I am developing my ANN from scratch which is supposed to classify MNIST database of handwritten digits (0-9). My feed-forward fully connected ANN has to be composed of:
- One input layer, with
28x28 = 784nodes (that is, features of each image) - One hidden layer, with any number of neurons (shallow network)
- One output layer, with
10nodes (one for each digit)
and has to compute gradient w.r.t. weights and bias thanks to backpropagation algorithm and, finally, it should learn exploiting gradient descent with momentum algorithm.
The loss function is: cross_entropy on "softmaxed" network's outputs, since the task is about classification.
Each hidden neuron is activated by the same activation function, I've chosen the sigmoid; meanwhile the output's neurons are activated by the identity function.
The dataset has been divided into:
60.000training pairs(image, label)- for the training5000validation pairs(image, label)- for evaluation and select the network which minimize the validation loss5000testing pairs(image, label)- for testing the model picked using new metrics such as accuracy
The data has been shuffled invoking sklearn.utils.shuffle method.
These are my net's performance about training loss, validation loss and validation accuracy:
E(0) on TrS is: 798288.7537714319 on VS is: 54096.50409967187 Accuracy: 12.1 %
E(1) on TrS is: 798261.8584179751 on VS is: 54097.23663558976 Accuracy: 12.1 %
...
E(8) on TrS is: 798252.1191081362 on VS is: 54095.5016235736 Accuracy: 12.1 %
...
E(17) on TrS is: 798165.2674011206 on VS is: 54087.2823473459 Accuracy: 12.8 %
E(18) on TrS is: 798155.0888987815 on VS is: 54086.454077456074 Accuracy: 13.22 %
...
E(32) on TrS is: 798042.8283810444 on VS is: 54076.35518400717 Accuracy: 19.0 %
E(33) on TrS is: 798033.2512910366 on VS is: 54075.482037626025 Accuracy: 19.36 %
E(34) on TrS is: 798023.431899881 on VS is: 54074.591145985265 Accuracy: 19.64 %
E(35) on TrS is: 798013.4023181734 on VS is: 54073.685418577166 Accuracy: 19.759999999999998 %
E(36) on TrS is: 798003.1960815473 on VS is: 54072.76783050559 Accuracy: 20.080000000000002 %
...
E(47) on TrS is: 797888.8213232228 on VS is: 54062.70342708315 Accuracy: 21.22 %
E(48) on TrS is: 797879.005388998 on VS is: 54061.854566864626 Accuracy: 21.240000000000002 %
E(49) on TrS is: 797869.3890292909 on VS is: 54061.02482142968 Accuracy: 21.26 %
Validation loss is minimum at epoch: 49
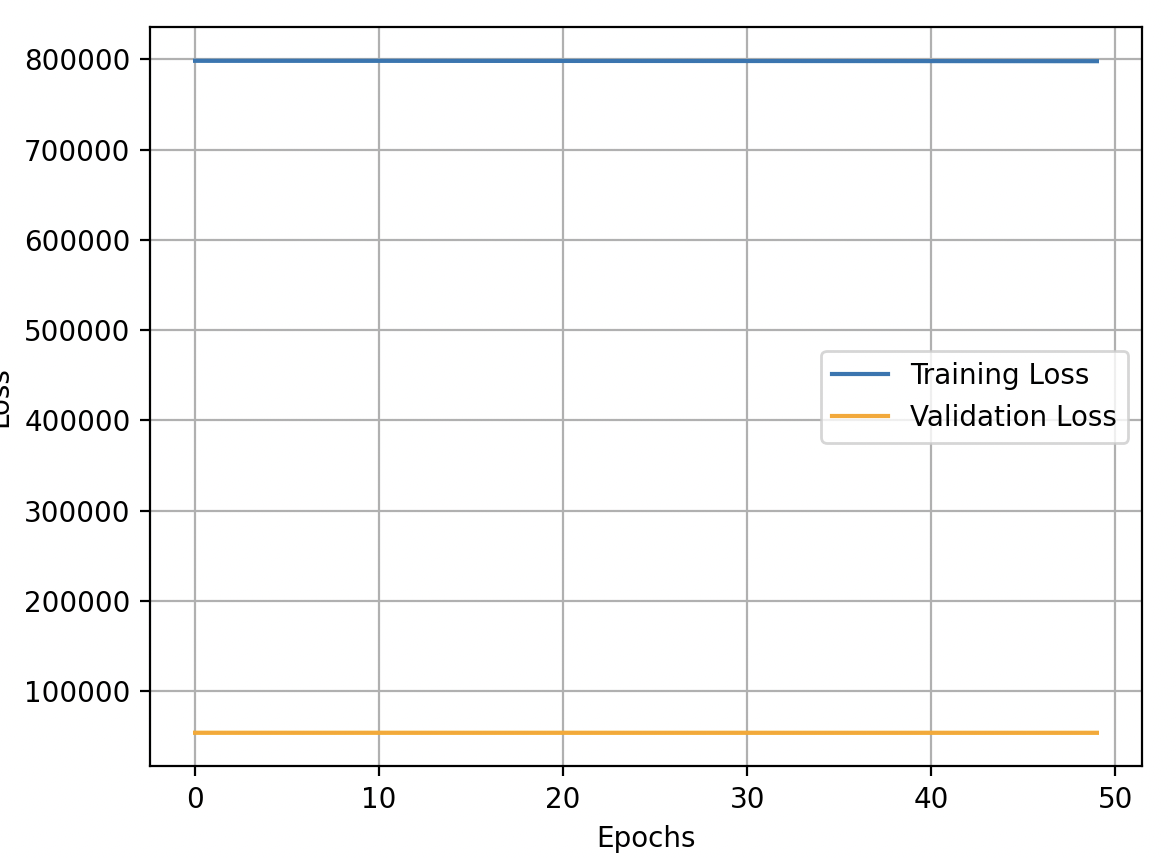

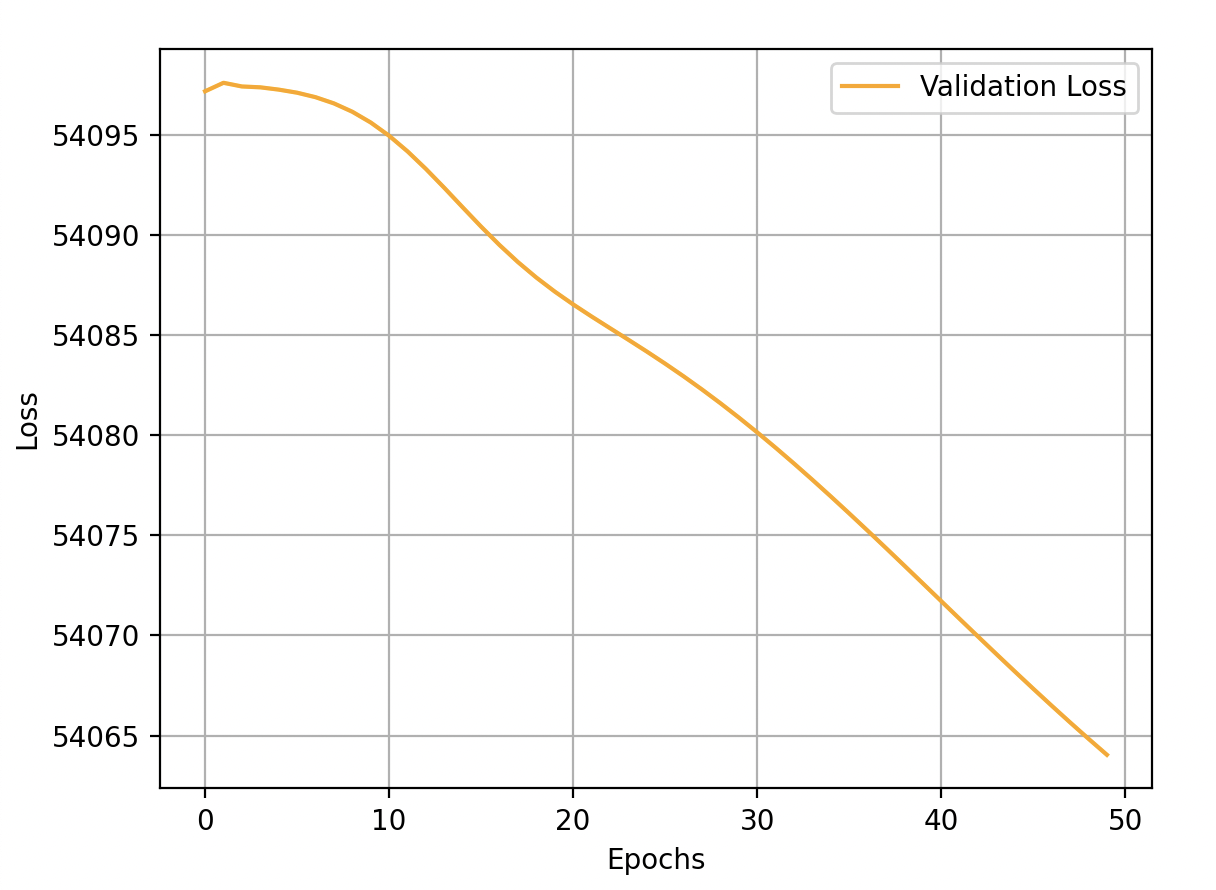
As you can see the losses are very high and the learning is very slow.
