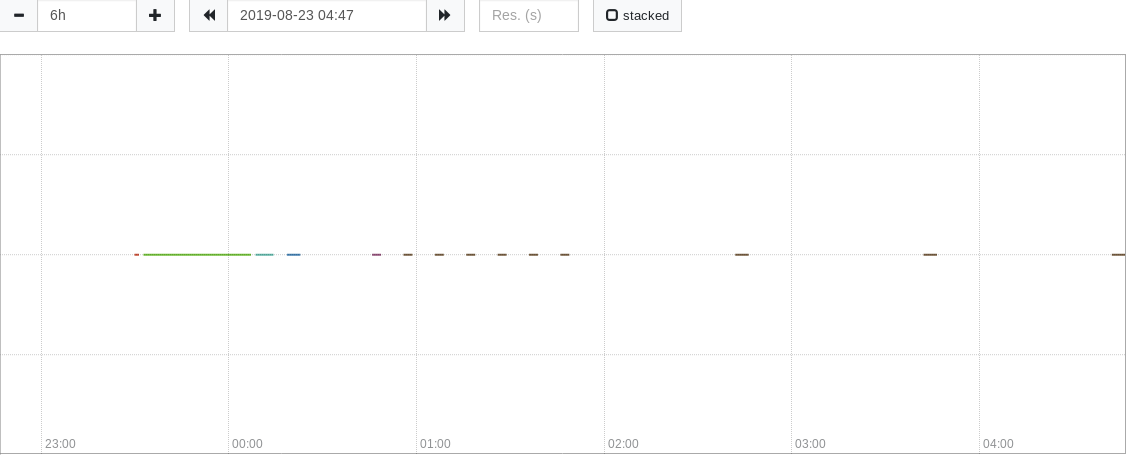
I would like Prometheus to scrape metrics every hour and display these hourly scrape events in a table in a Grafana dashboard. I have the global scrape interval set to 1h in the prometheus.yml file. From the prometheus visualizer, it seems like Prometheus scrapes around the 43 minute mark of every hour. However, it also seems like this data is only valid for about 3 minutes: Prometheus graph
{kind=link}
My situation, then, is this: In a Grafana table, I set the min step of a query on this metric to 1h, but this causes the table to say that there are no data points. However, if I set the min step to 5 minutes, it displays the hourly scrape events with a timestamp on the 45 minute mark. My guess as to why this happens is that Prometheus starts on the dot of some hour and steps either forward or backward by the min step.
This does achieve what I would like to do, but it also has potential for incorrect behavior if Prometheus ever does something like can been seen at the beginning of the earlier graph. I also know that I can add a time shift, but it seems like it is always relative to the current time rather than an absolute time.
Is it possible to increase the amount of time that the scrape data is valid in Prometheus without having to scrape again every 3 minutes? Or maybe tell Prometheus to scrape at the 00 minute mark of every hour? Or if not, then can I add a relative time shift to the table so that it goes from the 45 minute mark instead of the 00 minute mark?
On a side note, in the above Prometheus graph, the irregular data was scraped after Prometheus was started. I had started Prometheus around 18:30 on the 22nd, but Prometheus didn't scrape until 23:30, and then it scraped at different intervals until it stabilized around 2:43 on the 23rd. Does anybody know why?