Allow me to expand on Thomas's answer.
If you look at an implementation of Dijkstra, such as this example: http://graphonline.ru/en/?graph=NnnNwZKjpjeyFnwx you'll see a graph like this
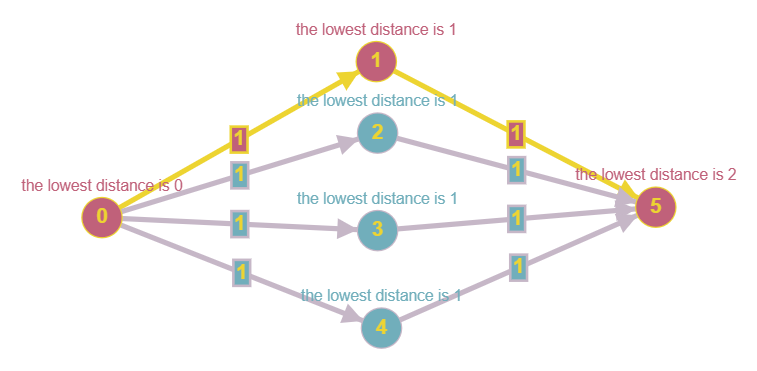
![An example graph]()
In the example graph, 0→1→5, 0→2→5, 0→3→5 and 0→4→5 are all the same length. To find "the shortest path" is not necessarily unique, as is evidenced by this diagram.
Using the wording on Wikipedia, at some point the algorithm instructs us to:
select the unvisited node that is marked with the smallest tentative distance.
The problem here is the word the, suggesting that it is somehow unique. It may not be. For an implementation to actually pick one node from many equal candidates requires further specification of the algorithm regarding how to select it. But any such selected candidate having the required property will determine a path of the shortest length. So the algorithm doesn't commit. The modern approach to wording this algorithm would be to say:
select any unvisited node that is marked with the smallest tentative distance.
From a mathematical graph theory algorithm standpoint, that algorithm would technically proceed with all such candidates simultaneously in a sort of multiverse. All answers it may arrive at are equally valid. And when proving the algorithm works, we would prove it for all such candidates in all the multiverses and show that all choices arrive at a path of the same distance, and that the distance is the shortest distance possible.
Then, if you want to use the algorithm to just compute one such answer because you want to either A) find one such path, or B) determine the distance of such a path, then it is left up to you to select one specific branch of the multiverse to explore. All such selections made according to the algorithm as defined will yield a path whose length is the shortest length possible. You can define any additional non-conflicting criteria you wish to make such a selection.
The reason the implementation I linked is deterministic and always gives the same answer (for the same start and end nodes, obviously) is because the nodes themselves are ordered in the computer. This additional information about the ordering of the nodes is not considered for graph theory. The nodes are often labelled, but not necessarily ordered. In the implementation, the computer relies on the fact that the nodes appear in an ordered array of nodes in memory and the implementation uses this ordering to resolve ties. Possibly by selecting the node with the lowest index in the array, a.k.a. the "first" candidate.
If an implementation resolved ties by randomly (not pesudo-randomly!) selecting a winner from equal candidates, then it wouldn't be deterministic either.
Dijkstra's algorithm as described on Wikipedia just defines an algorithm to find the shortest paths (note the plural paths) between nodes. Any such path that it finds (if it exists) it is guaranteed to be of the shortest distance possible. You're still left with the task of deciding between equivalent candidates though at step 6 in the algorithm.