A-Za-z])?\.)*(net|org|com|info|etc...)
Make sure to keep your regex up-to-date if you decide to go down the path of explicit top-level domain validation.
Further considerations
When only accepting host names in the domain part (after the @-sign), the regexes above accept only labels with at most 63 characters, as they should. However, they don't enforce the fact that the entire host name must be at most 253 characters long (including the dots). Although this constraint is strictly speaking still regular, it's not feasible to make a regex that incorporates this rule.
Another consideration, especially when using the regexes for input validation, is feedback to the user. If a user enters an incorrect address, it would be nice to give a little more feedback than a simple "syntactically incorrect address". With "vanilla" regexes this is not possible.
These two considerations could be addressed by parsing the address. The extra length constraint on host names could in some cases also be addressed by using an extra regex that checks it, and matching the address against both expressions.
None of the regexes in this answer are optimized for performance. If performance is an issue, you should see if (and how) the regex of your choice can be optimized.

{kind=link}
{kind=link}
^([\w-\.]+)@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.)|(([\w-]+\.)+))([a-zA-Z]{2,4}|[0-9]{1,3})(\]?)$– Improvised