This is my code:
import numpy as np
from scipy.special import expit
from matplotlib import pyplot as plt
from mnist.loader import MNIST
from sklearn.utils import shuffle
def relu(a, derivative=False):
f_a = np.maximum(0, a)
if derivative:
return (a > 0) * 1
return f_a
def softmax(y):
e_y = np.exp(y - np.max(y, axis=0))
return e_y / np.sum(e_y, axis=0)
def cross_entropy(y, t, derivative=False, post_process=True):
epsilon = 10 ** -308
if post_process:
if derivative:
return y - t
sm = softmax(y)
sm = np.clip(sm, epsilon, 1 - epsilon) # avoids log(0)
return -np.sum(np.sum(np.multiply(t, np.log(sm)), axis=0))
def sigmoid(a, derivative=False):
f_a = expit(a)
if derivative:
return np.multiply(f_a, (1 - f_a))
return f_a
def identity(a, derivative=False):
f_a = a
if derivative:
return np.ones(np.shape(a))
return f_a
def accuracy_score(targets, predictions):
correct_predictions = 0
for item in range(np.shape(predictions)[1]):
argmax_idx = np.argmax(predictions[:, item])
if targets[argmax_idx, item] == 1:
correct_predictions += 1
return correct_predictions / np.shape(predictions)[1]
def one_hot(targets):
return np.asmatrix(np.eye(10)[targets]).T
def plot(epochs, loss_train, loss_val):
plt.plot(epochs, loss_train)
plt.plot(epochs, loss_val, color="orange")
plt.legend(["Training Loss", "Validation Loss"])
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.grid(True)
plt.show()
class NeuralNetwork:
def __init__(self):
self.layers = []
def add_layer(self, layer):
self.layers.append(layer)
def build(self):
for i, layer in enumerate(self.layers):
if i == 0:
layer.type = "input"
else:
layer.type = "output" if i == len(self.layers) - 1 else "hidden"
layer.configure(self.layers[i - 1].neurons)
def fit(self, X_train, targets_train, X_val, targets_val, max_epochs=50):
e_loss_train = []
e_loss_val = []
# Getting the minimum loss on validation set
predictions_val = self.predict(X_val)
min_loss_val = cross_entropy(predictions_val, targets_val)
best_net = self # net which minimize validation loss
best_epoch = 0 # epoch where the validation loss is minimum
# batch mode
for epoch in range(max_epochs):
predictions_train = self.predict(X_train)
self.back_prop(targets_train, cross_entropy)
self.learning_rule(l_rate=0.00001, momentum=0.9)
loss_train = cross_entropy(predictions_train, targets_train)
e_loss_train.append(loss_train)
# Validation
predictions_val = self.predict(X_val)
loss_val = cross_entropy(predictions_val, targets_val)
e_loss_val.append(loss_val)
print("E(%d) on TrS is:" % epoch, loss_train, " on VS is:", loss_val, " Accuracy:",
accuracy_score(targets_val, predictions_val) * 100, "%")
if loss_val < min_loss_val:
min_loss_val = loss_val
best_epoch = epoch
best_net = self
plot(np.arange(max_epochs), e_loss_train, e_loss_val)
return best_net
# Matrix of predictions where the i-th column corresponds to the i-th item
def predict(self, dataset):
z = dataset.T
for layer in self.layers:
z = layer.forward_prop_step(z)
return z
def back_prop(self, target, loss):
for i, layer in enumerate(self.layers[:0:-1]):
next_layer = self.layers[-i]
prev_layer = self.layers[-i - 2]
layer.back_prop_step(next_layer, prev_layer, target, loss)
def learning_rule(self, l_rate, momentum):
# Momentum GD
for layer in [layer for layer in self.layers if layer.type != "input"]:
layer.update_weights(l_rate, momentum)
layer.update_bias(l_rate, momentum)
class Layer:
