I am trying to minimize a function defined as follows:
utility(decision) = decision * (risk - cost)
where variables take the following form:
decision = binary array
risk = array of floats
cost = constant
I know the solution will take the form of:
decision = 1 if (risk >= threshold)
decision = 0 otherwise
Therefore, in order to minimize this function I can assume that I transform the function utility to depend only on this threshold. My direct translation to scipy is the following:
def utility(threshold,risk,cost):
selection_list = [float(risk[i]) >= threshold for i in range(len(risk))]
v = np.array(risk.astype(float)) - cost
total_utility = np.dot(v, selection_list)
return -1.0*total_utility
result = minimize(fun=utility, x0=0.2, args=(r,c),bounds=[(0,1)], options={"disp":True} )
This gives me the following result:
fun: array([-17750.44298655]) hess_inv: <1x1 LbfgsInvHessProduct with
dtype=float64>
jac: array([0.])
message: b'CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL'
nfev: 2
nit: 0 status: 0 success: True
x: array([0.2])
However, I know the result is wrong because in this case it must be equal to cost. On top of that, no matter what x0 I use, it always returns it as the result. Looking at the results I observe that jacobian=0 and does not compute 1 iteration correctly.
Looking more thoroughly into the function. I plot it and observe that it is not convex on the limits of the bounds but we can clearly see the minimum at 0.1. However, no matter how much I adjust the bounds to be in the convex part only, the result is still the same.
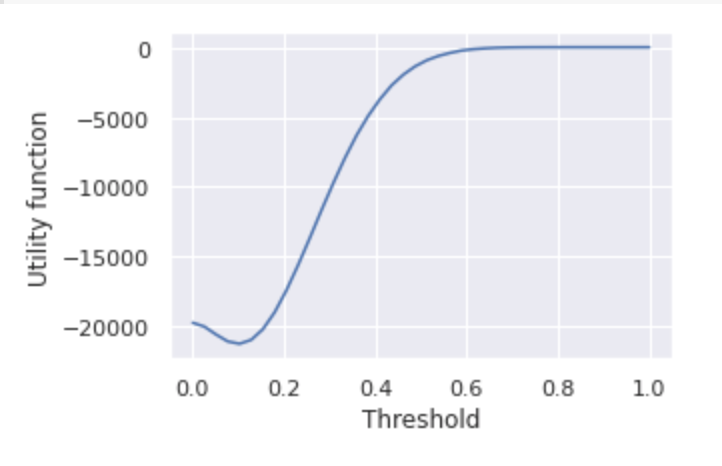
What could I do to minimize this function?
utilityfunction twice. I assume your question is mostly about the second one, right? – Racecourse