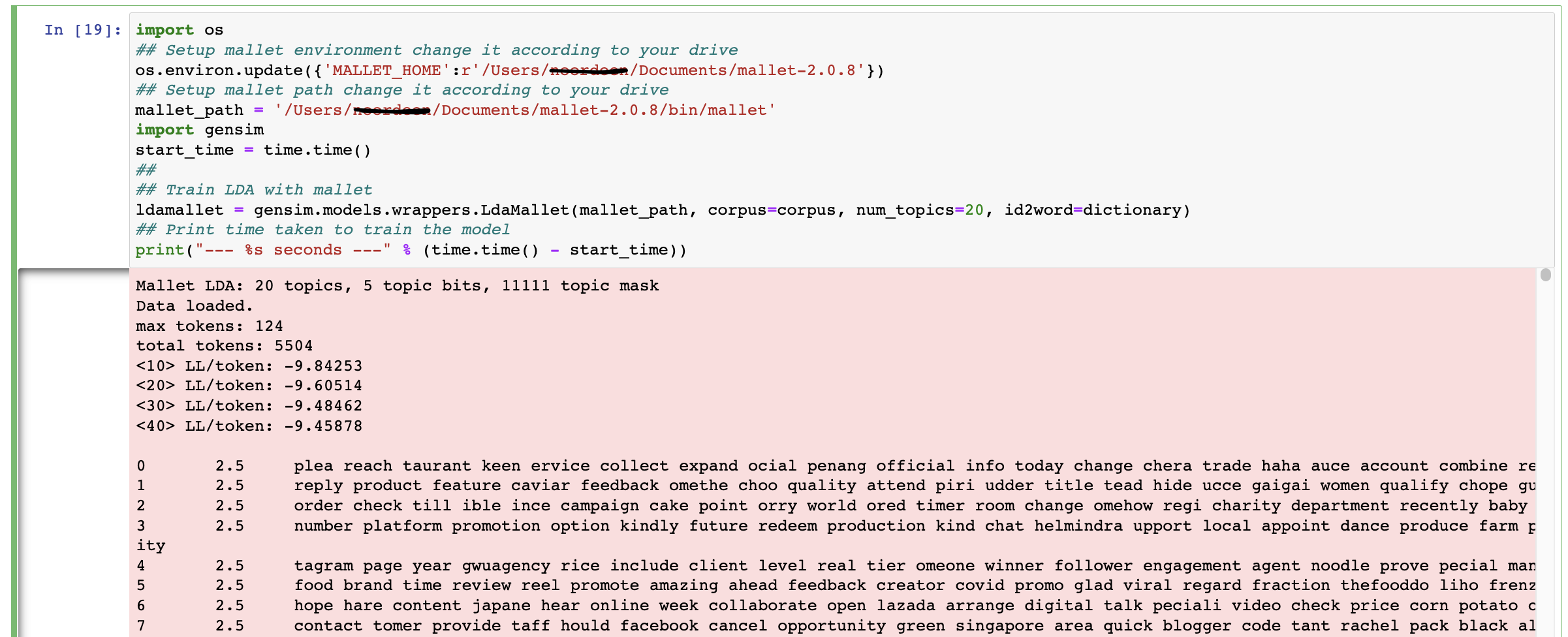
When I try to run:
def remove_stopwords(texts):
return [[word for word in simple_preprocess(str(doc)) if word not in stop_words] for doc in texts]
def make_bigrams(texts):
return [bigram_mod1[doc] for doc in texts]
# Remove Stop Words
data_words_nostops1 = remove_stopwords(data_words1)
# Form Bigrams
data_words_bigrams1 = make_bigrams(data_words_nostops1)
# Create Dictionary
id2word1 = corpora.Dictionary(data_words_bigrams1)
# Create Corpus
texts1 = data_words_bigrams1
# Term Document Frequency
corpus1 = [id2word1.doc2bow(text) for text in texts1]
mallet_path = 'T:Python/Mallet/mallet-2.0.8/bin/mallet'
ldamallet = gensim.models.wrappers.LdaMallet(mallet_path, corpus=corpus1, num_topics=15, id2word=id2word1)
I get the following error:
CalledProcessError: Command 'T:/Python/Mallet/mallet-2.0.8/bin/mallet import-file --preserve-case --keep-sequence --remove-stopwords --token-regex "\S+" --input C:\Users\E26E5~1.RIJ\AppData\Local\Temp\3\a66fc0_corpus.txt --output C:\Users\E26E5~1.RIJ\AppData\Local\Temp\3\a66fc0_corpus.mallet' returned non-zero exit status 1.
What can I do in my code specifically to make it work?
Furthermore, the question on this error has been asked a few times before. However, each answer seems so specific to a particular case, that I don't see what I can change on my code now so that it will work. Can someone elaborate on the meaning of this problem?