def __init__(self, neurons, type=None, activation=None):
self.dE_dW = None # derivatives dE/dW where W is the weights matrix
self.dE_db = None # derivatives dE/db where b is the bias
self.dact_a = None # derivative of the activation function
self.out = None # layer output
self.weights = None # input weights
self.bias = None # layer bias
self.w_sum = None # weighted_sum
self.neurons = neurons # number of neurons
self.type = type # input, hidden or output
self.activation = activation # activation function
self.deltas = None # for back-prop
def configure(self, prev_layer_neurons):
self.set_activation()
self.weights = np.asmatrix(np.random.normal(-0.1, 0.02, (self.neurons, prev_layer_neurons)))
self.bias = np.asmatrix(np.random.normal(-0.1, 0.02, self.neurons)).T
def set_activation(self):
if self.activation is None:
if self.type == "hidden":
self.activation = sigmoid
elif self.type == "output":
self.activation = identity # will be softmax in cross entropy calculation
def forward_prop_step(self, z):
if self.type == "input":
self.out = z
else:
self.w_sum = np.dot(self.weights, z) + self.bias
self.out = self.activation(self.w_sum)
return self.out
def back_prop_step(self, next_layer, prev_layer, target, local_loss):
if self.type == "output":
self.dact_a = self.activation(self.w_sum, derivative=True)
self.deltas = np.multiply(self.dact_a,
local_loss(self.out, target, derivative=True))
else:
self.dact_a = self.activation(self.w_sum, derivative=True) # (m,batch_size)
self.deltas = np.multiply(self.dact_a, np.dot(next_layer.weights.T, next_layer.deltas))
self.dE_dW = self.deltas * prev_layer.out.T
self.dE_db = np.sum(self.deltas, axis=1)
def update_weights(self, l_rate, momentum):
# Momentum GD
self.weights = self.weights - l_rate * self.dE_dW
self.weights = -l_rate * self.dE_dW + momentum * self.weights
def update_bias(self, l_rate, momentum):
# Momentum GD
self.bias = self.bias - l_rate * self.dE_db
self.bias = -l_rate * self.dE_db + momentum * self.bias
if __name__ == '__main__':
mndata = MNIST(path="data", return_type="numpy")
X_train, targets_train = mndata.load_training() # 60.000 images, 28*28 features
X_val, targets_val = mndata.load_testing() # 10.000 images, 28*28 features
X_train = X_train / 255 # normalization within [0;1]
X_val = X_val / 255 # normalization within [0;1]
X_train, targets_train = shuffle(X_train, targets_train.T)
X_val, targets_val = shuffle(X_val, targets_val.T)
# Getting the test set splitting the validation set in two equal parts
# Validation set size decreases from 10.000 to 5000 (of course)
X_val, X_test = np.split(X_val, 2) # 5000 images, 28*28 features
targets_val, targets_test = np.split(targets_val, 2)
X_test, targets_test = shuffle(X_test, targets_test.T)
targets_train = one_hot(targets_train)
targets_val = one_hot(targets_val)
targets_test = one_hot(targets_test)
net = NeuralNetwork()
d = np.shape(X_train)[1] # number of features, 28x28
c = np.shape(targets_train)[0] # number of classes, 10
# Shallow network with 1 hidden neuron
# That is 784, 1, 10
for m in (d, 1, c):
layer = Layer(m)
net.add_layer(layer)
net.build()
best_net = net.fit(X_train, targets_train, X_val, targets_val, max_epochs=50)
What I have done:
- Set
500instead of1hidden neuron - Add many hidden layers
- Decrease/increase learning rate (
l_rate) value - Decrease/increase
momentum(and set it to0) - Replace
sigmoidwithrelu
but there still is the problem.
