I was not happy with the currently accepted answer, so I hope this helps some future readers:
If the current state is the root node, where did these children come from in the first place?
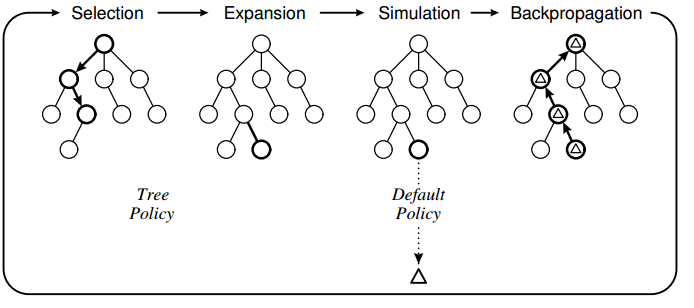
At first there are no children, so the selection phase selects the root node only. The rule is that the selection stops at the node that is not fully expanded, and since the root did not yet expand any child nodes, the root is selected.
Wouldn't you have a tree with just a single root node to begin with? With just a single root node, do you get into Expansion and Simulation phase right away?
Yes.
If MCTS selects the highest scoring child node in Selection phase, you never explore other children or possibly even a brand new child whilst going down the levels of the tree?
Not never, just not in this iteration of the four phases. Scores change after each iteration, so what is considered "best" in one iteration, may not be "best" in the next iteration. However, it is excluded that there would be a non-visited child left aside whilst going down. The selection phase stops when it arrives at a node that has not been fully expanded, i.e. whose children have not all been visited yet. For example, if the root has five children, the first five iterations of the MCTS loop will all select the root node, and then expand into one of those five child nodes -- a different one (randomly) in each iteration (assuming that each iteration makes one expansion), so that after those five iterations the root node is fully expanded.
How does the Expansion phase happen for a node? In the diagram above, why did it not choose leaf node but decided to add a sibling to the leaf node?
The leftmost diagram does not show it, but the selected node in the selection phase knows that there are more children than the one that was already visited, and so the selection phase must stop at that node. Only when in the selection phase we encounter a node that is fully expanded (i.e. where each of the possible children for that node had been visited during an expansion phase), the selection phase continues the traversal downward. Apparently, in the example this was the case for the first two nodes on the selection-path, but not for the third.
During the Simulation phase, stochastic policy is used to select legal moves for both players until the game terminates. Is this stochastic policy a hard-coded behavior and you are basically rolling a dice in the simulation to choose one of the possible moves taking turns between each player until the end?
That's a choice to make. Rolling a dice would be a standard (and fast) method, but you could decide to use some game knowledge, so to exclude the most stupid choices, and give higher probability to potentially good moves. But gathering/calculating such information costs extra time, so it is a trade-off to make. If too much time goes into evaluating moves, the number of nodes that can be visited decreases too much, crippling the power of MCTS.
The way I understand this is you start at a single root node and by repeating the above phases you construct the tree to a certain depth.
The search tree will in general not have its leaves all at the same level. The goal is not to reach a predefined depth. As the selection phase will typically not make random choices, but use an Upper Confidence Bound applied to trees, this could make the tree actually quite unbalanced, as some nodes get selected significantly more often than others.
Then you choose the child with the best score at the second level as your next move.
This is the selection process at any level, but only for as long the node has been fully expanded. Otherwise the not-fully expanded node becomes the selected node.
The size of the tree you are willing to construct is basically your hard AI responsiveness requirement right? Since while the tree is being constructed the game will stall and compute this tree.
That depends how you implement it. The iterations could run in the background, and could be interrupted by some event of your choice: like by reaching a maximum size of the tree, or the time that has elapsed, or a user interaction, ...etc. It could even continue to run while the (human?) opponent thinks about their move. The nice thing is that after each MCTS iteration there is the concept of "best move so far".