I would like to perform the following task. Given a 2 columns (good and bad) I would like to replace any rows for the two columns with a running total. Here is an example of the current dataframe along with the desired data frame.
EDIT: I should have added what my intentions are. I am trying to create equally binned (in this case 20) variable using a continuous variable as the input. I know the pandas cut and qcut functions are available, however the returned results will have zeros for the good/bad rate (needed to compute the weight of evidence and information value). Zeros in either the numerator or denominator will not allow the mathematical calculations to work.
d={'AAA':range(0,20),
'good':[3,3,13,20,28,32,59,72,64,52,38,24,17,19,12,5,7,6,2,0],
'bad':[0,0,1,1,1,0,6,8,10,6,6,10,5,8,2,2,1,3,1,1]}
df=pd.DataFrame(data=d)
print(df)
Here is an explanation of what I need to do to the above dataframe.
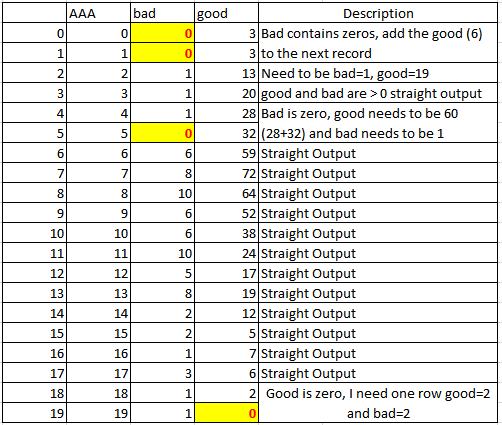
Roughly speaking, anytime I encounter a zero for either column, I need to use a running total for the column which is not zero to the next row which has a non-zero value for the column that contained zeros.
Here is the desired output:
dd={'AAA':range(0,16),
'good':[19,20,60,59,72,64,52,38,24,17,19,12,5,7,6,2],
'bad':[1,1,1,6,8,10,6,6,10,5,8,2,2,1,3,2]}
desired_df=pd.DataFrame(data=dd)
print(desired_df)