These are the formulas I used for calculations (but you can check them out from the source code, of course):
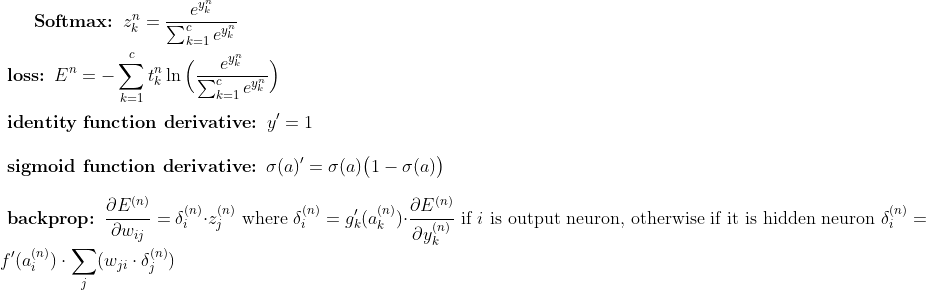
Note: f and g in formulas stand for hidden layers activation function and output layer activation function.
EDIT:
I re-implemented the cross_entropy function considering the average loss, replacing
-np.sum(..., axis=0))
with
-np.mean(..., axis=0))
and losses are now comparable. But the problem about low accuracy persists as you can see:
E(0) on TrS is: 2.3033276613180695 on VS is: 2.3021572339654925 Accuracy: 10.96 %
E(1) on TrS is: 2.3021765614184284 on VS is: 2.302430432090161 Accuracy: 10.96 %
E(2) on TrS is: 2.302371681532198 on VS is: 2.302355601340701 Accuracy: 10.96 %
E(3) on TrS is: 2.3023151858432804 on VS is: 2.302364165840666 Accuracy: 10.96 %
E(4) on TrS is: 2.3023186844504564 on VS is: 2.3023457770291267 Accuracy: 10.96 %
...
E(34) on TrS is: 2.2985702635977137 on VS is: 2.2984384616550875 Accuracy: 18.52 %
E(35) on TrS is: 2.2984081462987076 on VS is: 2.2982663840016873 Accuracy: 18.8 %
E(36) on TrS is: 2.2982422912146845 on VS is: 2.298091144330386 Accuracy: 19.06 %
E(37) on TrS is: 2.2980732333918854 on VS is: 2.2979132918897367 Accuracy: 19.36 %
E(38) on TrS is: 2.297901523346666 on VS is: 2.2977333860658424 Accuracy: 19.68 %
E(39) on TrS is: 2.2977277198903883 on VS is: 2.297551989820155 Accuracy: 19.78 %
...
E(141) on TrS is: 2.291884965880953 on VS is: 2.2917100547472575 Accuracy: 21.08 %
E(142) on TrS is: 2.29188099824872 on VS is: 2.291706280301498 Accuracy: 21.08 %
E(143) on TrS is: 2.2918771014203316 on VS is: 2.291702575667588 Accuracy: 21.08 %
E(144) on TrS is: 2.291873271054674 on VS is: 2.2916989365939067 Accuracy: 21.08 %
E(145) on TrS is: 2.2918695030455183 on VS is: 2.291695359057886 Accuracy: 21.08 %
E(146) on TrS is: 2.291865793508291 on VS is: 2.291691839253129 Accuracy: 21.08 %
E(147) on TrS is: 2.2918621387676166 on VS is: 2.2916883735772675 Accuracy: 21.08 %
E(148) on TrS is: 2.2918585353455745 on VS is: 2.291684958620525 Accuracy: 21.08 %
E(149) on TrS is: 2.2918549799506307 on VS is: 2.291681591154936 Accuracy: 21.08 %
E(150) on TrS is: 2.2918514694672263 on VS is: 2.291678268124199 Accuracy: 21.08 %
...
E(199) on TrS is: 2.2916983481535644 on VS is: 2.2915343016441727 Accuracy: 21.060000000000002 %

I incrased MAX_EPOCHS value from 50 to 200 for better visualizing results.
self.deltasis a matrix again, that's not obvious. likewise its not clear ifdeltas * prev_layer.out.Tis an element wise multiplication or a dot product. For a pure ndarray setup it would be obvious a multipication, here it is a dot product. That what makes parts of the code harder to understand. – Dahabeah